
【Linux程序、執行緒、任務排程】二
- Linux程序生命週期(就緒、執行、睡眠、停止、殭屍)
- 殭屍的含義
- 停止狀態與作業控制, cpulimit
- 記憶體洩漏的真實含義
- task_struct以及task_struct之間的關係
- 初見fork和殭屍
本篇接著上一篇文章主要記錄以下學習內容:
- fork vfork clone 的含義
- 寫時拷貝技術
- Linux執行緒的實現本質
- 程序0 和 程序1
- 程序的睡眠和等待佇列
- 孤兒程序的託孤 ,SUBREAPER
1、fork
fork(),建立子程序,實際上就是將父程序的task_struct結構進行一份拷貝(注意拷貝的都是指標),假設有p1程序,fork後產生p2子程序:
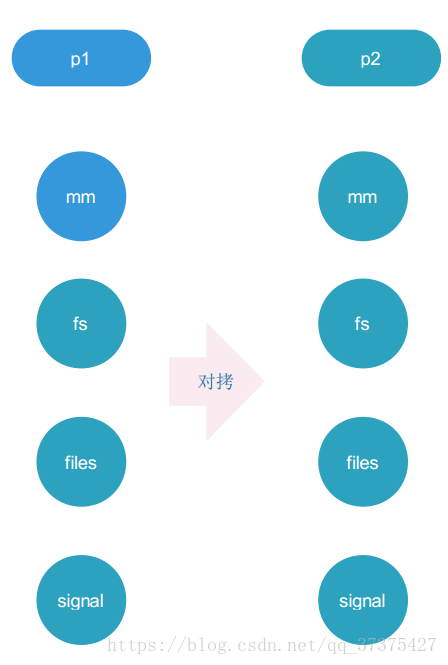
上面的mm ,fs,files,signal等都是task_struct結構體裡的指標,分別指向程序的記憶體資源,檔案系統資源,檔案資源,訊號資源等,當父程序p1 fork後,核心把p1的task_struct拷貝一份,作為子程序p2的描述符。此時p1和p2所指向的資源實際上是一樣的,這並不與程序是佔有獨立的空間矛盾,因為後面對資源進型任何的修改將導致資源分裂,比如當p1(或p2)對fs,files,signal等資源執行操作,將導致fs,files,signal各分裂一份作為p1(或p2)的資源。
其中對於mm(記憶體)的情況,就比較複雜,有一種技術:寫時拷貝(copy on write)
2、寫時拷貝(Copy on write)
看下圖:
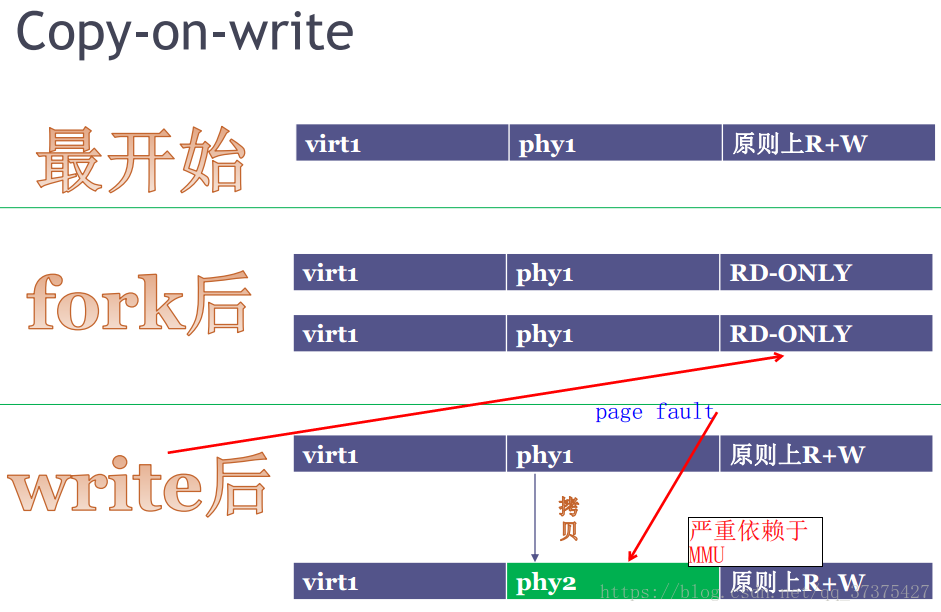
最開始的時候程序p1,假設某一塊的虛擬記憶體為virt1,virt1所對映的實體記憶體為phy1,原則上virt1與phy1是可讀可寫的。當p1呼叫fork()後,產生了新的虛存和實體記憶體表示子程序p2的某一塊地址,實際上此時p1和p2的是指向同樣的實體記憶體地址,並且這塊記憶體變得只讀了 。假設p2(p1)要對這塊記憶體進行寫操作,就會產生page fault,此時就會重新開闢一塊實體記憶體空間,讓p2(p1)的virt1對映到新的實體記憶體phy2,然後重新對phy2的記憶體進行寫操作。
我們注意到,這個過程中,需要有MMU進行地址翻譯,所以寫時拷貝技術必須要有MMU才能實現。
無MMU,不能寫時拷貝,不能fork
- 實驗
#include <sched.h>
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
int data = 10;
int child_process()
{
printf("Child process %d, data %d\n",getpid(),data);
data = 20;
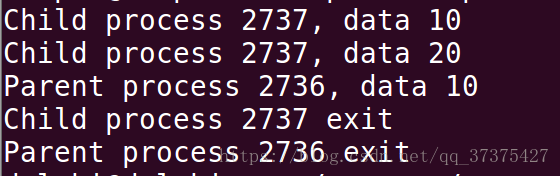
printf("Child process %d, data %d\n" 編譯執行結果:
- 結果分析
以上程式父程序fork後,子程序對全域性變數進行寫,實體記憶體部分進行分裂,使得子程序與父程序data變數對應的實體記憶體部分分離(寫時拷貝)。從此以後父子程序各自讀寫data將不會影響彼此,且父子程序的執行是獨立的,可以同時執行。
3、vfork
那麼如果沒有MMU,該如何呢?vfork在無MMU的場合下使用。
無MMU時只能使用vfork
vfork在以下情況下使用:
父程序阻塞直到子程序:
- exit 或 _exit
- exec
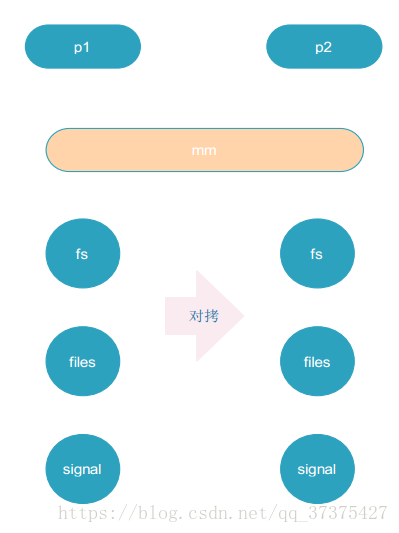
vfork實際上內部是對mm(記憶體資源)進行一個clone,而不是copy,其他資源還是copy(因為其他資源不受MMU影響),見下圖:
- 實驗
#include <sched.h>
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
int data = 10;
int child_process()
{
printf("Child process %d, data %d\n",getpid(),data);
data = 20;
printf("Child process %d, data %d\n",getpid(),data);
sleep(15);
printf("Child process %d exit\n",getpid());
_exit(0);
}
int main(int argc, char* argv[])
{
int pid;
pid = vfork();
if(pid==0) {
child_process();
}
else{
sleep(1);
printf("Parent process %d, data %d\n",getpid(), data);
sleep(20);
printf("Parent process %d exit\n",getpid());
exit(0);
}
}
- 執行結果:
- 結果分析
由結果可以看出vfork與fork的區別:vfork的mm部分,是clone的而非copy的。父程序在子程序exit或者exec之前一直都處於阻塞狀態(可以自己執行下看看sleep效果)。
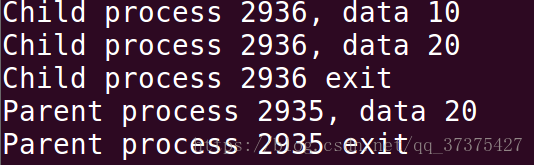
4、Linux執行緒的實現本質
執行緒,共享程序的所有資源!那麼內部是如何實現的呢?
實際上pthread_create內部就是呼叫clone,當程序(執行緒)p1呼叫pthread_create,內部就是呼叫clone,新生成的執行緒p2與原來的執行緒p1共享所有資源。
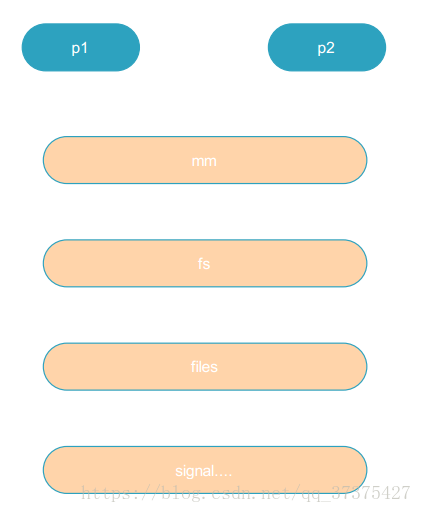
其實,此時可以看成是p1和p2的task_struct結構體內的指向資源的指標是一樣的。多執行緒是共享資源的。
我們可以看到,執行緒p1和p2都是有task_struct的,而且裡面的資源是一樣的,核心的排程器只看task_struct,所以程序,執行緒,都是可以被排程的物件。執行緒也被叫做輕量級程序。
5、PID與TGID
POSIX規定,程序中的多個執行緒getpid()後應該獲得同一個id(主執行緒id(TGID)),但是實際上每一個執行緒都有一個task_struct結構體,這個結構體中存有各個執行緒的id(PID)。
為了解決有兩個id的情況,核心高出了一個TGID,每一個核心的TGID都是相等的,等於主執行緒的id。
假設現在有程序程序p1,它建立了三個子程序:
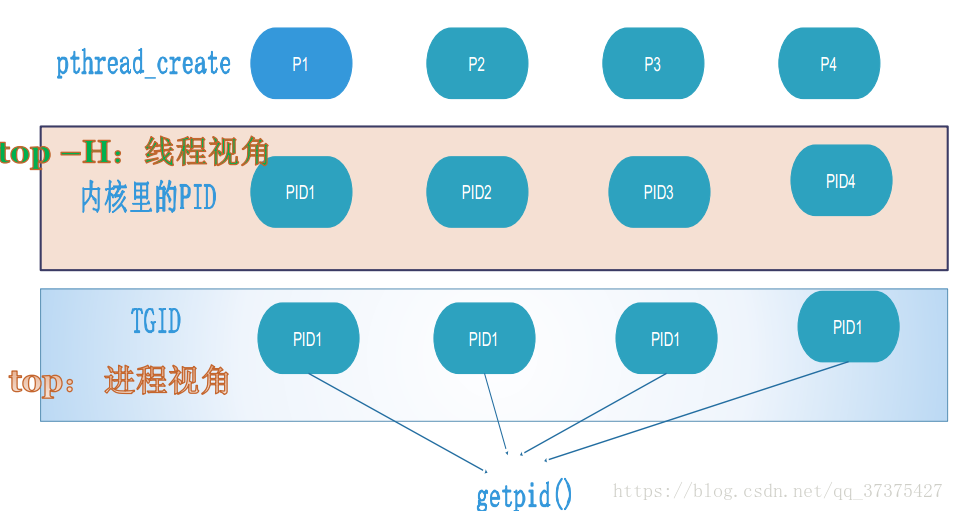
其中:
1、top 檢視的是程序的視角,檢視的id實際上是各個程序(執行緒)的TGID
2、top -H是執行緒視角,檢視的是各個執行緒的自己獨有的id即PID
看以下程式:
#include <stdio.h>
#include <pthread.h>
#include <stdio.h>
#include <linux/unistd.h>
#include <sys/syscall.h>
static pid_t gettid( void )
{
return syscall(__NR_gettid);
}
static void *thread_fun(void *param)
{
printf("thread pid:%d, tid:%d pthread_self:%lu\n", getpid(), gettid(),pthread_self());
