
NLP --- 隱馬爾可夫HMM(第一個、第二個問題解決方案)
上一節我們詳細的闡述了隱馬爾可夫的三個基本問題,結合者背景知識理解這三個問題還是很容易的,因為隱馬爾可夫的提出就是建立在語音識別的基礎上提出來的,因此根據背景知識學習更容易吸收和深入理解,簡單的來說就是物理意義,這裡大家理解演算法類的都儘量通過物理意義進行理解,這樣學習效果會更好,另外就是本節只會解決前兩個基本問題,結尾引出第三問題,然後分析問題的難點在哪裡,講明白為什麼要引入EM演算法,然後下一節將從最大釋然估計講解,由此引入EM演算法,最後在解決第三個問題,廢話不多說,下面開始:
隱馬爾可夫的定義放在這裡:
一般的,一個HMM記為一個五元組,其中,S為狀態的集合,K為輸出符號的集合,
第一個基本問題的解決方案
先把第一個基本問題拿過來看一下,沒有深入理解的建議看我上一節的什麼是三個基本問題(什麼是三個基本問題):
估計問題:給定一個觀察序列和模型
,如何快速地計算出給定模型
情況下,觀 察序列
的概率,即
?
首先我們需要分析一下問題,給出的條件是觀察序列和模型
對任意的狀態序列,有:
這裡解釋一下,上式的表示在已知模型
和狀態序列
的情況下求發射的符號序列的概率(HMM使用B表示符號發射概率),可以寫成每個狀態下發射符號O的概率的乘積,這裡隱藏一個假設即不同的狀態發射的符號是相互獨立的,因此可以寫成(1)式,我們繼續:
這裡的表示的在已知模型
的情況下求總狀態轉移的概率,HMM的定義狀態轉移概率使用A來表示,因此
可以寫成每個狀態轉移概率的乘積(這裡馬爾科夫鏈可得),繼續往下:
上面的(3)式是根據(1)、(2)兩式得來的,怎麼解釋他呢?意思是在模型
的情況下的狀態轉移和發射符號序列的概率(這裡是條件概率,O,Q是一體的),他就等於
在模型
的情況下的狀態轉移概率乘上
即在
和Q條件下的發射符號的概率,這裡大家需要好好,體會,他們是不是相等的,
此時得到式後就好辦了,
是條件下的聯合概率分佈,那麼我在條件
的情況下也可以求邊緣密度分佈,因此就有下式:
上式大家應該很容理解了,分別帶進去後就會得到上式,所以第一個問題最後就化簡成上式了,那麼我們如何求解呢?我們先看前一部分他是求和的,這部分的計算量不大,一旦轉態轉移Q確定下來基本上求和就確定下來了,難點在於後一部分的求積,既然要求最後的概率最大,那麼就要求累乘的概率每轉移到一個狀態的概率達到最大,好,到這裡我們再想想我們現在的目標是總體是概率最大,而上式的前一部分是求和,只要每個狀態的轉移和發射符號的概率最大那麼求和的結果就會最大,後一部分要求轉移概率的總乘積的概率最大,另外就是大家看看這裡目標和演算法中的哪個演算法最類似?這裡要求最大概率是針對全域性概率,因此不能使用貪心演算法,因為貪心演算法只可能取得區域性最優解,因此這裡使用動態規劃求解是最合適的,動態規劃的演算法這裡不再詳細解釋了,年後我會專門開一個欄目講演算法的,這裡我先簡單的解釋一下動態規劃的核心思想,他是從結果分析,然後從結果(全域性)出發,反推到開始,把結果都記錄下來,然後寫程式碼時通過遞迴直接呼叫計算好的結果,這裡計算量就下來了,下面總體分析一下上式:
上述推導方式很直接,但面臨一個很大的困難是,必須窮盡所有可能的狀態序列。如果模型中有N個不同的狀態,時間長度為T,那麼,有NT個可能的狀態序列。這樣,計算量會出現“指數爆炸”。當T很大時,幾乎不可能有效地執行這個演算法。為此,人們提出了前向演算法或前向計算過程(forward procedure),利用動態規劃的方法來解決這一問題,使“指數爆炸”問題可以在時間複雜度為
的範圍內解決。
HMM中的動態規劃問題一般用格架(trellis或lattice)的組織形式描述。對於一個在某一時間結束在一定狀態的HMM,每一個格能夠記錄該HMM所有輸出符號的概率,較長子路徑的概率可以由較短子路徑的概率計算出來,如下圖:

這裡解釋一下上圖是什麼意思 ,首先表示狀態,即隱馬爾可夫總共有N個狀態,每一個時刻的狀態都是這裡面的一種可能情況,因此上圖的意思就是橫向是時間走向1,2,3,4,,,,T,縱向就是每個時刻的可能選擇的所有狀態了,也就是說肯定存在一個通路是我們想要的,如上圖的紅線路徑。因此從上圖可以看出狀態轉移的可能輸太多了,計算量很龐大,因此使用動態規劃解決計算量大問題,使用遞迴去搜索全域性最優解,下面是就是如何推出遞迴表示式呢?同時這個演算法又叫前項演算法。
