
Is Faster R-CNN Doing Well for Pedestrian Detection?論文翻譯
翻譯僅為學習,如有侵權請聯絡我刪除
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
摘要行人檢測被認為是特定課題,而不是一般的物體檢測。雖然最近的深度學習物件檢測器,如Fast/Faster R-CNN[1,2]在一般目標檢測方面表現出了優異的效能,但它們在檢測行人方面的成功率有限,而以往的主要行人檢測器通常採用手工構造特徵和深度卷積特徵相結合的混合方法。在本文中,我們研究了Faster R-CNN[2]的行人檢測問題。我們發現Faster R-cnn中的區域提議網路(Rpn)作為一個獨立的行人檢測器確實表現良好,但令人驚訝的是,下游分類器降低了結果。我們認為可能是如下兩個原因導致的:(一)處理小例項的特徵圖解析度不足;(二)缺乏挖掘硬負面例項的自舉策略。在這些觀測的驅動下,我們提出了一個非常簡單但有效的行人檢測基線,在共享的、高解析度的卷積特徵圖上使用RPN,後接boosted forests。我們在幾個基準(Cal-tech、INRIA、ETH和Kitti)上對該方法進行了綜合評價,顯示出了競爭的準確性和良好的速度。程式碼將公開。
1、簡介
行人檢測作為自動駕駛、智慧監控等實際應用中的一個重要組成部分,已經引起了人們的廣泛關注。儘管計算機視覺中的深入學習特性取得了普遍的成功,但目前領先的行人檢測器(例如,[3,4,5,6])通常是將傳統手工製作的特徵[7,8]和深卷積特徵[9,10]結合在一起的混合方法。例如,在[3]中,採用一個獨立的行人檢測器11作為高度選擇性的提議者(每幅影象<3個區域),然後採用R-CNN[12]進行分類。手工製作的特徵似乎對最先進的行人檢測至關重要。
圖1、Fast/Faster R-CNN在行人檢測中的兩個挑戰。(A)小型物件可能無法在低解析度特徵圖上實現ROI池化。(B)在Fast/Faster R-CNN中沒有得到認真注意的嚴重的負面例子。

另一方面,Faster R-CNN[2]是一種特別成功的一般目標檢測方法。它由兩個部分組成:一個完全卷積區域提案網路(RPN),用於提出候選區域,然後是一個下游Fast R-CNN[1]分類器。因此,Faster R-cnn系統是一種純粹基於cnn的方法,無需使用手工製作的特徵(例如,基於低階特徵的選擇性搜尋[13])。儘管它的精確性領先於幾個多類別的基準,Faster R-cnn並沒有在流行的行人檢測資料集(例如Caltech集[14])上呈現出有競爭力的結果。
在本文中,我們研究了Faster R-CNN作為行人檢測器的問題。有趣的是,我們發現一個專門為行人檢測量身定做的RPN作為一個獨立的行人檢測器取得了有競爭力的結果。但令人驚訝的是,在將這些提議輸入Fast R-CNN分類器後,準確性就降低了。我們認為,這種不令人滿意的表現有以下兩個原因。
首先,Fast R-CNN分類器的卷積特徵圖對於小目標的檢測具有較低的解析度。典型的行人檢測場景,如自動駕駛和智慧監控,通常會出現小規模的行人例項(例如,28×70[14])。在小物體上(圖1(A),感興趣區域(ROI)池層[15,1]在低解析度特徵對映(通常有16畫素的步幅)上執行,可以導致摺疊箱造成的“平坦”特徵。這些特徵不區分小區域,從而降低了下游分類器的等級。我們注意到,這與手工製作的具有更好的解析度的特徵形成了鮮明對比。我們通過池化較淺但解析度較高的層的特徵,以及通過增加特徵圖大小的孔演算法(即“àtrous”[16]或Filter稀薄[17])來解決這個問題。
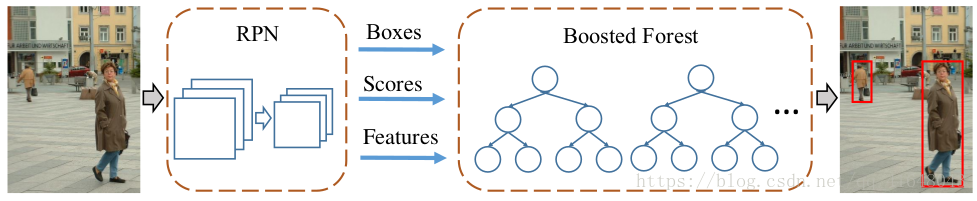
圖2、我們的模型。RPN用於計算候選邊界框、分數和卷積特徵對映。候選框被輸入級聯增強森林(BF)進行分類,使用從RPN計算的卷積特徵圖中彙集的特徵。
其次,在行人檢測中,錯誤預測主要是由硬背景例項的混淆引起的(圖1(B)。這與一般的物件檢測形成了鮮明的對比,在這種情況下,混淆的主要來源來自多個類別。為了解決硬負例,我們採用級聯增強森林(BF)[18,19]進行有效的硬負挖掘(Bootstrating)和樣本重加權,對RPN提出的候選區域進行分類。與以前使用手工製作的特徵來訓練森林不同的是,在我們的方法中,BF重用了RPN的深度卷積特徵。該策略不僅通過共享特徵降低了分類器的計算量,而且利用了深入學習的特徵。
因此,我們提出了一個令人驚訝的簡單但有效的基線,用於基於RPN和BF的行人檢測。我們的方法克服了Faster R-CNN用於行人檢測的兩個限制,並擺脫了傳統手工製作的特徵。我們在一些基準上給出了令人信服的結果,包括Caltech[14]、INRIA[20]、ETH[21]和Kitti[22]。值得注意的是,我們的方法在評估交併比(IOU)閾值0.7的情況下,定位精度有了很大的提高,在Caltech資料集上相對提高了40%。同時,該方法的測試時間速度為每幅影象0.5秒,與以往的方法相比具有很強的競爭力。
此外,本文還揭示了傳統的行人檢測器至少有兩個原因被繼承在最近的方法中。首先,手工製作的高解析度特徵(如[7,8])及其金字塔有利於探測小物體。其次,對硬負例的挖掘進行了有效的引導。然而,如果在深度學習系統中適當地處理這些關鍵因素,就會產生優異的效果。
2、相關工作
積分通道特徵(ICF)檢測器[7]擴充套件了Viola-Jones框架[23],是最流行的無深度學習特徵的行人檢測器之一。ICF檢測器包括通道特徵金字塔和增強分類器。ICF的特徵表示方法已經通過多種方法提升了,有ACF[8]、LDCF[24]、SCF[11]等,但Booding演算法仍然是行人檢測的關鍵組成部分。
在一般目標探測的(“慢”)R-cnn[12]的成功的推動下,最近的一系列方法[11,4,5]採用兩級管道進行行人檢測。在[3]中,SCF行人檢測器[11]用於提出區域,隨後使用R-CNN進行分類;TA-CNN[4]使用ACF檢測器[8]生成建議,並訓練R-CNN風格的網路來聯合優化具有語義任務的行人檢測;DeepParts方法[5]使用LDCF檢測器[24]生成建議,並通過神經網路學習一組互補部分。我們注意到,這些提議者是獨立的行人探測器,由手工製作的特徵和增強分類器組成。
與上述基於R-cnn的方法不同,CompACT方法[6]在混合手工和深卷積特徵的基礎上學習增強分類器。與我們的工作密切相關的是,CCF檢測器[25]是在深度卷積特徵金字塔上的增強分類器,但沒有使用區域提案。我們的方法沒有金字塔,比[25]更快、更精確。
3、方法
我們的方法包括兩個元件(如圖2所示):一個RPN生成候選框以及卷積特徵對映,以及一個使用這些卷積特徵對這些提議進行分類的增強森林。
3.1、行人檢測的區域提議網路
Faster R-CNN[2]中的RPN是在多類目標檢測場景中發展起來的一類不可知檢測器。對於單類別檢測,RPN自然是唯一相關類別的檢測器。我們特別為行人檢測量身訂造RPN,如下所述。
