
深度學習 --- 深度殘差網路詳解ResNet
本來打算本節開始迴圈神經網路RNN,LSTM等,但是覺得還是應該把商用比較火的網路介紹一下,同時詳細介紹一下深度殘差網路,因為他是基於卷積的。而後面的迴圈神經網路更多偏向於序列問題,偏向語音識別,自然語言處理等的應用,而卷積神經網路更偏向於影象識別方面的應用,因此在本節就介紹幾種常用的神經網路,當然現在的網路很多了,但是我們不講那麼多,只講很火的網路,其實如果大家把卷積神經網路徹底搞明白了,看其他的網路還是很容易的,因為就那些東西,不一樣的算是在卷積的基礎上加一點東西,因此從這裡又看出基礎的重要性,廢話不多說,下面我們開始:

從上圖的Imagenet的比賽上我們可以看到我們前面講的hintion帶領的團隊使用深度卷積神經網路AlexNet贏得了2012年的比賽冠軍,此時網路8層,2014年的比賽中Googlenet獲得冠軍,而VGG獲得亞軍,但是在後面的商用中,VGG被使用的更廣而Googlenet就沒有被使用的很廣,原因是Googlenet的網路複雜,他們設計的是針對這個比賽的,而VGG更通用,可以直接移植使用,稍後大家會看到他們的區別,我們發現二者網路層很接近20多層,錯誤率也很接近,比AlexNet的網路要好很多。15年的比賽獲得冠軍的就是何凱明帶領的微軟研究院發明的RESNET獲得冠軍,此時我們看到網路層數達到驚人的152層,同時錯誤率也創下了驚人的3.57記錄,稍後我們會好好研究他的文章的,在後面我們會研究一下基於RESNET的變體,看看有哪些變體然後簡要的介紹一下。下面我們就看看VGG和Googlenet。
VGG(Visual Geometry Group,視覺幾何組)
大家點選上面的網站去下載對應的論文即“非常深刻的卷積網路進行大規模影象識別”,我們下面就根據這篇論文簡要介紹一下,因為和卷積神經網路很類似,所以學起來很容易。
VGG主要由卡倫· 西蒙尼揚 和 安德魯·齊塞爾曼 這兩個人在卷積神經網路的基礎上演變而來的,網站裡有堅硬的介紹的,我這裡主要從論文開始介紹,下面給出網路結構:

該網路的簡單主要體現在所有的卷積都使用3x3的維度,池化使用的2x2的維度,從上圖我們可以看到ABCDE四種網路,層數是不同的,這裡我們以Ë為例子進行簡單的說明一下,E總共包含19個隱藏層,這裡只算有權值的層,怎麼算呢?如上紅色的標記可知。
我們知道卷積層和池化層的都是3×3 2×2和的,另外就是沒池化一次圖片維度就減少一半,同時卷積核增加一倍,如下圖:

至於如何學習和如何訓練的,和前面的Alexnet網路基本相同,這裡不在家解釋了,以後用到在深入研究了,這裡提一下,下面我們看看Googlenet。
這是谷歌團隊發明的神經網路,之所以名為“GoogLeNet”而非“GoogleNet”,文章說是為了向早期的LeNet致敬。大家可以到網站下載論文進行研究。
與VGG不同的是,goog做了更大膽的網路上的嘗試,為了獲得高質量的模型,它也從增加模型的深度(層數)或者是其寬度(層核或者神經元數)這兩方面考慮了,但是在這種思路下會出現兩個缺陷(1引數太多,容易過擬合,若訓練資料集有限; 2網路越大計算複雜度越大,難以應用; 3網路越深,梯度越往後穿越容易消失,難以優化模型)而GoogLeNet通過新的結構設計,在增加深度和寬度的同時避免了以上問題。:
1. 深度
GoogLeNet採用了22層網路,為了避免上述提到的梯度消失問題,GoogLeNet巧妙的在不同深度處增加了兩個損耗來保證梯度回傳消失的現象結構如圖1所示:

2. 寬度
啟的網路,將1x1,3x3,5x5的CONV和3×3的池,堆疊在一起,一方面增加了網路的寬度,另一方面增加了網路對尺度的適應性,但是如果簡單的將這些應用到特色地圖上的話,concat起來的特色地圖厚度將會很大,所以為了避免這一現象提出的inception具有如下結構,在3x3前,5x5前,最大合併後分別加上了1x1的卷積核起到了降低特徵圖厚度的作用,這也使得雖然googlenet有22層但是引數個數要少於alexnet和vgg.inception的具體結構如圖2所示。


先簡單介紹到這裡,以後有時間還會詳細分析這兩篇論文,從上面可以看出VGG更友好,容易調節引數,但是googlenet就相對比較麻煩了,但是也還好,如果使用的話一般都有框架,但是想調節引數搞定原理才是正道,這裡就不詳細講了,有興趣的可以先看看,以後實戰時還會深入講解,下面就講解今天的主角RESNET。
RESNET
何凱明博士,廣東省高考狀元,進入清華。2007年清華大學畢業之後開始在微軟亞洲研究院(MSRA)實習,2011年香港中文大學博士畢業後正式加入MSRA,目前在Facebook人工智慧研究(FAIR)實驗室擔任研究科學家。曾以第一作者身份拿過兩次CVPR最佳論文獎(2009年和2016年) - 其中2016年CVPR最佳論文為影象識別中的深度殘差學習(對於法師識別的深度殘留學習)更是一鳴驚人下面我們就從背景講深度殘差網路:
“傳統”深度學習的困難
深度學習目前進展取決於技巧:初始權值選擇,區域性感受野,權值共享等等,但使用更深層的網路時(例如> 100),依然要面對反向傳播時梯度消失這類傳統困難,
退化問題:層數越多,訓練錯誤率與測試錯誤率反而升高

如何解決上面的問題呢?
深度殘差網路的思路
引入“捷徑”,可以防止梯度消失問題,其實在ResNet出來以前已經有人對這方面進行研究了,Srivastava等人的“公路網路”,“培訓非常深的網路”是類似的方法,他們認為更深層的網路應該也是易於優化的,層數越多準確率越高,訓練方法與“傳統”深度網路相比不會有很大變化,基於此,何凱明團隊提出了一個新的深度殘差網路,下面我們就先看看該網路的核心部分即:

上圖的左半部分是常規的神經網路形式,每層有權值和啟用函式,這裡的啟用函式採用的是RELU函式,目的是為了避免梯度消失的問題,右半部分是殘差網路的基本單元,和左邊最大的不同在於多了一個身份即多了一個直接到達輸出前的連線,這代表什麼意思呢?剛開始輸入的X,按照常規的神經網路進行權值疊加然後通過啟用函式,在次權值疊加後此時在把輸入的訊號和此時的輸出疊加然後在通過啟用函式,就是這樣的一個網路,而那條線稱為捷徑,也稱為高速公路,加這個高速公路有什用呢?這個殘差怎麼理解呢?大家可以這樣理解線上性擬閤中的殘差說的是資料點距離擬合直線的函式值的差,那麼這裡我們可以類比,這裡的X就是我們的擬合的函式,而H(x)的就是具體的資料點,那麼我通過訓練使的擬合的值加上F(x)的就得到具體資料點的值,因此這 F(x)的就是殘差了,還是畫個圖吧,如下圖:

下面我們看看整體的網路,然後通過數學說明的該網路的有效性:

大家通過上面的網路可以看到網路和VGG的對比一起看,VGG-19的學習原理基本上和常規卷積神經網路是一致的,不同的是他的卷積核的大小全是3×3的規模,池化層的大小為2x2規模,這樣的模型容易移植應用,而Resnet則是由很多層的高速通道,我們先從直覺中體會一下,我們從提取特徵的角度進行進行解釋一下,如果第一層是提取全域性特徵即淺特徵,深層提取的是深層特徵,我們這個高速公路可不可以說在每層進行輸出時,他是把深層特徵和淺層特徵結合在一起進行判斷呢?我們可以這麼理解的,那麼憑感覺告訴我們就是該網路通過淺層和深層結合判斷,同時梯度不容易消失,我們在把上面的圖片拿下來講解:

按理說上面的高速公路應該乘上權值會更好啊,但是為什麼係數為1呢?稍後用數學知識進行講解,現在我們來討論一下該網路是如何學習的,這個網路還是和卷積學習方法類似的,高速公路並不影響誤差反向傳播的,下面我們利用數學進行解釋:
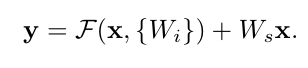
應該按理說有一個權值矩陣的,但是原始論文的直接為1,我們看看怎麼回事?
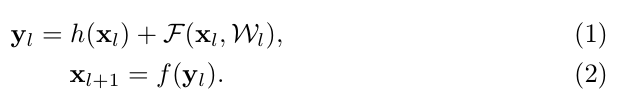
的這裡對映採用的的英文RELU規則,因此可以直接得到:

通過迭代:
![]()
我們可以寫成閉合的表示式:
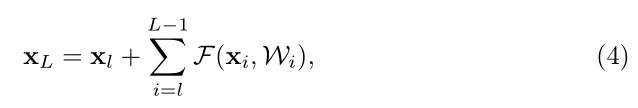
根據反向傳播的原理我們假設誤差為,對
其偏是什麼意思?導:
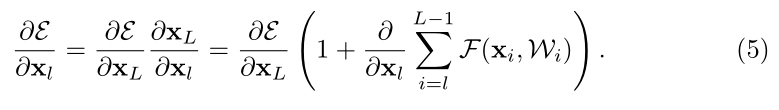
上式就我們誤差函式的反向傳播了,如果
![]()
此時:

代入(5)式中可得誤差反向傳播為:
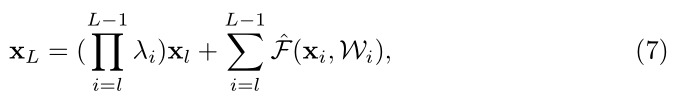
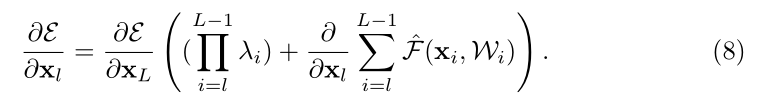
通過(8)我們式可以看到如何係數為大於1或者小於1時會造成梯度爆炸或消失的問題,因此直接為1是最好的,即(5)。他們也從資料中給出瞭解釋為什麼直接對映是最好的,我們來看看吧:

從上圖我們看到如果增加權值的,而且批量歸一化的位置不同,正確了也不同,他們倡導的是在RELU之前正則化比較,但是即使這樣還是有4.9%的錯誤率,而權值為1的是正確率為3.57%。好,到這裡就解釋了為什麼在高速公路是的X的權值為1,那麼大家有沒有疑問就是,為什麼高速高速公路只跨兩層呢?三層,四層不可以嗎其實都可以的,如果層數很多了,就可以使用更多的高速公路:如下圖

下面給出結構的部署:

這個表大家這樣看首先第一行表示不同層即18層,34層,50層,101層,152層這幾種RESNET結構,那麼這個層數怎麼計算呢?這裡以152層為例,同時說明一下,這裡的高速公路都是三層的,就是上圖右半邊的圖,因為深度太深,兩層計算量太大了,好我們看看他是怎麼計算層數的:(3 + 8 + 36 + 3)x3 = 150,再加兩層的全連線層就是152層了,這裡大家應該能看懂的,
好,這裡的RESNET就結束了,下一節我們看看的他的變種的網路。