Python爬蟲框架Scrapy例項(二)
阿新 • • 發佈:2018-12-15
目標任務:使用Scrapy框架爬取新浪網導航頁所有大類、小類、小類裡的子連結、以及子連結頁面的新聞內容,最後儲存到本地。
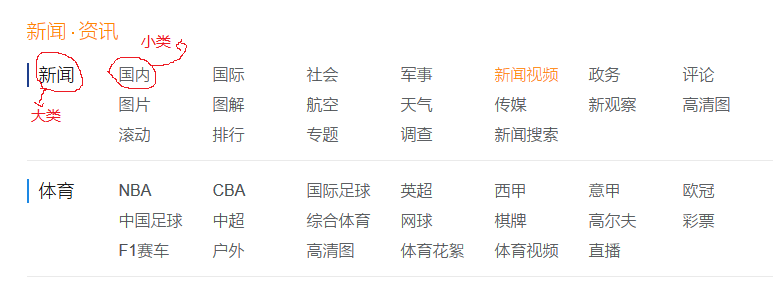
大類小類如下圖所示:
點選國內這個小類,進入頁面後效果如下圖(部分截圖):

檢視頁面元素,得到小類裡的子連結如下圖所示:

有子連結就可以傳送請求來訪問對應新聞的內容了。
首先建立scrapy專案
# 建立專案 scrapy startproject sinaNews # 建立爬蟲 scrapy genspider sina "sina.com.cn"
一、根據要爬取的欄位建立item檔案:

# -*- coding: utf-8 -*-
import scrapy
import sys
reload(sys)
sys.setdefaultencoding("utf-8")
class SinanewsItem(scrapy.Item):
# 大類的標題和url
parentTitle = scrapy.Field()
parentUrls = scrapy.Field()
# 小類的標題和子url
subTitle = scrapy.Field()
subUrls = scrapy.Field()
# 小類目錄儲存路徑
subFilename = scrapy.Field()
# 小類下的子連結
sonUrls = scrapy.Field()
# 文章標題和內容
head = scrapy.Field()
content = scrapy.Field()
二、編寫spiders爬蟲檔案
# -*- coding: utf-8 -*-
import scrapy
import os
from sinaNews.items import SinanewsItem
import sys
reload(sys)
sys.setdefaultencoding("utf-8")
class SinaSpider(scrapy.Spider):
name = "sina"
allowed_domains = ["sina.com.cn"]
start_urls = ['http://news.sina.com.cn/guide/']
def parse(self, response):
items= []
# 所有大類的url 和 標題
parentUrls = response.xpath('//div[@id="tab01"]/div/h3/a/@href').extract()
parentTitle = response.xpath('//div[@id="tab01"]/div/h3/a/text()').extract()
# 所有小類的ur 和 標題
subUrls = response.xpath('//div[@id="tab01"]/div/ul/li/a/@href').extract()
subTitle = response.xpath('//div[@id="tab01"]/div/ul/li/a/text()').extract()
#爬取所有大類
for i in range(0, len(parentTitle)):
# 指定大類目錄的路徑和目錄名
parentFilename = "./Data/" + parentTitle[i]
#如果目錄不存在,則建立目錄
if(not os.path.exists(parentFilename)):
os.makedirs(parentFilename)
# 爬取所有小類
for j in range(0, len(subUrls)):
item = SinanewsItem()
# 儲存大類的title和urls
item['parentTitle'] = parentTitle[i]
item['parentUrls'] = parentUrls[i]
# 檢查小類的url是否以同類別大類url開頭,如果是返回True (sports.sina.com.cn 和 sports.sina.com.cn/nba)
if_belong = subUrls[j].startswith(item['parentUrls'])
# 如果屬於本大類,將儲存目錄放在本大類目錄下
if(if_belong):
subFilename =parentFilename + '/'+ subTitle[j]
# 如果目錄不存在,則建立目錄
if(not os.path.exists(subFilename)):
os.makedirs(subFilename)
# 儲存 小類url、title和filename欄位資料
item['subUrls'] = subUrls[j]
item['subTitle'] =subTitle[j]
item['subFilename'] = subFilename
items.append(item)
#傳送每個小類url的Request請求,得到Response連同包含meta資料 一同交給回撥函式 second_parse 方法處理
for item in items:
yield scrapy.Request( url = item['subUrls'], meta={'meta_1': item}, callback=self.second_parse)
#對於返回的小類的url,再進行遞迴請求
def second_parse(self, response):
# 提取每次Response的meta資料
meta_1= response.meta['meta_1']
# 取出小類裡所有子連結
sonUrls = response.xpath('//a/@href').extract()
items= []
for i in range(0, len(sonUrls)):
# 檢查每個連結是否以大類url開頭、以.shtml結尾,如果是返回True
if_belong = sonUrls[i].endswith('.shtml') and sonUrls[i].startswith(meta_1['parentUrls'])
# 如果屬於本大類,獲取欄位值放在同一個item下便於傳輸
if(if_belong):
item = SinanewsItem()
item['parentTitle'] =meta_1['parentTitle']
item['parentUrls'] =meta_1['parentUrls']
item['subUrls'] = meta_1['subUrls']
item['subTitle'] = meta_1['subTitle']
item['subFilename'] = meta_1['subFilename']
item['sonUrls'] = sonUrls[i]
items.append(item)
#傳送每個小類下子連結url的Request請求,得到Response後連同包含meta資料 一同交給回撥函式 detail_parse 方法處理
for item in items:
yield scrapy.Request(url=item['sonUrls'], meta={'meta_2':item}, callback = self.detail_parse)
# 資料解析方法,獲取文章標題和內容
def detail_parse(self, response):
item = response.meta['meta_2']
content = ""
head = response.xpath('//h1[@id="main_title"]/text()')
content_list = response.xpath('//div[@id="artibody"]/p/text()').extract()
# 將p標籤裡的文字內容合併到一起
for content_one in content_list:
content += content_one
item['head']= head
item['content']= content
yield item
三、編寫pipelines檔案
# -*- coding: utf-8 -*-
from scrapy import signals
import sys
reload(sys)
sys.setdefaultencoding("utf-8")
class SinanewsPipeline(object):
def process_item(self, item, spider):
sonUrls = item['sonUrls']
# 檔名為子連結url中間部分,並將 / 替換為 _,儲存為 .txt格式
filename = sonUrls[7:-6].replace('/','_')
filename += ".txt"
fp = open(item['subFilename']+'/'+filename, 'w')
fp.write(item['content'])
fp.close()
return item
四、settings檔案的設定
# 設定管道檔案
ITEM_PIPELINES = {
'sinaNews.pipelines.SinanewsPipeline': 300,
}
執行命令
scrapy crwal sina
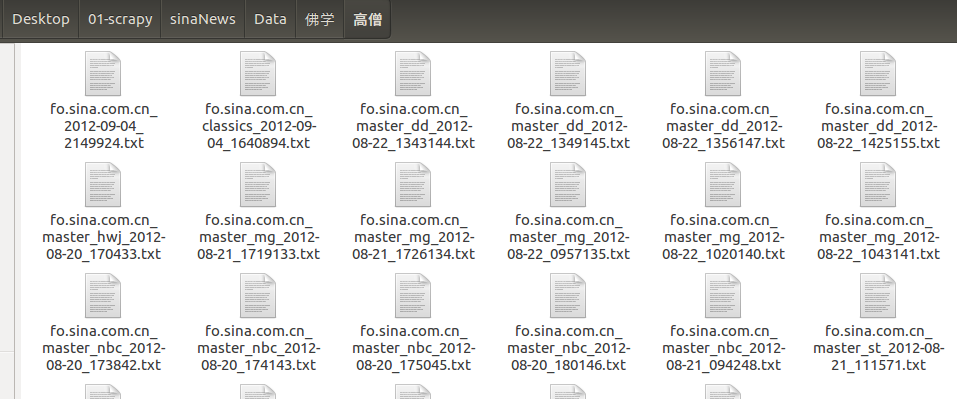
效果如下圖所示:
開啟工作目錄下的Data目錄,顯示大類資料夾
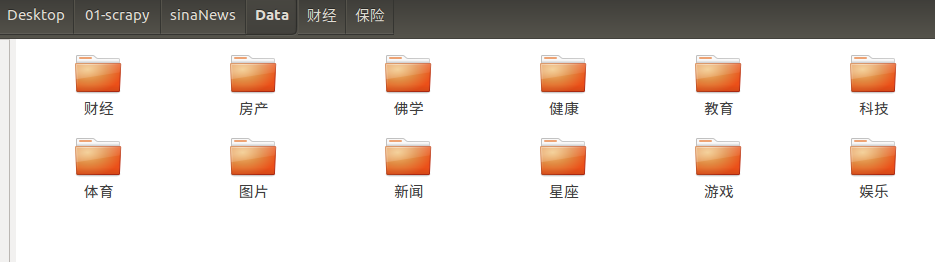
大開一個大類資料夾,顯示小類資料夾:

開啟一個小類資料夾,顯示文章: