
機器學習總結之----2.邏輯迴歸
阿新 • • 發佈:2018-12-15
我也只是在學習的過程中,相當於自己理解推導一遍做個筆記,參考了別人很多東西,文末有相關連結。
什麼是邏輯迴歸
邏輯迴歸也叫做對數機率迴歸,但它卻用來做二分類。 線性迴歸產生的預測值為 ,線性迴歸通常用來做迴歸。但是可以線上性迴歸基礎上,加上性質像階躍函式但光滑可導的sigmod函式,然後算出一個概率來。如果大於0.5,可以將它判定為一類(比如正例1),小於等於0.5判定為另一類(比如負例0)。
其中,sigmod函式(簡寫為)為:
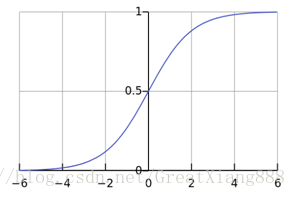
邏輯迴歸,在我看來就是線進行線性迴歸,再在它的基礎上加上sigmod函式,得到一個概率值,進而判斷該樣本屬於哪一類。計算公式如下: 其中,是權重,也是我們待求引數。 根據概率值對樣本進行分類:
邏輯迴歸的代價函式
為了使正樣本得到高的概率值(接近1好),負樣本得到低的概率值(接近0好),從而找出權重引數。設計單個樣本的損失函式如下: 對於整個資料集m個樣本的損失函式如下: 雖然沒有bishijie封閉解,但因為是凸函式,可以用梯度下降法求解。
極大似然估計
由以上公式,可知任何一個樣本都有:
整合一下:
那麼,對於所有m個樣本發生的概率是:
取對數:
得到的結果實質上和損失函式是一樣的。
利用梯度下降法求引數
sigmod函式有如下性質:
對的第j個屬性 求梯度,
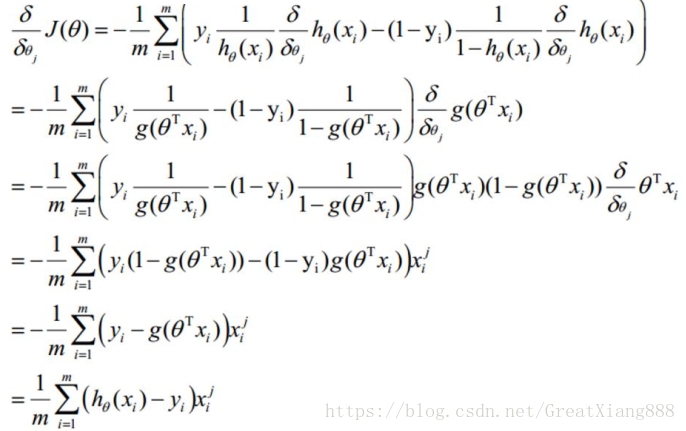
最後,對的第j個屬性來說,梯度下降的表示式為: