
2018最新實用BAT機器學習演算法崗位系列面試總結(結構化資料特徵工程)
特徵工程,是對原始資料進行一系列工程處理,目的是去除原始資料中的雜質和冗餘,設計更高效的特徵來描述求解的問題與預測模型之間的關係。
特徵工程主要對以下兩種常用的資料型別做處理: (1)結構化資料。結構化資料型別可以看作關係型資料庫的一張表,每列都有清晰的定義,包含了數值型,類別型兩種基本型別;每一行資料表示一個樣本的資訊。 (2)非結構化資料。非結構化資料主要包括文字,影象,音訊,視訊資料,其包含的資訊無法用一個簡單的數值表示,也沒有清晰的類別定義,並且每條資料的大小各不相同。
下面會總結出會被問到幾個方面的特徵工程面試問題。
1. 特徵歸一化 2. 類別型特徵 3. 高維組合特徵的處理 4. 組合特徵 5. 文字表示模型 6. Word2Vec 7. 影象資料不足時的處理方法
1)特徵歸一化
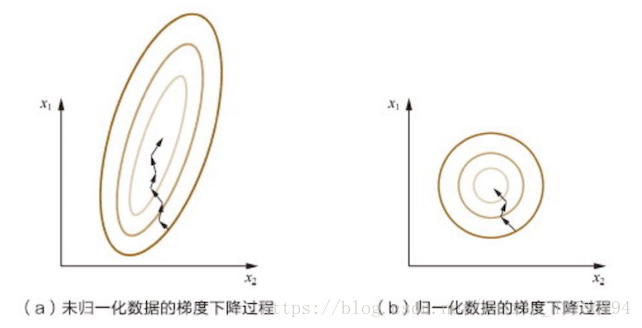
為了消除資料特徵之間的量綱影響,我們需要對特徵進行歸一化處理,使得不同指標之間有可比性。比如身高和體重特徵分別使用不同的單位,米和千克,數值範圍也不一樣,身高是1.6-1.8米範圍,體重是50-100千克,範圍相差很大。所以要對特徵進行歸一化處理,使得各變數處於同一個數值量級,以便更好的分析。
面試問題:為什麼要對數值型別的特徵做歸一化? 分析與解答: 對數值型別的特徵做歸一化可以將所有的特徵都統一到一個大致相同的數值區間內。最常用的方法主要有以下兩種: (1)線性函式歸一化(min-max scaling).它對原始資料進行線性變換,使結果對映到[0,1]的範圍內,實現對原始資料的等比縮放。歸一化公式如下:
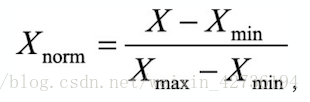
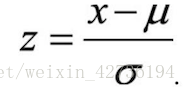
2)類別型特徵 類別型特徵主要是指性別,血型等只有在有限選項內取值的特徵。類別型特徵原始輸入通常是字串形式,除了決策樹等少數模型能直接處理字串形式的輸入,對於邏輯迴歸,支援向量機等模型來說,類別型特徵必須是經過處理轉換成數值型特徵才能正確工作。 考察點:序號編碼,獨熱編碼。
面試問題:在對資料進行預處理時,應該怎樣處理類別型特徵? 分析與解答: 主要可以通過以下兩種方法處理。
- 序號編碼。序號編碼通常用於處理類別間具有大小關係的資料。例如成績,可以分為低,中,高三檔,並且存在“高>中>低”的排序關係。序號編碼會按照大小關係對類別型特徵賦予一個數值ID,例如高表示為3,中為2,低為1,轉換後依然保留了大小關係。
- 獨熱編碼。獨熱編碼通常用於處理類別間不具有大小關係的特徵。例如血型,一共有4個取值(A,B,AB,O型血),獨熱編碼會把血型變成一個4維稀疏向量,A表示(1,0,0,0),B為(0,1,0,0),AB為(0,0,1,0),O為(0,0,0,1)。對於類別較多的情況下使用獨熱編碼需要注意以下問題。(1)使用稀疏向量來節省空間。在獨熱編碼下,特徵向量只有某一維取值為1,其他位置為0。因此可以利用向量的稀疏性表示有效地節省空間,並且目前大部分演算法均接受稀疏向量形式的輸入。(2)配合特徵選擇來降低維度。高維度特徵帶來幾方面的問題。一是在K近鄰演算法中,高維空間下兩點之間的距離很難得到有效的衡量;二是在邏輯迴歸中,引數的數量會隨維度的增高而增高,容易引起過擬合問題;三是通常只有部分維度是對分類和預測有幫助,因此可以考慮配合特徵選擇來降低維度。
3)高維度組合特徵處理
面試問題:什麼是組合特徵?如何處理高維組合特徵?
分析與解答:
為了提高複雜關係的擬合能力,在特徵工程中經常會把一階離散特徵兩兩組合,構成高階組合特徵。以廣告點選預估問題為例,表1.2是語言和型別對點選的影響。為了提高擬合能力,語言和型別可以組成二階特徵,表1.3是語言和型別的組合特徵對點選的影響。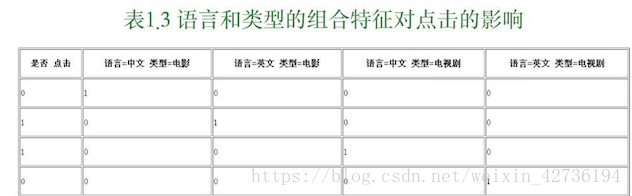

4)組合特徵
面試問題:如何有效地找到組合特徵?
分析與解答:
在做組合特徵的時候,如果只是簡單的進行兩兩組合,很容易導致引數過多、多擬合等問題,而且並不是所有的特徵組合都有意義。這裡就先介紹一種基於決策樹的特徵組合尋找方法。以點選預測問題為例,假設原始輸入特徵包含年齡,性別,使用者型別(試用期,付費),物品型別(護膚,食品等)4個方面的資訊,並且根據原始輸入和標籤(點選/未點選) 構造出了決策樹,如圖1.2.
於是,每一條從根節點到葉節點的路徑都可以看成一種特徵組合的方式。具體來說,就有以下4中特徵組合方式:(1)年齡<=35 且性別是女 (2)年齡<35且物品是護膚 (3)使用者是付費且物品是護膚 (4)使用者是付費且年齡<=40
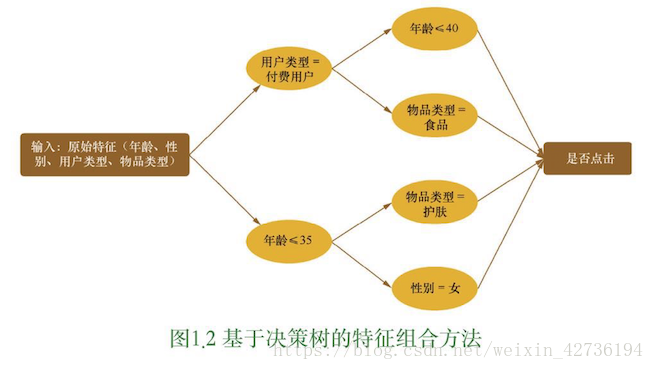
這樣就可以生成不同的組合特徵。
下一篇會寫如何對非結構化資料進行特徵工程