
強化學習入門總結
目錄
一、強化學習概述
1.強化學習簡介
(1)強化學習是機器學習中的一個領域,強調如何基於環境而行動,以取得最大化的預期利益。其靈感來源於心理學中的行為主義理論,即有機體如何在環境給予的獎勵或懲罰的刺激下,逐步形成對刺激的預期,產生能獲得最大利益的習慣性行為。
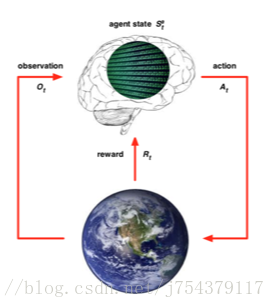
(2)強化學習最早可以追溯到巴甫洛夫的條件反射實驗,它從動物行為研究和優化控制兩個領域獨立發展,最終經Bellman之手將其抽象為馬爾可夫決策過程 (Markov Decision Process
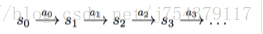
2.發展歷程:
1956年Bellman提出了動態規劃方法。
1977年Werbos提出只適應動態規劃演算法。
1988年sutton提出時間差分演算法。
1992年Watkins 提出Q-learning 演算法。
1994年rummery 提出Saras演算法。
1996年Bersekas提出解決隨機過程中優化控制的神經動態規劃方法。
2006年Kocsis提出了置信上限樹演算法。
2009年kewis提出反饋控制只適應動態規劃演算法。
2014年silver提出確定性策略梯度(Policy Gradients)演算法。
2015年Google-deepmind 提出
可見,強化學習已經發展了幾十年,並不是一門新的技術。在2016年,AlphaGo擊敗李世石之後,融合了深度學習的強化學習技術大放異彩,成為這兩年最火的技術之一。總結來說,強化學習就是一個古老而又時尚的技術。
3.MDP(馬兒可夫決策過程)

S: 表示狀態集(states),有s∈S,si表示第i步的狀態。
A:表示一組動作(actions),有a∈A,ai表示第i步的動作。
?sa: 表示狀態轉移概率。?s? 表示的是在當前s ∈ S狀態下,經過a ∈ A作用後,會轉移到的其他狀態的概率分佈情況。比如,在狀態s下執行動作a,轉移到s'的概率可以表示為
R: S×A⟼ℝ ,R是回報函式(reward function)。有些回報函式狀態S的函式,可以簡化為R: S⟼ℝ。如果一組(s,a)轉移到了下個狀態s',那麼回報函式可記為r(s'|s, a)。如果(s,a)對應的下個狀態s'是唯一的,那麼回報函式也可以記為r(s,a)。
γ:折現因子
4.why RL?
強化學習所解決的問題的特點:
- 智慧體和環境之間不斷進行互動
- 搜尋和試錯
- 延遲獎勵(當前所做的動作可能很多步之後才會產生相應的結果)
目標:
- 獲取更多的累積獎勵
- 獲得更可靠的估計
強化學習 (Reinforcement Learning) 是一個機器學習大家族中的分支, 由於近些年來的技術突破, 和深度學習 (Deep Learning) 的整合, 使得強化學習有了進一步的運用。比如讓計算機學著玩遊戲, AlphaGo 挑戰世界圍棋高手, 都是強化學習在行的事。強化學習也是讓你的程式從對當前環境完全陌生, 成長為一個在環境中游刃有餘的高手。
5.總結:
深度強化學習全稱是 Deep Reinforcement Learning(DRL),其所帶來的推理能力 是智慧的一個關鍵特徵衡量,真正的讓機器有了自我學習、自我思考的能力。
深度強化學習(Deep Reinforcement Learning,DRL)本質上屬於採用神經網路作為值函式估計器的一類方法,其主要優勢在於它能夠利用深度神經網路對狀態特徵進行自動抽取,避免了人工 定義狀態特徵帶來的不準確性,使得Agent能夠在更原始的狀態上進行學習。
二、強化學習求解方法
1.動態規劃方法
基石:貝爾曼方程
(1)貝爾曼方程:
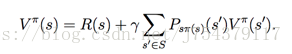
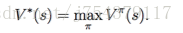
貝爾曼最優方程:
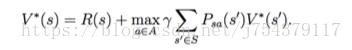
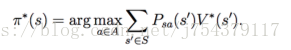
如何求解貝爾曼方程呢?
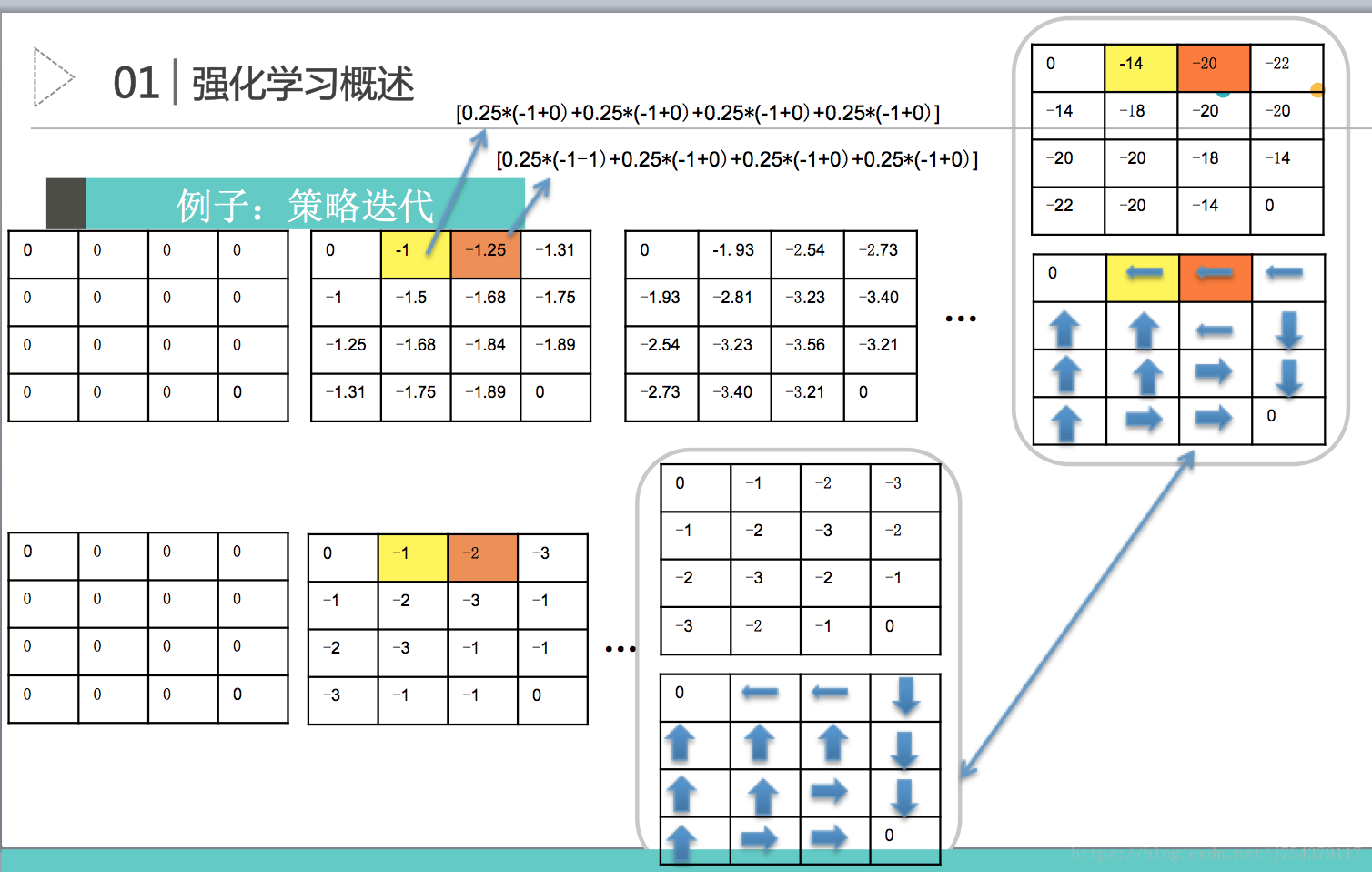
本質上就是個線性規劃問題,多個方程,多個未知數,進行求解,如下,假設每一步的即使獎勵是-0.2,有三個未知狀態V(0,1),V(1,1),V(1,0),損失因子是1,則在如下的策略下,得到的貝爾曼方程如下:
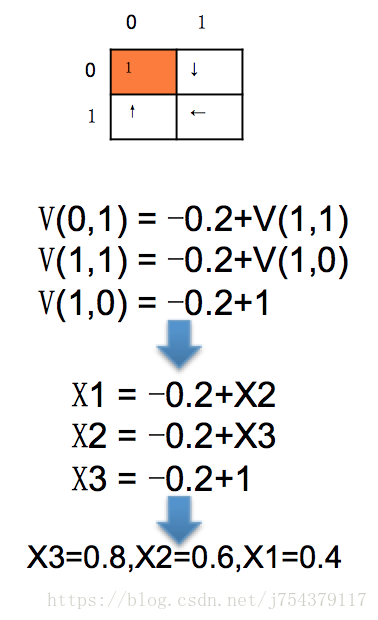
但是當未知變數不斷增大,線性規劃則很難求解,這時需要使用動態規劃進行不斷迭代,讓其狀態值收斂。
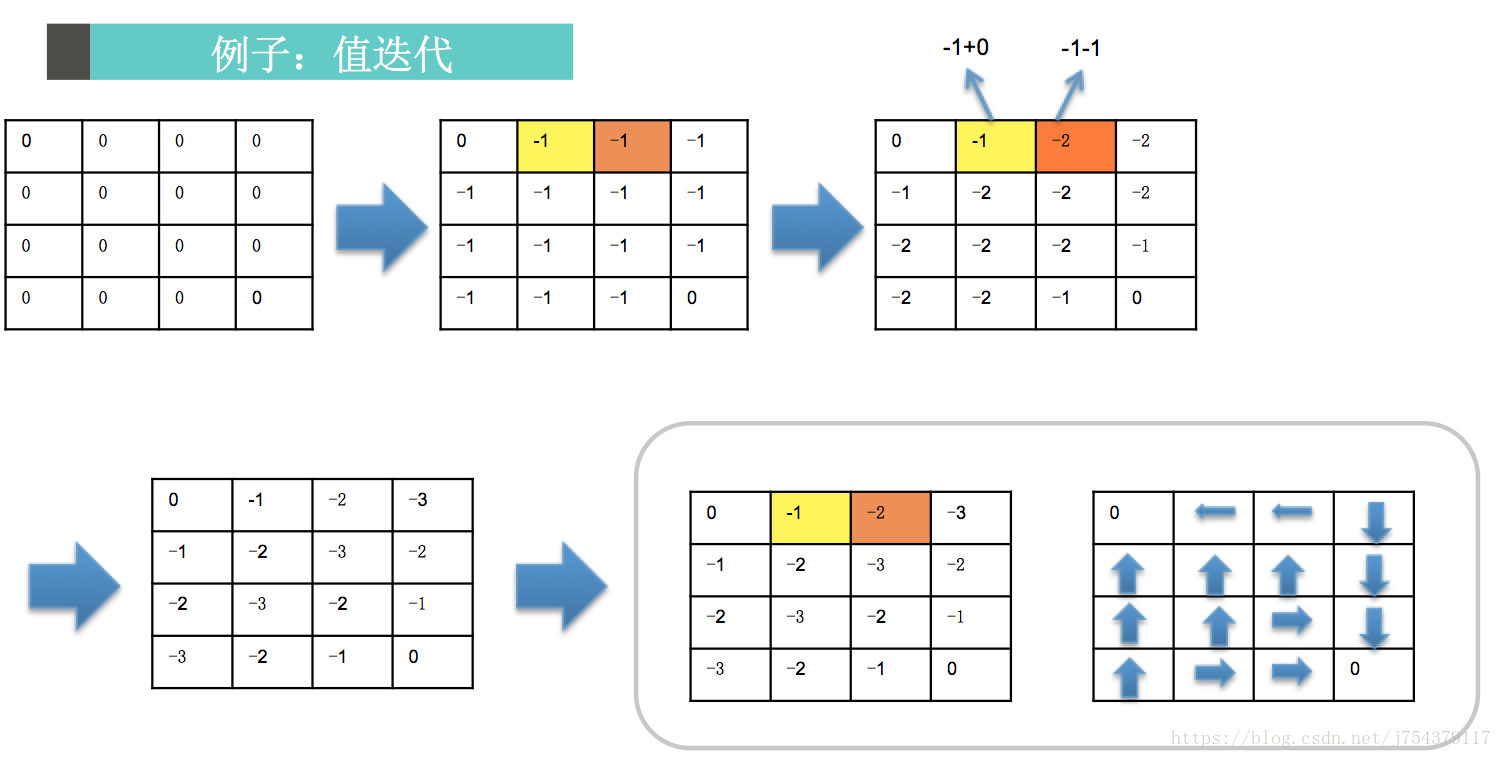
(2)值迭代
In Value Iteration, you start with a randon value function and then find a new (improved) value function in a iterative process, until reaching the optimal value function. Notice that you can derive easily the optimal policy from the optimal value function. This process is based on the Optimality Bellman operator.
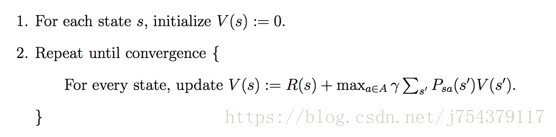
(3)策略迭代
In Policy Iteration algorithms, you start with a random policy, then find the value function of that policy (policy evaluation step), then find an new (improved) policy based on the previous value function, and so on. In this process, each policy is guaranteed to be a strict improvement over the previous one (unless it is already optimal). Given a policy, its value function can be obtained using the Bellman operator.

(4)演算法詳細對比:


- 根據策略迭代演算法,每一次迭代都要進行策略評估和策略提升,直到二者都收斂。可我們的目標是選出最優的策略,那麼有沒有可能在策略評估值沒有收斂的情況下,最優策略已經收斂了呢?答案是有這個可能
- 策略迭代的收斂速度更快一些,在狀態空間較小時,最好選用策略迭代方法。當狀態空間較大時,值迭代的計算量更小一些
(5)GridWorld舉例(分別用策略迭代和值迭代進行求解)

策略迭代過程:
值迭代過程:
2.蒙特卡洛方法
上面的動態規劃方法,是一種較為理想的狀態,即所有的引數都提前知道,比如狀態轉移概率,及獎勵等等。然而顯示情況是未知的,這時候有一種手段是採用蒙特卡洛取樣,基於大數定律,基於統計計算出轉移概率值;比如當你拋硬幣的次數足夠多,那麼正面和反面的概率將會越來越接近真實情況。
3.時間差分方法
基於動態規劃和蒙特卡洛
三、強化學習演算法分類
1.分類一:
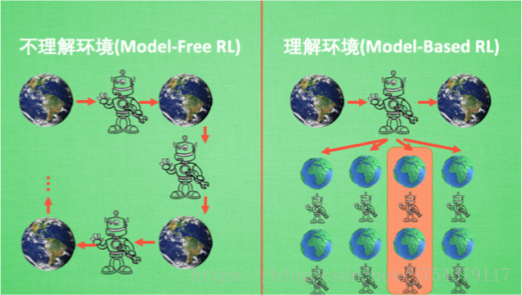
基於理不理解所處環境來進行分類:
Model-free:環境給了我們什麼就是什麼. 我們就把這種方法叫做 model-free, 這裡的 model 就是用模型來表示環境
Model-based:那理解了環境也就是學會了用一個模型來代表環境, 所以這種就是 model-based 方法
2.分類二:
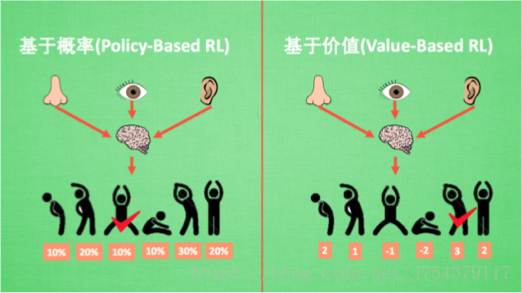
一類是直接輸出各個動作概率,另一個是輸出每個動作的價值;前者適用於連續動作情況,後者無法表示連續動作的價值。
3.分類三:
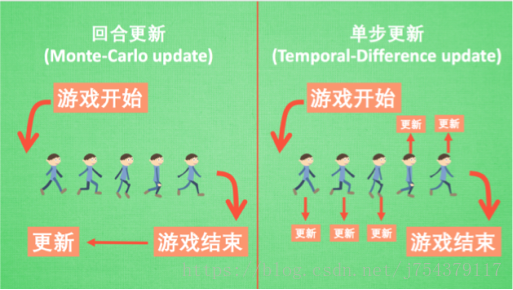
4.分類四:
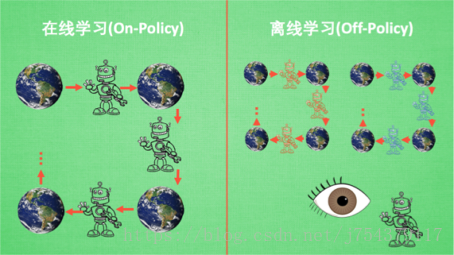
判斷on-policy和off-policy的關鍵在於,你所估計的policy或者value-function和你生成樣本時所採用的policy是不是一樣。如果一樣,那就是on-policy的,否則是off-policy的。
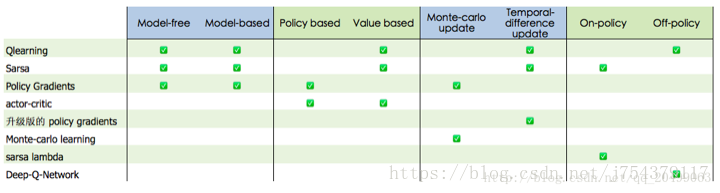
總結各常用演算法的分類:
四、代表性演算法
1.Q-learning
(1)四個基本組成成分:
- Q表:Q(s,a),狀態s下執行動作a的累積價值
- 定義動作:選擇動作
- 環境反饋:做出行為後,環境的反饋
- 環境更新
(2)演算法公式:

(3)演算法決策:

(4)演算法更新:
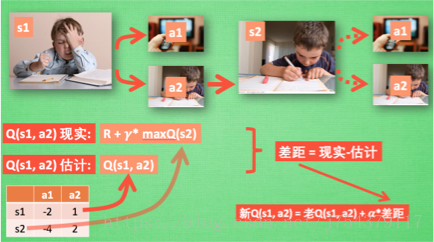
(5)程式碼實現框架:
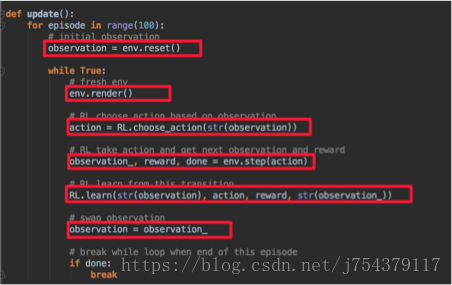
2.Sarsa:
與Q-learning基本類似,唯一的區別是更新方式不一樣
(1)演算法公式:

(2)與Q-learning的區別:Sarsa是on-policy的,Q-learning是off-policy的

(3)更新過程:
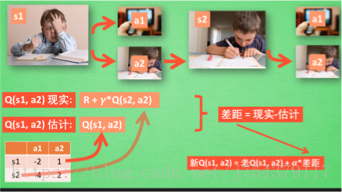
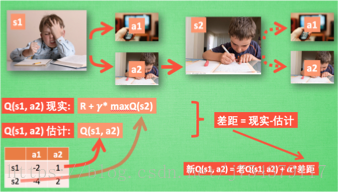
前者是Sarsa,後者是Q-learning
(4)程式碼中展現不同:
Sarsa:
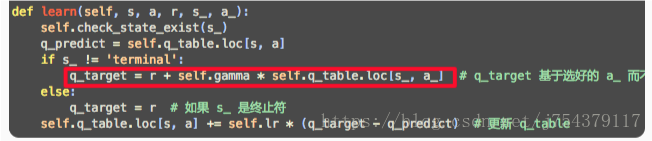
Q-learning:
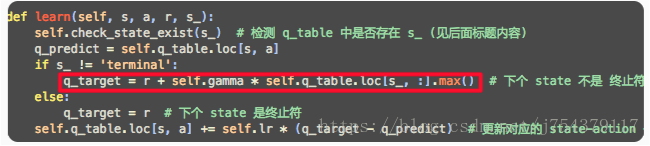
(5)程式碼實現框架:
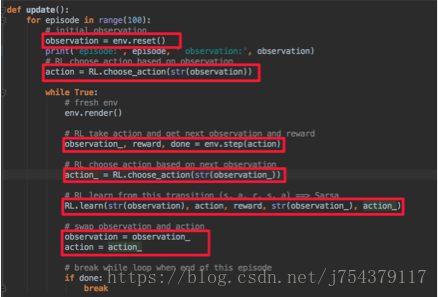
3.大名鼎鼎的DQN
Deepmind就是因為DQN這篇論文,被谷歌收購
(1)由來:
-
DQN(Deep Q Network)是一種融合了神經網路和Q learning的方法.
-
有些問題太複雜,Q表無法儲存,即使可以儲存,搜尋也很麻煩。故而,將Q表用神經網路進行替代。
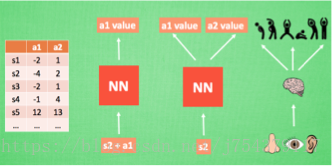
(2)增加了兩個新特性:
Experience replay:每次DQN更新的時候,隨機抽取一些之前的經歷進行學習。隨機抽取這種打亂了經歷之間的相關性,使得神經網路更新更有效率。
Fixed Q-targets:使用兩個結構相同但引數不同的神經網路,預測Q估計的神經網路具備最新的引數,而預測Q現實的神經網路使用的引數則是很久以前的。
(3)演算法公式:

(4)DQN程式碼實現框架:
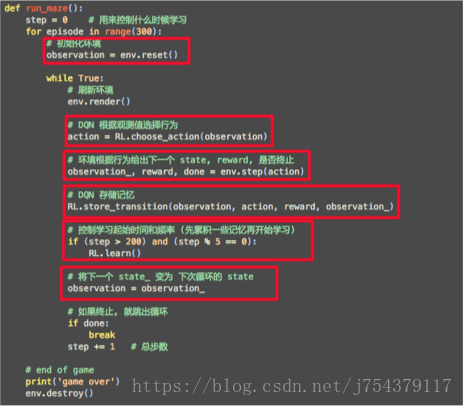
可以看到基本上Q-learning一模一樣,只是有一處不一樣,就是多了儲存記憶,並且批量進行學習。
4.Policy Gradients演算法
(1)由來:
強化學習是一個通過獎懲來學習正確行為的機制. 家族中有很多種不一樣的成員,有學習獎懲值, 根據自己認為的高價值選行為, 比如 Q learning, Deep Q Network, 也有不通過分析獎勵值, 直接輸出行為的方法, 這就是今天要說的 Policy Gradients 了. 甚至我們可以為 Policy Gradients 加上一個神經網路來輸出預測的動作. 對比起以值為基礎的方法, Policy Gradients 直接輸出動作的最大好處就是, 它能在一個連續區間內挑選動作, 而基於值的, 比如 Q-learning, 它如果在無窮多的動作中計算價值, 從而選擇行為, 這, 它可吃不消.

