caffe原始碼閱讀--ProtoBuffer的研讀
一.什麼是protobuf? protobuf全稱Google Protocol Buffers,是google開發的的一套用於資料儲存,網路通訊時用於協議編解碼的工具庫。它和XML或者JSON差不多,也就是把某種資料結構的資訊,以某種格式(XML,JSON)儲存起來,protobuf與XML和JSON不同在於,protobuf是基於二進位制的。主要用於資料儲存、傳輸協議格式等場合。那既然有了XML等工具,為什麼還要開發protobuf呢?主要是因為效能,包括時間開銷和空間開銷:
1.時間開銷:XML格式化(序列化)和XML解析(反序列化)的時間開銷是很大的,在很多時間效能上要求很高的場合,你能做的就是看著XML乾瞪眼了。
2.空間開銷:熟悉XML語法的同學應該知道,XML格式為了有較好的可讀性,引入了一些冗餘的文字資訊。所以空間開銷也不是太好(應該說是很差,通常需要實際內容好幾倍的空間)。
據實驗(當然不是我實驗),一條訊息資料,用protobuf序列化後的大小是json格式的十分之一,xml格式的二十分之一。
這一篇主要講protobuf用作資料儲存方面,下一篇講用作rpc通訊協議方面。
二.使用protobuf 注:我只會講語言特性,至於環境配置之類的,請大家http://blog.csdn.net/majianfei1023/article/details/45371743。
protobuf的使用很簡單,開發人員按照一定的語法定義結構化的訊息格式,然後用自帶的編譯工具,工具將自動生成相關的類,官方支援java、c++、python語言環境(當然可以在網上找到很多支援其他語言的封裝,當然你也可以自己寫一個,只要符合google定義的格式)。通過將這些類包含在專案中,可以很輕鬆的呼叫相關方法來完成業務訊息的序列化與反序列化工作。
1.定義報文格式。protobuf檔案的字尾是proto,是一種類似c++或者java的語法。使用protoc.exe(windows平臺下,你可以下載原始碼編譯,也可以網上直接下載exe,這個大家自行Google)把proto檔案編譯成c++,java或者Python就可以使用了。
package tutorial;
message Person {
required string name = 1;
required int32 age = 2;
optional string email = 3;
}
在這裡定義了一個Person,我們只是簡單的定義了name,age和email。這裡注意,在上例中,package 名字叫做 tutorial,相當於c++的namespace,定義了一個訊息 Person,該訊息有3個成員,型別為 string 的 name,型別為 int32 的成員 age和型別為string的email。optional 代表這是一個可選的成員,即訊息中可以不包含該成員,required代表是必須的。
寫好proto之後把proto放在protoc.exe相同目錄,然後在此目錄使用指令:protoc --cpp_out=d:\proto person.proto(我們使用的是c++)。當用protocolbuffer編譯器來執行.proto檔案時,編譯器將生成所選擇語言的程式碼,這些程式碼可以操作在.proto檔案中定義的訊息型別,包括獲取、設定欄位值,將訊息序列化到一個輸出流中,以及從一個輸入流中解析訊息。
就可以生成person.pb.h,person.pb.cc.在生成的標頭檔案中,定義了一個 C++ 類 Person,繼承自google::protobuf::Message,後面我們進行對Person資料的檔案讀寫, 將使用這個類來對訊息進行操作。諸如對訊息的成員進行賦值,將訊息序列化等等都有相應的方法。
首先,把資料寫入disk:
#include <iostream>
#include<fstream>
#include "person.pb.h"
#pragma comment(lib, "libprotobuf.lib")
#pragma comment(lib, "libprotoc.lib")
using namespace std;
using namespace tutorial;
int main()
{
Person person;
person.set_name("flamingo");
person.set_age(18);
person.set_email("[email protected]");
// Write
fstream output("./log", ios::out | ios::trunc | ios::binary);
if (!person.SerializeToOstream(&output)) {
cerr << "Failed to write msg." << endl;
return -1;
}
system("pause");
return 0;
}
namespace tutorial就是我們之前定義的package,我們先定義一個Person,然後給Person賦值,其中set_name,set_age,set_email是根據proto自動生成的,我們使用SerializeToOstream 將物件序列化成二進位制(導致了可讀性差的問題,這算是protobuf的一個缺點吧)後寫入一個 fstream 流。
然後在從disk讀出Person的資料:
#include <iostream>
#include<fstream>
#include "person.pb.h"
#pragma comment(lib, "libprotobuf.lib")
#pragma comment(lib, "libprotoc.lib")
using namespace std;
using namespace tutorial;
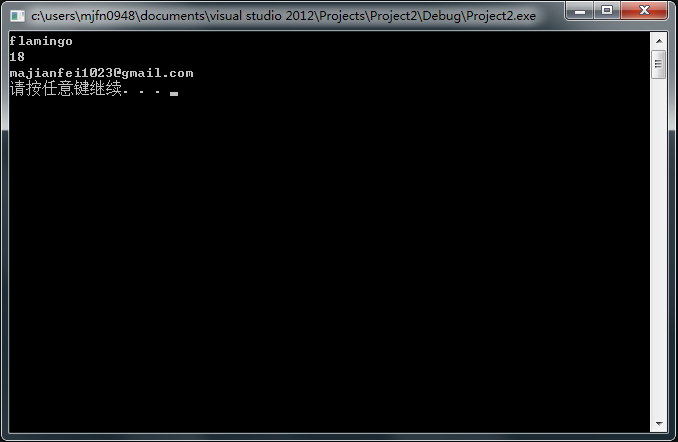
void PrintInfo(const Person & person) {
cout << person.name() << endl;
cout << person.age() << endl;
cout << person.email() << endl;
}
int main()
{
Person person;
fstream input("./log", ios::in | ios::binary);
if (!person.ParseFromIstream(&input)) {
cerr << "Failed to parse address book." << endl;
return -1;
}
PrintInfo(person);
system("pause");
return 0;
}
主要是利用 ParseFromIstream 從一個 fstream 流中讀取序列化的資訊並反序列化。