前向演算法
為了找到遞迴的表示式或者說為了實現前項演算法,這裡需要定義一箇中間變數(前項變數)即,如下定義:
定義: 中間變數是在時間
,HMM輸出了序列
,並且位於狀態
的概率:
前項演算法的主要思想是,如果可以快速計算前項變數,那麼就可以根據
計算出
是在所有狀態
下觀察到序
的概率:
所有說現在是如何構造這個遞推關係式,這一點其實在演算法中也是最難的即建模思想,這個需要你深入理解各個演算法的優缺點的情況下,找出他們的遞推關係,所以有時間的朋友還是把演算法好好學一學,過段時間我也單獨開開一系列總結演算法。我們下面就分析如何找出他們的關係即和
的關係,如果這一節你看不懂,或者理解困難,說明你對動態規劃的演算法理解的不深入,可以暫時停下來學習一下動態規劃這個演算法。下面開始推倒他們的關係:
在前項演算法中,採用動態規劃的方法計算前向變數,其實現思想基於如下:
在時間的前向變數可以根據在時間
時的前向變數
的值來歸納計算:
下面同示意圖進行詳細解釋上式的意義:

上圖代表的意思大家應該都懂吧,這裡是時間t到t+1的轉移過程,假設在t時刻的中間變數概率為,而
表示在已知觀察序列
的情況下,從時間
到達下一個時間
時的狀態為
的概率。從初始時間開始到
,HMM到達狀態
,並輸出觀察序列
的過程可以分解為一下兩個步驟:
(1)從初始時間開始到時間,HMM到達狀態
,並輸出觀察序列
;
(2)從狀態轉移到狀態
,並在狀態
輸出
。
這裡的可以是HMM的狀態集的任意一個狀態,根據
的定義,從某一個狀態
出發完成第一步的概率就是
,而完成第二步的概率為
。因此,從初始時間到
這個過程的概率為
。由於HMM可以從不同的
轉移到
,一共有N個不同的狀態,需要把能轉移到這個狀態的概率求和,這裡大家可能會迷惑為什麼是是在t時刻的求和呢?這裡簡單的解釋一下,因為在t時刻的N種狀態都有可能轉移到
,此時我們要求的是轉移到
的概率有多大,而在t時刻時我們已經分別知道了t-1時刻轉移到t時刻的所有狀態的概率,這就是從全域性出發,即我不管t時刻從哪個狀態轉移到
的概率,而是考慮總體上只關心t+1時刻在
狀態時的總概率是多少,這是動態規劃的核心思想了。 因此就得到了上式的推倒。
因此通過上式可以以此計算,
為HMM的狀態變數,由此我們給出前項演算法的虛擬碼:
第一步 初始化:
第二步 歸納計算:
第三步 求和結束:
在初始化步驟中,是初始狀態
的概率,
是在
狀態輸出
的概率,那麼,
就是在時刻t=1時,HMM在
狀態輸出序列
,即前項變數
,一共有N個狀態,因此需要初始化N個前項變數
.
現在來分析一下前項演算法的時間複雜性,由於每計算一個必須考慮
時的所有N個狀態轉移到狀態
的可能性,其時間複雜性為
,那麼,對應每個時間t,要計算N個前項變數
,因此時間複雜性為
,因而,在1,2,。。。,T整個過程中,前項演算法的總時間複雜性為
上面就是前項演算法了,解決第一個基本問題還有另外一個方法就是後向演算法,其實和前項演算法很類似的,這裡不細講了,只把過程寫一下。
後向演算法
和前項演算法類似,這裡也定義一個前項變數.

定義:後向變數是在給定了模型
,並且在時間t狀態為
的條件下,HMM輸出觀察序列
的概率:
與計算前向變數一樣,可以用動態規劃的演算法計算後向變數。類似地,在時間t狀態為的條件下,HMM輸出觀察序列
的過程可以分解為以下兩個步驟:
(1) 從時間t到時間,HMM由狀態
到狀態
,並從
輸出
;
(2)在時間的狀態為的條件下,HMM輸出觀察序列
。
第一步中輸出的概率為:
;
第二步中根據後向變數的定義,HMM輸出觀察序列為的概率就是後向變數
。於是,得到如下歸納關係:
根據後向變數的歸納關係,按,順序依次計算
(x為HMM的狀態),就可以得到整個觀察序列
.
虛擬碼:
第一步 初始化:
第二步 歸納計算:
第三步 求和結束:
同理計算時間複雜度為也為。
還有一種演算法是二者的結合,如下式:
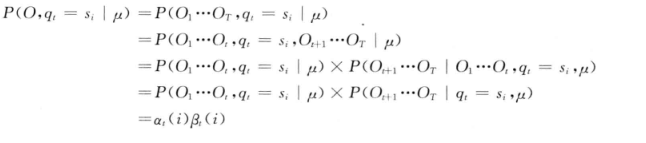
以上就是解決第一個問題的演算法了,下面介紹解決第二個問題的演算法即維特比演算法。
第二個基本問題的解決方案
這裡也把第二個問題直接拿過來了,不懂的建議看我的上一篇部落格:
序列問題:給定一個觀察序列和模型:
,如何快速有效地選擇在一定意義下“最 優”的狀態序列
,使得該狀態序列“最好地解釋”觀察序列?
