
深度學習 -- 神經網路 3
上一講介紹了2層神經網路,下面擴充套件開來,介紹通用L層神經網路
深層神經網路
構建神經網路的幾個重要步驟通過更加直觀的示意圖來表示,如下:
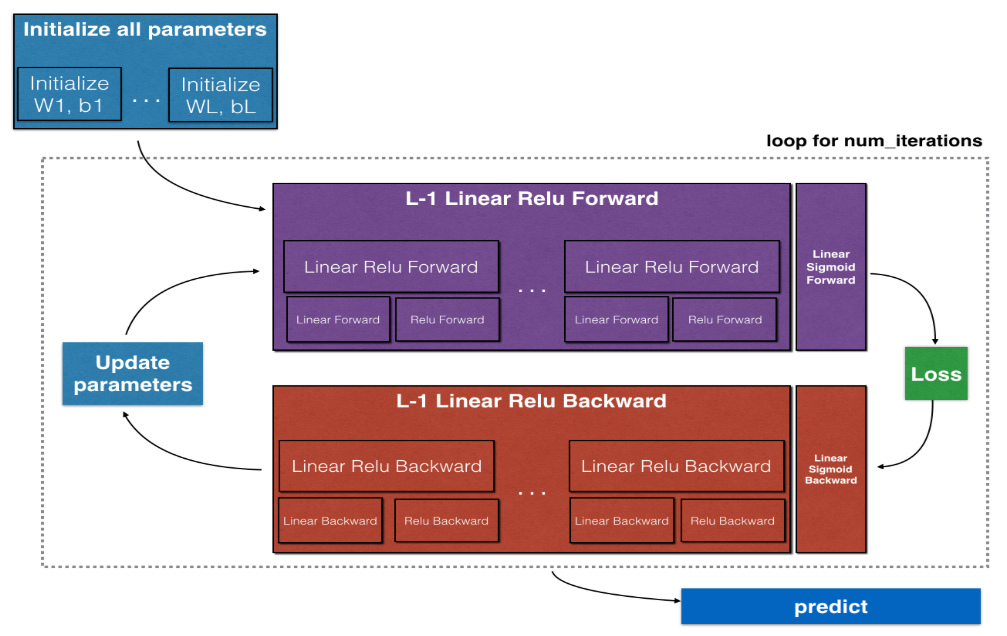
這就是深度神經網路的內部實現原理,通過多次迭代訓練後,最終得到一個模型,然後用此模型進行預測
在實現該網路之前,首先了解下面幾個重要的符號
- Superscript denotes a quantity associated with the layer.
- Example: is the layer activation. and are the layer parameters.
- Superscript denotes a quantity associated with the example.
- Example: is the training example.
- Lowerscript denotes the entry of a vector.
- Example: denotes the entry of the layer’s activations).
1. 網路結構
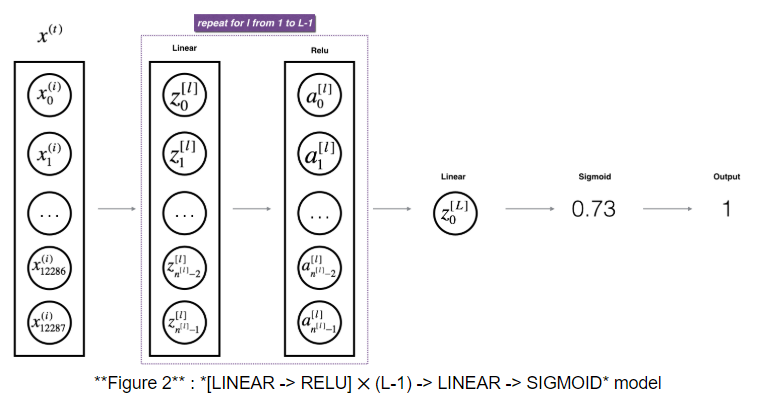
在深度學習 – 神經網路1中,我們的例項是判斷一張圖片是否為貓,當時的準確率為70%,那麼接下來我們繼續以此為例,用多層神經網路來提高它的準確率
輸入層:輸入單元數 = 12288 隱藏層:總層數為L,第層的隱藏單元數為,啟用函式採用ReLU 輸出層:輸出單元數 = 1,啟用函式仍然採用sigmoid
引數維度如下表所示:
| **Layer ** | **Shape of W** | **Shape of b** | **Activation** | **Shape of Activation** |
| **Layer 1** | $(n^{[1]},12288)$ | $(n^{[1]},1)$ | $Z^{[1]} = W^{[1]} X + b^{[1]} $ | $(n^{[1]},209)$ |
| **Layer 2** | $(n^{[2]}, n^{[1]})$ | $(n^{[2]},1)$ | $Z^{[2]} = W^{[2]} A^{[1]} + b^{[2]}$ | $(n^{[2]}, 209)$ |
| $\vdots$ | $\vdots$ | $\vdots$ | $\vdots$ | $\vdots$ |
| **Layer L-1** | $(n^{[L-1]}, n^{[L-2]})$ | $(n^{[L-1]}, 1)$ | $Z^{[L-1]} = W^{[L-1]} A^{[L-2]} + b^{[L-1]}$ | $(n^{[L-1]}, 209)$ |
| **Layer L** | $(n^{[L]}, n^{[L-1]})$ | $(n^{[L]}, 1)$ | $Z^{[L]} = W^{[L]} A^{[L-1]} + b^{[L]}$ | $(n^{[L]}, 209)$ |
2. 實現過程
2.1 初始化引數
 由於現在是L層,每層都有一套引數和,那麼我們就需要一個更加通用的函式,使得它能夠支援不同層數和不同的單元數,而層數和單元數都能夠簡單的通過引數來設定。initialize_parameters_deep(layer_dims),比如layer_dims = [5, 4, 3, 1],那麼就表示該神經網路一共4層(不包括輸入層),每層的單元數分別為5,4,3,1
由於現在是L層,每層都有一套引數和,那麼我們就需要一個更加通用的函式,使得它能夠支援不同層數和不同的單元數,而層數和單元數都能夠簡單的通過引數來設定。initialize_parameters_deep(layer_dims),比如layer_dims = [5, 4, 3, 1],那麼就表示該神經網路一共4層(不包括輸入層),每層的單元數分別為5,4,3,1
關於這些引數初始化為多少合適,這個在後面的課程 改善神經網路 中再詳細介紹,在這裡引數W仍然為標準正態分佈隨機數*0.01,b為0
2.2 前向傳播
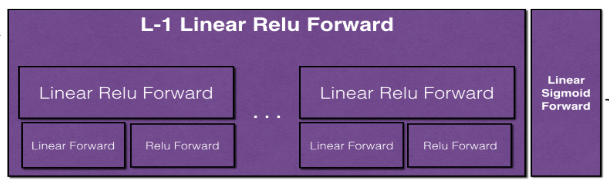 之前講過,一個隱藏單元實現兩個基本功能:線性部分和啟用部分。
之前講過,一個隱藏單元實現兩個基本功能:線性部分和啟用部分。
線性部分很簡單,直接採用下面的公式: 其中,輸入層表示為 該公式適用於神經網路的任何一層和任意數量的樣本。
啟用部分,也就是啟用函式的部分,這裡我們在隱藏層全部採用ReLU,輸出層採用sigmoid。 在這裡啟用函式 “g” 可以是sigmoid()或者relu()。
這裡需要注意的就是在隱藏層,啟用函式都為ReLU,實現上只是一個迴圈即可,但是對於最後一層的輸出層,它不在迴圈中,而是要單獨處理,因為它這裡採用的啟用函式式sigmoid。
2.3 計算cost
在這裡使用的cost函式J是交叉熵: 這裡需要注意的就是在計算時要保持維度正確,對於該例,最終的J應該是一個1 x m的向量
2.4 反向傳播
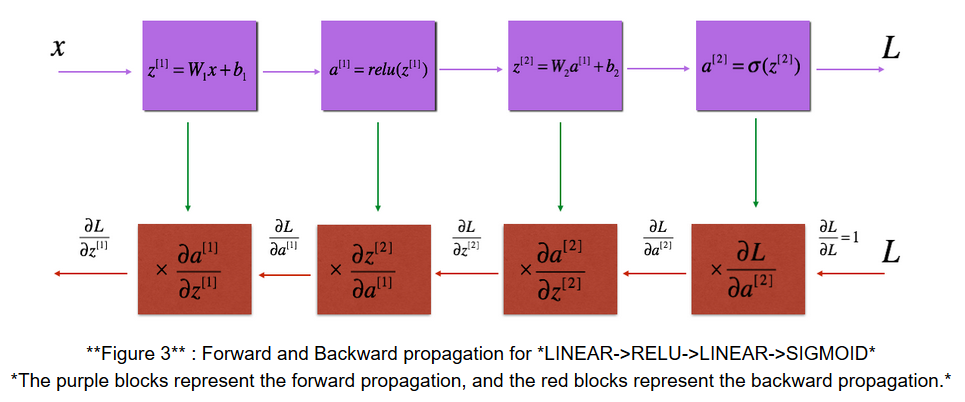
反向傳播的目標就是得到損失函式對於每一層引數W和b的導數–>, 。
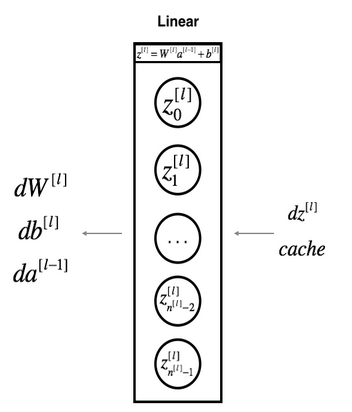
計算過程如下:(通過正向傳播的公式:,可以推匯出第層引數的導數):
注意:和