(2)區別:
Q-learning、DQN:學習獎懲值, 根據自己認為的高價值選行為。
Policy Gradients:不通過分析獎勵值, 直接輸出行為的方法。
Policy Gradients 直接輸出動作的最大好處就是, 它能在一個連續區間內挑選動作, 而基於值的, 比如 Q-learning, 它如果在無窮多的動作中計算價值, 從而選擇行為, 這, 它可吃不消.
(3)更新:
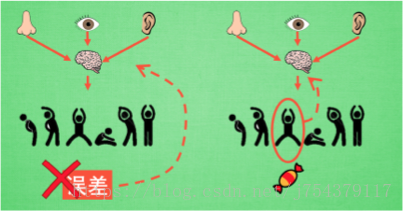
(4)REINFORCE演算法公式:

5.Actor-critic
(1)由來:
結合了 Policy Gradient (Actor) 和 Function Approximation (Critic) 的方法. Actor 基於概率選行為, Critic 基於 Actor 的行為評判行為的得分, Actor 根據 Critic 的評分修改選行為的概率.
(2)特點:
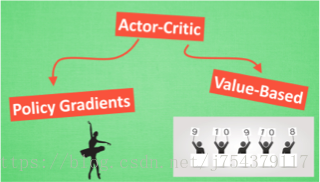
Policy Gradients + Q-learning:既可以在連續動作中取合適的動作,又可以進行單步更新。
(3)與Policy Gradients的區別:
Policy gradient是回合後進行獎懲計算,前期沒有值函式,需要後向推算;
Actor-critic多了一個critic方法,可以用來每一步進行一個好壞判斷;
(4)更新
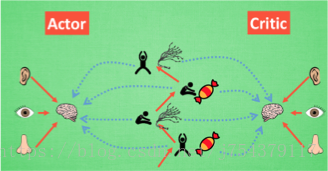
Actor Critic 方法的劣勢: 取決於Critic的價值判斷, 但是 Critic 難收斂, 再加上Actor 的更新, 就更難收斂. 為了解決收斂問題, Google Deepmind 提出了Actor Critic 升級版 Deep Deterministic Policy Gradient. 後者融合了 DQN 的優勢, 解決了收斂難的問題.
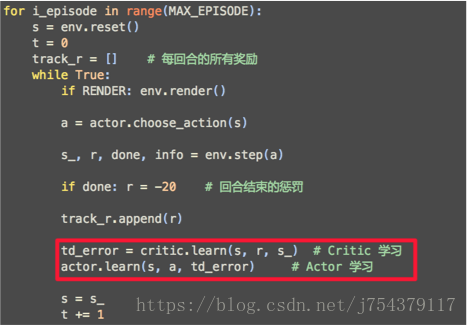
(5)程式碼實現框架:
五、強化學習應用:
(1)各領域應用:
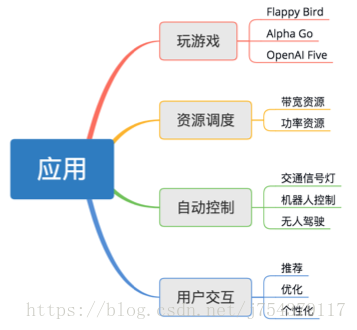
(2)對話
TaskBot-阿里小蜜的任務型問答技術:
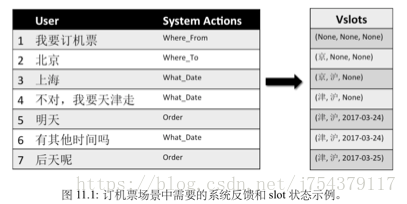
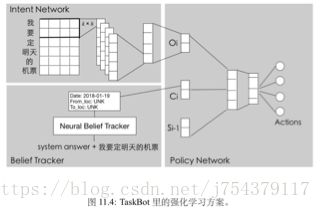
State. 我們主要考慮了 intent network 出來的 user question embeddings,當前抽 取的 slot 狀態,和歷史的 slot 資訊,之後接入一個全連線的神經網路,最後連softmax 到各個 actions。
Action. 在訂機票場景,action 空間是離散的,主要包括對各個 slot 的反問和 Order(下單): 反問時間,反問出發地,反問目的地,和 Order。這裡的 action 空間可以擴充套件,加入一些新的資訊比方詢問說多少個人同行,使用者偏好等。
對比了不同的 DRL 配置下的效果。在測試的時候發現,如果使用者退出會話 (Quit) 給一個比較大的懲罰-1,模型很難學好。這個主要原因 是,使用者退出的原因比較多樣化,有些不是因為系統回覆的不好而退出的,如 果這個時候給比較大的懲罰,會對正確的 actions 有影響。
(3)淘寶電商搜尋:
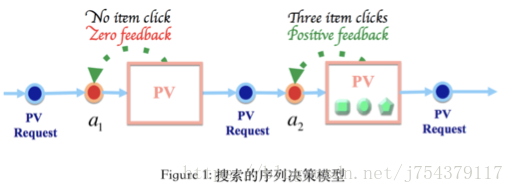
使用者搜尋商品是一個連續的過程。這一連續過程的不同階段之間不是孤立的,而是有著緊密的聯絡。換句話說,使用者最終選擇購買 或不夠買商品,不是由某一次排序所決定,而是一連串搜尋排序的結果。
搜尋引擎(智慧體)、使用者(環境)、使用者行為(reward)
當狀態空間S和動作空間A確定好之後(動作空間即Agent能夠選擇排序策略的 空間),狀態轉移函式T 也隨即確定;
另一個重要的步驟是把我們 要達到的目標(如:提高點選率、提高GMV等)轉化為具體的獎賞函式R
(4)FlappyBird:
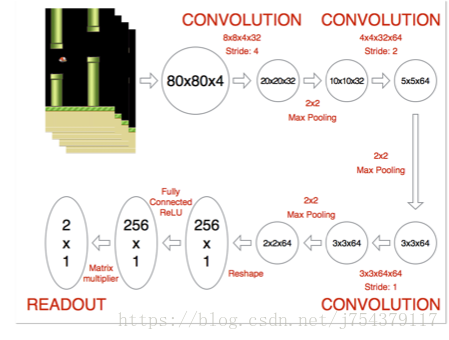
(5)組合優化問題(TSP):
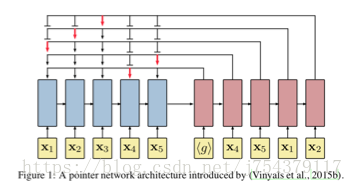

六、總結:
1.如何設計演算法:
Step 1:將實際問題建模成馬爾可夫決策過程,抽象出五元組, 其中reward與實際目標相關聯
Step 2:根據動作是否連續選擇對應的演算法
動作離散:DQN
動作連續:Policy Gradients,Actor-Critic,DDPG
Step 3:根據演算法寫程式碼
參考資料:
1、莫煩強化學習系列教程
2、DQN系列教程
4、2017年ICLR論文:
NEURAL COMBINATORIAL OPTIMIZATION WITH REINFORCEMENT LEARNING
5、sutton《Reinforcement Learning:An Introduction》:
6、Exercises and Solutions to accompany Sutton‘s Book and David Silver’s course:
7、Andrew Ng 機器學習視訊16-20章
8、David Silver視訊
9、Reinforcement Learning Beyond Games:To Make a Difference in Alibaba