這裡還是簡單的通過語音識別的例子進行解釋一下,其實簡單來說就是我們輸入了正確的語音訊號(拼音),現在的問題是我們在已知模型和觀察序列(拼音、語音訊號)的情況下,去計算出對應的隱藏序列(漢字序列)使其最符合我們的觀察序列。還不懂的看我的上一篇部落格,別拖,別稀裡糊塗。
維特比(Viterbi)演算法用於求解HMM中的第二個問題,即給定一個觀察序列和模型
,如何快速有效地選擇在一定意義下“最優”的狀態序列
使得該狀態序列“最好地解釋”觀察序列。即在給定的模型和觀察給定序列O的條件下,使的條件概率
最大的狀態序列,如下:
所以如何求上式的最大概率呢?維特比演算法使用了動態規劃的搜尋演算法求解這種最優狀態序列,為了實現這種搜尋,首先定義一個維特比變數.
定義: 維特比變數在時間t時,HMM沿著某一條路徑到達狀態
,並輸出觀察序列
的最大概率:
與前向變數類似,有如下遞迴關係:
這裡我想還是解釋一下上式,如果深入理解動態規劃思想的朋友,上面的式子還是很簡單的,因此這裡,我還是來簡單的解釋一下吧,首先我們的目的是求最大概率的狀態序列,而背景框架是和前向演算法一樣的 ,我們知道如果窮舉,計算量太大了,而且這裡的最大概率是全域性最優的,因此最適合的就是動態規劃演算法了,動態規劃演算法的思想是從全域性出發也就是從結果出發,這裡的結果是 ,即最後一步的需要概率和最後一步以前的概率都是最大的,這樣才能保證最後結果是最大的,然後最後一步是通過上一步過來的即上式了,那麼要保證最後一步最大就要保證從上一步的狀態轉移到最後的狀態的概率最大,這樣不停尋找上一步就得出結果了。
這種遞迴關係使我們能夠運用動態規劃搜尋技術。為了記錄在時間t時,HMM通過哪一條概率最大的路徑到達狀態,維特比演算法設定了另外一個變數
用於路徑記憶,讓
記錄該路徑上狀態的前一個(在時間t-1的)狀態。根據這種思路,給出如下維特比演算法。
維特比演算法:
第一步 初始化:
第二步 歸納計算:
記憶回退路徑:
第三步 計算結束:
第四步 路徑回溯:
維特比演算法的時間複雜性與前向演算法、後向演算法的時間複雜性一樣,也是。在實際應用中,往往不只是搜尋一個最優狀態序列,而是搜尋n個最佳(n-best)路徑,因此,在格架的每個結點上常常需要記錄m個最佳(m-best,m<n)狀態。
第三個問題:
訓練問題或引數估計問題:給定一個觀察序列,如何根據最大似然估計來求模型的引數值?即如 何調節模型
的引數,使得
最大?
首先這個問題很重要,而且解決起來也很困難,重要體現在他是構建模型的,因為我們的第一個問題和第二個問題都是建立在模型
已知的情況下才能計算,所以這個問題的解決很重要,困難稍後解釋。因此這個問題是最基礎的問題,但是為什麼要作為第三個問題呢?這是因為這個問題解決起來太麻煩了,因此這樣安排。大家知道我們剛開始是沒有模型的即HMM的引數都不知道,但是我們有什麼呢?我們有語料,因為通過語料可以求解HMM的三個引數即狀態轉移概率A、符號發射概率B和初始狀態概率分佈。這裡呢要想計算出這些引數,首先我們應該有完美的語料,如果沒有完美的語料怎麼辦呢?所有我們從兩方面進行探討即有完美語料和沒有完美語料。
完美語料
所謂完美語料就是我既知道發射符號的序列,也知道狀態轉移序列,這裡我們就可以使用最大釋然估計計算HMM的引數了,下面通過書面語進行說明:
引數估計問題是HMM面臨的第三個問題,即給定一個觀察序列,如何調節模型
的引數,使得
最大化:
模型的引數是指構成的
。最大似然估計方法可以作為HMM引數估計的一種選擇。如果產生觀察序列
的狀態序列
已知,根據最大似然估計,HMM的引數可以通過如下公式計算:

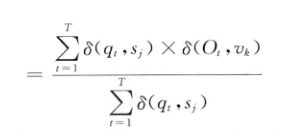
上面的是衝擊函式即當兩個引數相等是為1,反之為0
不完美語料
不完美語料是指知道觀察序列但是不知道狀態轉移序列,因此無法用最大釋然估計進行解決,此時可以是使用EM 演算法【Expectation Maximization(期望最大化)】,到這裡本節就結束了,下一節將從最大釋然估計開始,然後講EM演算法,最後再講三個問題的具體解決過程。
注:本節主要參考了宗成慶的《統計自然語言處理》