
CS231n——機器學習演算法——線性分類(下:Softmax及其損失函式)
1. Softmax分類器
SVM和Softmax分類器是最常用的兩個分類器,Softmax的損失函式與SVM的損失函式不同。對於學習過二元邏輯迴歸分類器的讀者來說,Softmax分類器就可以理解為邏輯迴歸分類器面對多個分類的一般化歸納。
SVM將輸出 作為每個分類的評分(因為無定標,所以難以直接解釋)。與SVM不同,Softmax的輸出(歸一化的分類概率)更加直觀,並且從概率上可以解釋,這一點後文會討論。
在Softmax分類器中,函式對映
保持不變,但將這些評分值視為每個分類的未歸一化的對數概率,並且將折葉損失(hinge loss)替換為交叉熵損失(cross-entropy loss)。 公式如下:
或等價為
在上式中,使用
來表示分類評分向量
中的第j個元素。和之前一樣,整個資料集的損失值是資料集中所有樣本資料的損失值
的均值與正則化損失R(W)之和。
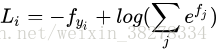
其中函式 被稱作softmax 函式:
- 其輸入值是一個向量,向量中元素為任意實數的評分值(z中的),函式對其進行壓縮,輸出一個向量,其中每個元素值在0到1之間,且所有元素之和為1。所以,包含softmax函式的完整交叉熵損失看起唬人,實際上還是比較容易理解的。
資訊理論視角:
在“真實”分佈p和估計分佈q之間的交叉熵定義如下:
因此,Softmax分類器所做的就是最小化在估計分類概率(就是上面的
)和“真實”分佈之間的交叉熵,在這個解釋中, “真實”分佈就是所有概率密度都分佈在正確的類別上(比如:p=[0,…1,…,0]中在
的位置就有一個單獨的1)。
還有,既然交叉熵可以寫成熵和相對熵(Kullback-Leibler divergence)
,並且delta函式p的熵是0,那麼就能等價的看做是對兩個分佈之間的相對熵做最小化操作。換句話說,交叉熵損失函式“想要”預測分佈的所有概率密度都在正確分類上。
注:Kullback-Leibler差異(Kullback-Leibler Divergence)也叫做相對熵(Relative Entropy),它衡量的是相同事件空間裡的兩個概率分佈的差異情況。
概率論解釋:
先看下面的公式:
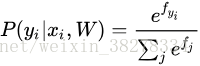
可以解釋為是給定影象資料 ,以 為引數,分配給正確分類標籤 的歸一化概率。為了理解這點,請回憶一下Softmax分類器將輸出向量 中的評分值解釋為沒有歸一化的對數概率。 那麼以這些數值做指數函式的冪就得到了沒有歸一化的概率,而除法操作則對資料進行了歸一化處理,使得這些概率的和為1。從概率論的角度來理解,我們就是在最小化正確分類的負對數概率,這可以看做是在進行最大似然估計(MLE)。 該解釋的另一個好處是,損失函式中的正則化部分R(W)可以被看做是權重矩陣W的高斯先驗,這裡進行的是最大後驗估計(MAP)而不是最大似然估計。提及這些解釋只是為了讓讀者形成直觀的印象,具體細節就超過本課程範圍了。
2. 實操注意事項
數值穩定
程式設計實現softmax函式計算的時候,中間項
因為存在指數函式,所以數值可能非常大。除以大數值可能導致數值計算的不穩定,所以學會使用歸一化技巧非常重要。如果在分式的分子和分母都乘以一個常數C,並把它變換到求和之中,就能得到一個從數學上等價的公式:
C的值可自由選擇,不會影響計算結果,通過使用這個技巧可以提高計算中的數值穩定性。通常將C設為
。該技巧簡單地說,就是應該將向量
中的數值進行平移,使得最大值為0。程式碼實現如下:

f = np.array([123, 456, 789]) # 例子中有3個分類,每個評分的數值都很大
p = np.exp(f) / np.sum(np.exp(f)) # 不妙:數值問題,可能導致數值爆炸
# 那麼將f中的值平移到最大值為0:
f -= np.max(f) # f becomes [-666, -333, 0]
p = np.exp(f) / np.sum(np.exp(f)) # 現在OK了,將給出正確結果
讓人迷惑的命名規則
- 精確地說,SVM分類器使用的是折葉損失(hinge loss),有時候又被稱為最大邊界損失(max-margin loss)。
- Softmax分類器使用的是交叉熵損失(corss-entropy loss)。Softmax分類器的命名是從softmax函式那裡得來的,softmax函式將原始分類評分變成正的歸一化數值,所有數值和為1,這樣處理後交叉熵損失才能應用。
注意,從技術上說“softmax損失(softmax loss)”是沒有意義的,因為softmax只是一個壓縮數值i的函式y。但是在這個說法常常被用來做簡稱。