我們採用單縱橫比為0.41(寬與高)的錨(參考箱)[2]。如[14]所示,這是行人的平均高寬比。這與最初的RPN[2]不同,RPN[2]具有多個縱橫比的錨。高寬比不適當的錨點與例項很少相關,因此噪聲大,不利於檢測精度。此外,我們使用9種不同尺度的錨,從40畫素的高度開始,尺度步長為1.3×。這一範圍比[2]範圍更廣。多尺度錨的使用省去了使用特徵金字塔檢測多尺度物件的要求。
在[2]之後,我們採用了在ImageNet資料集[26]上預先訓練的VGG-16網[10]作為骨幹網路。RPN建立在Conv 5_3層之上,然後是中間3×3卷積層和2個1×1卷積層,用於分類和邊界框迴歸(詳見[2])。通過這種方式,RPN可以通過16畫素的步幅(Conv 5_3)來恢復方框。分類層提供了預測框的置信度分數,可用作後續增強森林梯級的初始分數。
值得注意的是,雖然我們將在下一節中使用“àtrous”[16]技巧來增加解析度和減少步幅,但我們仍然使用相同的步幅為16畫素的RPN。只有在提取特性時(如下一節介紹的那樣),才能利用這個技巧,而不是用於微調。
3.2、特徵提取
根據RPN提出的候選區域,我們採用ROI池[1]從區域中提取固定長度的特徵。如下一節所介紹的那樣,這些特性將被用來訓練BF。與速度更快的R-cnn不同,後者需要將這些特徵輸入到原始的完全連線(FC)層,從而限制它們的維數,BF分類器不對特徵的維數施加任何限制。例如,我們可以從Conv 3_3(步幅=4畫素)和Conv 4_3(步長=8畫素)上的Rois中提取特徵。我們將特徵集合成7×7的固定解析度。由於BF分類器的靈活性,這些來自不同層的特徵只是簡單地連在一起而不進行歸一化;相比之下,對於深度分類器,當歸一化特徵時,需要仔細地處理這些特徵[27]。
值得注意的是,由於沒有對特徵尺寸施加任何限制,我們可以靈活地使用解析度更高的特徵。特別是,考慮到RPN中的微調層(Conv 3上的span=4,Conv 4上的8層,Conv 5上的16層),我們可以使用àtrous技巧[16]來計算解析度更高的卷積特徵對映。例如,我們可以將Pool 3的步長設為1,並將所有Conv 4濾波器擴充套件2,從而將Conv 4的步幅從8減小到4。與以前的方法[17,16]微調膨脹濾波器不同,在我們的方法中,我們只使用它們進行特徵提取,而不對新的rpn進行微調。
雖然我們採用與Faster R-CNN[2]相同的ROI解析度(7×7),這些ROI相比Fast R-CNN(Conv 5_3)是在更高解析度的特徵圖(例如,Conv 3_3,Conv 4_3,或Conv 4_3àtrous)。如果ROI的輸入解析度小於輸出(<7×7),則池箱崩潰,特徵變得“平坦”而不具有區分性。這個問題在我們的方法中得到了緩解,因為在我們的下游分類器中使用Conv 5_3的特性是不受限制的。
3.3 Boosted Forest
RPN生成了區域提案、信心分數和特徵,所有這些都用於訓練級聯增強森林分類器。我們採用RealBoost演算法[18],主要跟蹤[6]中的超引數。形式上,我們引導訓練6次,每個階段的森林都有{64,128,256,512,1024,1536}樹。最初,培訓集由所有正面示例(Caltech集上的∼50k)和相同數量的從提案中隨機抽樣的負示例組成。在每個階段之後,挖掘額外的硬負示例(其數量為陽性數的10%,∼5k on Caltech),並將其新增到培訓集中。最後,一個擁有2048棵樹的森林在經過所有的自舉階段後都得到了訓練。最後一個林分類器用於推理。我們的實現是以[28]為基礎的。
我們注意到,沒有必要平等地處理最初的建議,因為我們的建議有RPN計算的初步信任分數。換句話說,rpn可以看作是stage-0的分類器f0,我們按照RealBoost形式設定f0=0.5*log(s/(1-s)),其中s是建議區域的分數(f0是標準boosting的常數)。其他階段與標準RealBoost相同。
3.4 實現細節
我們採用[15,1,2]中的單尺度訓練和測試,而不使用特徵金字塔。對影象進行調整,使其較短的邊緣具有N個畫素(Caltech為N=720畫素,INRIA為600畫素,ETH為810畫素,Kitti為500畫素)。對於RPN訓練,如果錨與一個真值框的交併比(IOU)大於0.5那麼錨就被認為是一個正的例子,否則它是負的。我們採用了以影象為中心的訓練方案[1,2],每個小批由1個影象和120個隨機抽樣的錨組成,用於計算損失。在一個mini-batch中正樣本與負樣本的比例為1:5。RPN的其他超引數如[2]所示,我們採用[2]的公開程式碼對RPN進行微調。我們注意到,在[2]中,跨邊界的錨在微調過程中被忽略,而在我們的實現中,我們在微調過程中保留了跨界負錨,這在經驗上提高了這些資料集的準確性。
在微調RPN的情況下,我們採用閾值為0.7的非最大抑制(NMS)方法對建議區域進行濾波。然後將提案區域按分數進行排序。對於BF訓練,我們通過選擇每個影象的分數最高1000項提議(和真值框)來構建訓練集。根據不同資料集的大小,將樹深設為5,INRIA和ETH集為2,而INRIA和ETH集為2。在測試的時候,我們只使用圖片中排名最高的100個提案,這是由BF分類的。
4、實驗和分析
4.1、資料集
我們綜合評價了4個基準:Caltech[14]、INRIA[20]、ETH[21]和Kitti[22]。預設情況下,用於確定這些資料集中的正例的IOU閾值為0.5。
在Caltech[14]上,訓練資料在[3]之後增加了10倍(42782幅影象)。標準測試集中的4024幅影象用於在“合理”設定下對原始註釋進行評估(行人至少有50畫素高,至少65%可見)[14]。評價指標是[10−2,10 0]中對每幅影象的假陽性的對數平均漏報率(在[29]後面表示為MR−2,或者簡稱MR)。此外,我們還在[29]提供的新註釋上測試我們的模型,這將糾正原始註釋中的錯誤。這個集合被表示為“Caltech-New”。Caltech的評價指標是MR−2和MR−4,對應於[10−2,10 0]和[10−4,10 0]的FPPI對數平均漏報率[29]。
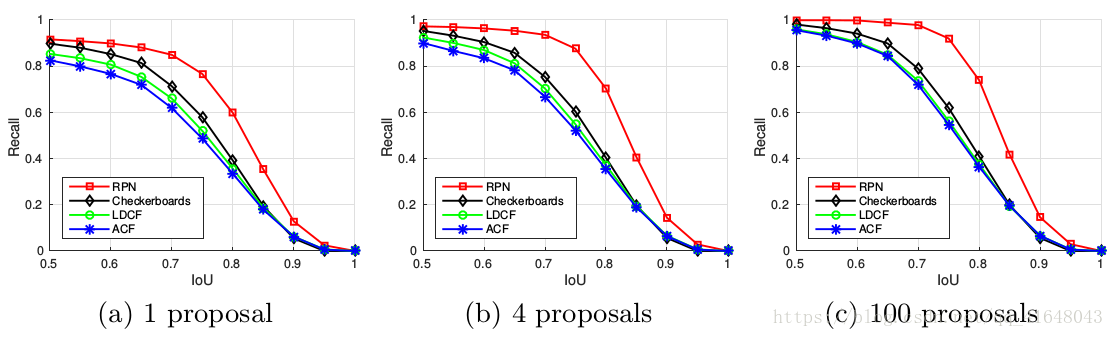
圖3、比較RPN和現有的三種方法在Caltech資料集的提案質量(召回和IOU),平均每個影象1,4或100個提案被評估。
INRIA[20]和ETH[21]資料集常用於驗證模型的泛化能力。按照[30]中的設定,我們的模型在INRIA培訓集中對614幅正面圖像和1218幅負片影象進行了培訓。模型在INRIA中的288張測試影象上進行了評估,在ETH中的1804幅影象上進行了評估,由MR−2進行了評估。
Kitti資料集[22]由具有立體聲資料的影象組成。我們對7481的左相機影象進行訓練,並對標準的7518個測試影象進行評估。KITTI評估PASCAL-style平均精度(地圖)在三個困難級別:“容易”,“中等”和“困難”1。
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
後面的消融實驗等實驗資料對比感興趣的可以自行檢視相應論文。