while(1);
return NULL;
}
int main(void)
{
pthread_t tid1, tid2;
int ret;
printf("thread pid:%d, tid:%d pthread_self:%lu\n", getpid(), gettid(),pthread_self());
ret = pthread_create(&tid1, NULL, thread_fun, NULL);
if (ret == -1) {
perror("cannot create new thread");
return -1;
}
ret = pthread_create(&tid2, NULL, thread_fun, NULL);
if (ret == -1) {
perror("cannot create new thread");
return -1;
}
if (pthread_join(tid1, NULL) != 0) {
perror("call pthread_join function fail");
return -1;
}
if (pthread_join(tid2, NULL) != 0) {
perror("call pthread_join function fail");
return -1;
}
return 0;
}
- 執行結果:
可以看出此時程式處於死迴圈,getpid獲得的id是一樣的,gettid獲得的是執行緒結構體中的id。所以是不一樣的,而pthread_self 並不是任何id,這裡我們不關心pthread_slef獲得id,我們只關心PID與TGID。

另開一個終端執行命令:
$ top
可得知,只能看到一個thread,實際上就是我們的程序(主執行緒),它的id也是程序的id。top命令只能看到程序的視角,看到的都是程序與程序的id,看不到執行緒與執行緒id
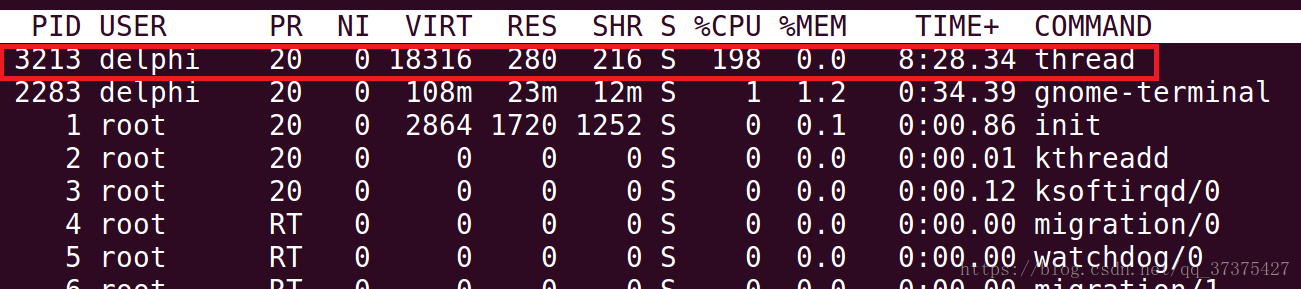
$ top -H

可看到,兩個被創建出來的執行緒thread,且它們的id都是各自的task_struct裡面的id(PID),而不是程序的id(TGID)。top -H 看到的是執行緒視角,顯示的id是執行緒的獨有的id(PID)。這裡id名詞較多,容易弄混,知道原理即可。
6、SUBREAPER與託孤
- 孤兒程序
當父程序死掉,子程序就被稱為孤兒程序
對孤兒程序,有一個問題,就是父程序掛掉了,孤兒程序最後怎門辦,因為沒有人來回收它了。
在Linux中,當父程序掛掉,子程序會在程序樹上向上找subreaper程序,當找到subreaper程序,孤兒程序就會掛到subreaper程序下面成為subreaper程序的子程序,後面就由subreaper程序對該孤兒程序進行回收。如果沒有subreaper程序,那麼最終該孤兒程序會掛到init 1號程序下,由init程序回收。如下圖:
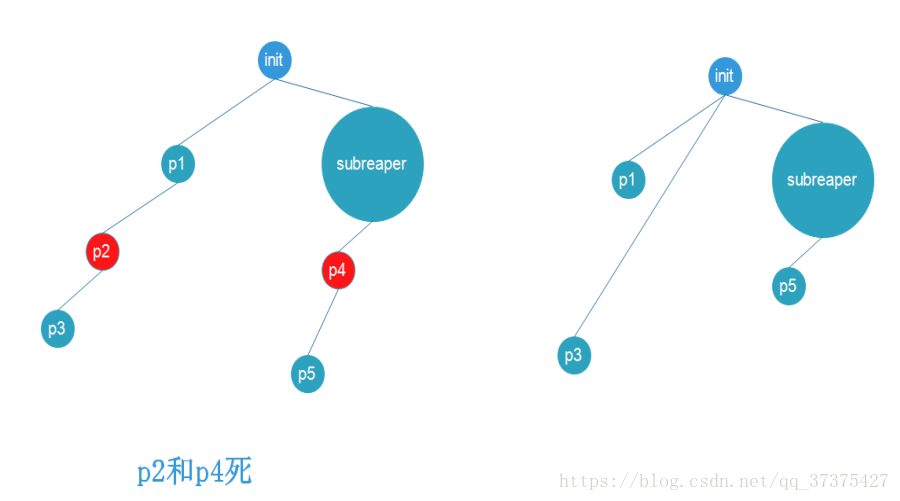
此過程,稱為託孤!
Linux核心中,有一種方法可以將某一程序變為subreaper程序:

prctl函式可以使當前呼叫它的程序變為subreaper程序。
PR_SET_CHILD_SUBREAPER是Linux 3.4引入的新特性,將它設定為非零值,就可以使當前程序變為像1號程序那樣的subreaper程序,可以對孤兒程序進行收養了。
- 實驗
life_period.c
#include <stdio.h>
#include <sys/wait.h>
#include <stdlib.h>
#include <unistd.h>
int main(void)
{
pid_t pid,wait_pid;
int status;
pid = fork();
if (pid==-1) {
perror("Cannot create new process");
exit(1);
} else if (pid==0) {
printf("child process id: %ld\n", (long) getpid());
pause();
_exit(0);
} else {
printf("parent process id: %ld\n", (long) getpid());
wait_pid=waitpid(pid, &status, WUNTRACED | WCONTINUED);
if (wait_pid == -1) {
perror("cannot using waitpid function");
exit(1);
}
if(WIFSIGNALED(status))
printf("child process is killed by signal %d\n", WTERMSIG(status));
exit(0);
}
}
編譯程式執行結果如下:
此時,子程序處於停止狀態,父程序也處於阻塞狀態(waitpid等待子程序結束)。
輸入以下命令檢視當前程序樹,可以看到我們的life_period程序與其子程序在程序樹中的位置:

$ pstree
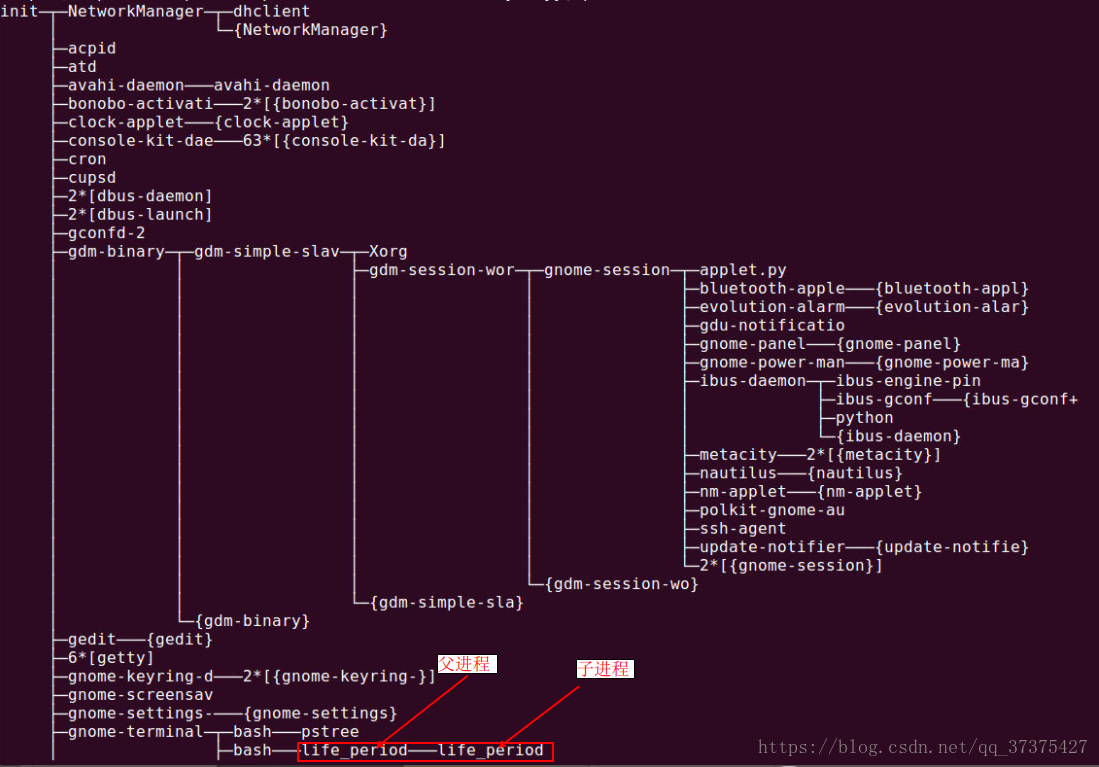
然後,殺死父程序
$ kill -9 3532
再看程序樹:
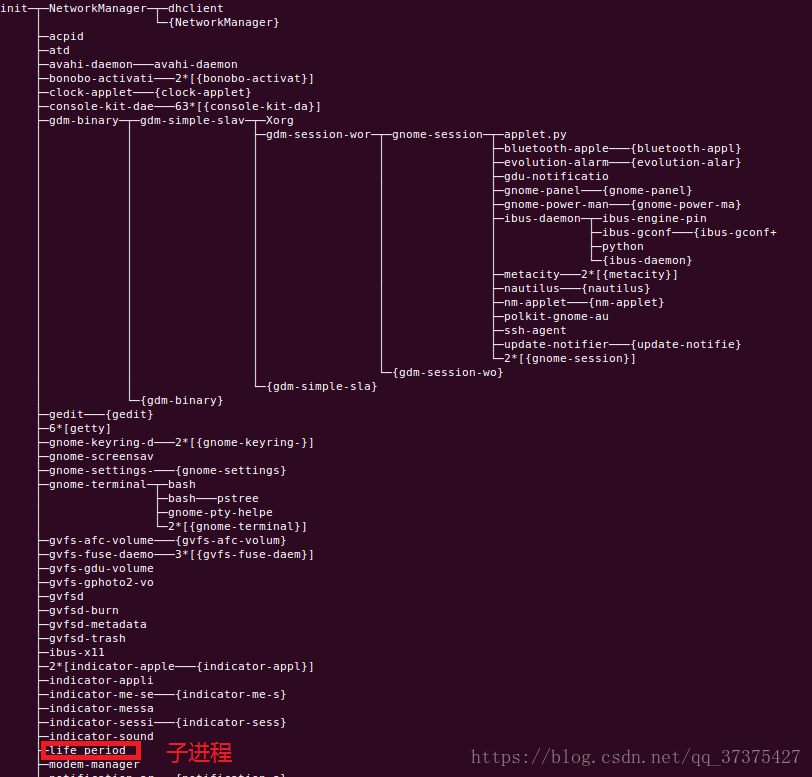
- 結論
可以看到,當我們殺死父程序後,子程序被init程序託孤,以後如果該程序退出了,由init程序回收它的task_struct結構。
7、程序0和程序1
這是一個雞生蛋蛋生雞的故事,我們知道Linux系統中所有的程序都是init程序fork而來,init程序是核心中跑的所有程序的祖先,那麼問題來了,init程序哪裡來的?答案是,init程序是由編譯器編譯而來的?那麼編譯器又是哪裡來的?答案是編譯器是由編譯器編譯而來。那麼編譯編譯器的編譯器又是哪裡來的?
可見,這是一個死迴圈。實際上,最開始,是有一些大牛用0 1寫的編譯器,寫完直接可以在cpu上跑的,然後用最開始的編譯器編譯後面的編譯器。這個不是重點。今天我們的重點是0號程序。0號程序是1號程序父程序。
0號程序也叫IDLE程序。0號程序在什麼時候跑呢?
當所有其他程序,包括init程序都停止運行了,0號程序就會執行。此時0號程序會把CPU置為低功耗,非常省電。
此時核心被置為wait_for_interrupt狀態,除非有一箇中斷過來,才會喚醒其他程序。
8、程序的睡眠和等待佇列
上一篇文章點選連結 簡單講了深度睡眠和淺睡眠。那麼什麼情況下需要將程序置為深度睡眠呢?
假設有程序p,它正在執行,但是整個程式程式碼並沒有完全進入記憶體,假如p呼叫一個函式fun(),這個函式程式碼也沒有進入到記憶體,那麼現在就會出現缺頁(page fault),從而核心需要去執行缺頁處理函式,這個階段程序p就會進入到睡眠狀態,假設進入淺睡眠,那麼有可能會來一個訊號signal1,假設signal1的訊號處理函式也沒有進入到記憶體,這個時候又會出現缺頁錯誤(page fault) 。。。。這樣的話,就有可能導致程式崩潰。
下面看一段程式碼來理解程序的睡眠與排程:
…
…
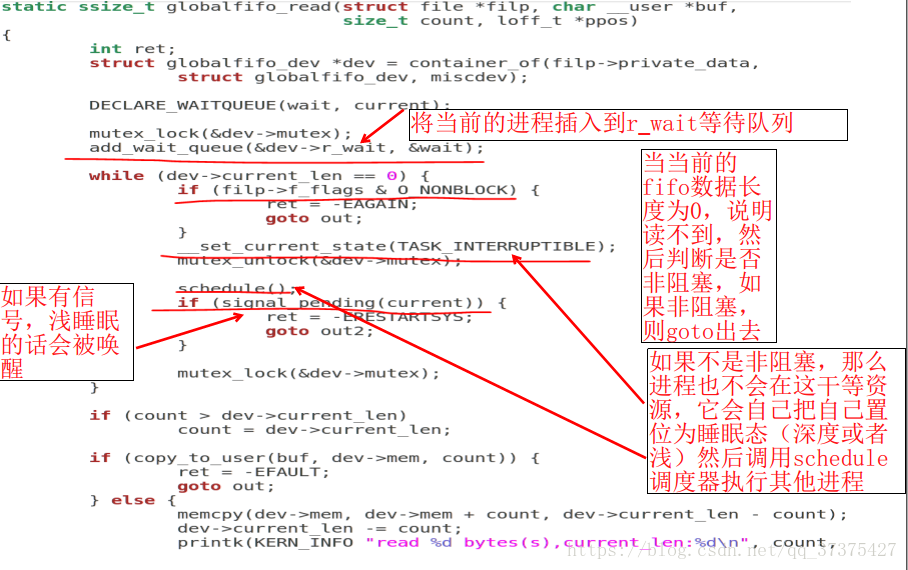

上面程式註解非常的清晰明瞭,我們只需要注意兩點即可:
程序在阻塞讀(或者其他類似於讀的狀態如sleep)時,那個讀的函式內部一定會呼叫核心排程函式schedule(),讓CPU去執行其他的程序。
當有訊號來(或者有資源來)的時候,程序被喚醒,這裡的喚醒,實際上是給等待佇列一個訊號,然後讓佇列自己去喚醒佇列中的程序,並不是去直接喚醒程序的,此時等待佇列可以看做一箇中間機構代替我們去做複雜的喚醒工作。具體是如何實現的,在以後的學習中,還會繼續分析。
9、總結
掌握以下內容
- fork vfork clone的關係
- 寫時拷貝技術與fork,MMU的關係
- Linux執行緒的實現本質,內部是呼叫clone
- 0號程序與1號程序
- 程序的託孤與subreaper程序
- 程序的睡眠與等待佇列