3. SVM和Softmax的比較
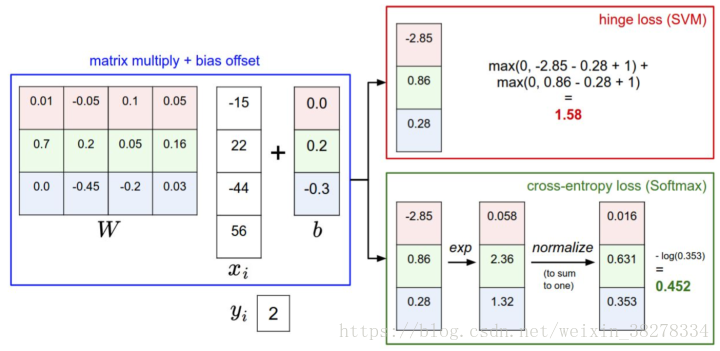
針對一個數據點,SVM和Softmax分類器的不同處理方式的例子。
兩個分類器都計算了同樣的分值向量 (本節中是通過矩陣乘來實現)。不同之處在於對 中分值的解釋:
-
SVM分類器將它們看做是分類評分,它的損失函式鼓勵正確的分類(本例中是藍色的類別2)的分值比其他分類的分值高出至少一個邊界值。
Softmax分類器將這些數值看做是每個分類沒有歸一化的對數概率,鼓勵正確分類的歸一化的對數概率變高,其餘的變低。 -
SVM的最終的損失值是1.58,Softmax的最終的損失值是0.452,但要注意這兩個數值沒有可比性。只在給定同樣資料,在同樣的分類器的損失值計算中,它們才有意義。
-
Softmax分類器為每個分類提供了“可能性”:SVM的計算是無標定的,而且難以針對所有分類的評分值給出直觀解釋。Softmax分類器則不同,它允許我們計算出對於所有分類標籤的可能性。
舉個例子
針對給出的影象,SVM分類器可能給你的是一個[12.5, 0.6, -23.0]對應分類“貓”,“狗”,“船”,而softmax分類器可以計算出這三個標籤的”可能性“是[0.9, 0.09, 0.01],這就讓你能看出對於不同分類準確性的把握。
為什麼我們要在”可能性“上面打引號呢?這是因為可能性分佈的集中或離散程度是由正則化引數λ直接決定的,λ是你能直接控制的一個輸入引數。
舉個例子
假設3個分類的原始分數是[1, -2, 0],那麼softmax函式就會計算:
現在,如果正則化引數λ更大,那麼權重W就會被懲罰的更多,然後他的權重數值就會更小。這樣算出來的分數也會更小,假設小了一半吧[0.5, -1, 0],那麼softmax函式的計算就是:
現在看起來,概率的分佈就更加分散了。還有,隨著正則化引數λ不斷增強,權重數值會越來越小,最後輸出的概率會接近於均勻分佈。這就是說,softmax分類器算出來的概率最好是看成一種對於分類正確性的自信。和SVM一樣,數字間相互比較得出的大小順序是可以解釋的,但其絕對值則難以直觀解釋。
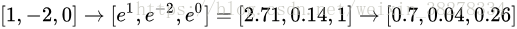
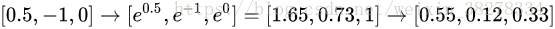
在實際使用中
SVM和Softmax經常是相似的:通常說來,兩種分類器的表現差別很小,不同的人對於哪個分類器更好有不同的看法。
-
相對於Softmax分類器,SVM更加“區域性目標化(local objective)”,這既可以看做是一個特性,也可以看做是一個劣勢。
考慮一個評分是[10, -2, 3]的資料,其中第一個分類是正確的。那麼一個SVM( )會看到正確分類相較於不正確分類,已經得到了比邊界值還要高的分數,它就會認為損失值是0。SVM對於數字個體的細節是不關心的:如果分數是[10, -100, -100]或者[10, 9, 9],對於SVM來說沒設麼不同,只要滿足超過邊界值等於1,那麼損失值就等於0。 -
對於softmax分類器,情況則不同。對於[10, 9, 9]來說,計算出的損失值就遠遠高於[10, -100, -100]的。換句話來說,softmax分類器對於分數是永遠不會滿意的:正確分類總能得到更高的可能性,錯誤分類總能得到更低的可能性,損失值總是能夠更小。但是,SVM只要邊界值被滿足了就滿意了,不會超過限制去細微地操作具體分數。這可以被看做是SVM的一種特性。
舉例說來,一個汽車的分類器應該把他的大量精力放在如何分辨小轎車和大卡車上,而不應該糾結於如何與青蛙進行區分,因為區分青蛙得到的評分已經足夠低了。
4. 小結
- 定義了從影象畫素對映到不同類別的分類評分的評分函式。在本節中,評分函式是一個基於權重W和偏差b的線性函式。
- 與kNN分類器不同,引數方法的優勢在於一旦通過訓練學習到了引數,就可以將訓練資料丟棄了。同時該方法對於新的測試資料的預測非常快,因為只需要與權重W進行一個矩陣乘法運算。
- 介紹了偏差技巧,讓我們能夠將偏差向量和權重矩陣合二為一,然後就可以只跟蹤一個矩陣。
- 定義了損失函式(介紹了SVM和Softmax線性分類器最常用的2個損失函式)。損失函式能夠衡量給出的引數集與訓練集資料真實類別情況之間的一致性。在損失函式的定義中可以看到,對訓練集資料做出良好預測與得到一個足夠低的損失值這兩件事是等價的。
現在我們知道了如何基於引數,將資料集中的影象對映成為分類的評分,也知道了兩種不同的損失函式,它們都能用來衡量演算法分類預測的質量。但是,如何高效地得到能夠使損失值最小的引數呢?這個求得最優引數的過程被稱為最優化,下篇筆記繼續。