
機器學習-3.資料特徵預處理與資料降維
阿新 • • 發佈:2018-12-15
- 特徵預處理定義:通過特定的統計方法(數學方法)將資料轉換成演算法要求的資料。
- 處理方法
- 數值型資料:標準縮放(1.歸一化,2.標準化);缺失值。
- 類別型資料:one-hot編碼。
- 時間型別:時間的切分。
- 預處理API:sklearn.preprocessing
一、特徵預處理
1. 歸一化
- 特點:通過對原始資料進行變換把資料對映到(預設為[0,1])之間
- 公式:
注:作用於每一列,max為一列的最大值,min為一列的最小值,那麼X’'為最終結果,mx,mi分別為指定區間值(預設mx為1,mi為0) - 歸一化API:sklearn.preprocessing.MinMaxScaler
- 示例:
from sklearn.preprocessing import MinMaxScaler
def minmaxscaler():
'''
歸一化處理
:return:None
'''
datalist = [[90, 2, 10, 40], [60, 4, 15, 45], [75, 3, 13, 46]]
mms = MinMaxScaler(feature_range=(0, 1)) # feature_range:制定縮放區間,預設為0到1
data = mms.fit_transform(datalist)
print(data)
return None
if __name__ == '__main__':
minmaxscaler()
- 輸出結果為:

- 為什麼要進行歸一化處理?
– 要使得某一個特徵對最終結果不會造成更大影響。一般在多個特徵對目標值的影響具有同樣重要的作用時進行歸一化。後期一般會根據演算法的要求是否進行歸一化,舉例:假設有三個特徵值,第一個樣本是:100,1.2,0.3;第二個樣本是 20,1.5,0.35;
大家都知道方差的公式中包含:(100-20)^2 + (1.2-1.5)^2 + (0.3-0.35)^2。這樣第一個特徵會非常明顯的對目標值具有更大的影響,因此需要進行歸一化處理。 - 歸一化的缺點:在某些特定場景下,最大值最小值是變化的,另外最大值和最小值非常容易受到異常點影響,所以這種方法魯棒性較差,只適合傳統精確小資料場景。
- 魯棒性定義:是健壯和強壯的意思。它是在異常和危險情況下系統生存的關鍵。所謂“魯棒性”,是指控制系統在一定(結構,大小)的引數攝動下,維持其它某些效能的特性。
2. 標準化
- 上面提到歸一化魯棒性較差,容易受到異常點的影響,標準化則解決這個問題。
- 特點:通過對原始資料進行變換,把資料變換到均值為0,標準差為1的範圍內。
- 公式:
- 注:作用於每一列,mean為平均值,σ為標準差
- 假設var為方差,
- 其中方差是考慮資料的穩定性。
- 對於歸一化來講,如果出現異常點,影響了最大值最小值,那麼結果顯然改變較大。
- 而對於標準化來講,如果出現異常點,因為具有一定量的資料,少量的異常點對於平均值的影響不大,因此方差改變較小,最終標準化改變也較小,因此大部分是採用標準化。
- API:sklearn.preprocessing.StandardScaler
- 示例:
from sklearn.preprocessing import StandardScaler
def standscaler():
'''
標準化處理
:return: None
'''
datalist = [[1,-1,3],[2,4,2],[4,6,-1]]
stand = StandardScaler()
data = stand.fit_transform(datalist)
print(data)
return None
if __name__ == '__main__':
standscaler()
- 輸出結果為:

- 標準化總結:在已有樣本足夠多的情況下比較穩定,適合現代嘈雜大資料場景。
3. 缺失值
- 缺失值的處理:
- 刪除:如果每列或者行資料缺失值達到一定的比例,建議放棄整行或者整列。
- 插補:可以通過缺失值每行或者每列的平均值、中位數來填充。
- API:sklearn.preprocessing.imputer
- 示例:
from sklearn.preprocessing import Imputer
import numpy as np
def im():
'''
缺失值處理
:return:None
'''
datalist = [[1,2],[np.nan,3],[7,6]]
im = Imputer(missing_values='NaN',strategy='mean',axis=0)
data = im.fit_transform(datalist)
print(data)
return None
if __name__ == '__main__':
im()
- 輸出結果如下:
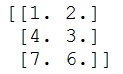
二、資料降維
- 降維,維度:指特徵的數量
- 通俗來講,就是因為有的特徵對目標值的預測沒有意義或者部分特徵的相關度高,容易消耗計算效能,所以需要特徵的選擇,也就是資料降維。
- 特徵選擇主要方法(三大武器):
- Filter(過濾式):VarianceThreshold(是通過計算方差進行的過濾,當存在很多個特徵值時,通過計算方差來分析每一個特徵值是否能很好的體現區分度,如果方差很小或者是0,那麼這樣的特徵值就不存在分析的價值了,一般可以用作預處理當中)
- Embedded(嵌入式):正則化、決策樹
- Wrapper(包裹式):不常用
- 對映方法(三大類)
- 線性對映方法:PCA(主成份分析)、LDA(線性判別分析,不常用)等
- 非線性對映方法:核方法:KPCA、KFDA等;二維化;流形學習:ISOMap、LLE、LPP等。
- 其他方法:神經網路和聚類
1. 特徵選擇-過濾式
- VarianceThreshold的API:sklearn.feature_selection.VarianceThreshold
- 示例:
from sklearn.feature_selection import VarianceThreshold
def var():
'''
特徵選擇-過濾式-過濾掉低方差的特徵
:return: None
'''
datalist = [[0,2,0,3],[0,1,4,3],[0,1,1,3]]
var = VarianceThreshold(threshold=0.0) # threshold指定閥值方差,指定1時則小於等於1的方差特徵都會刪除
data = var.fit_transform(datalist)
print(data)
return None
if __name__ == '__main__':
var()
- 輸出結果為:

由結果看出,第一個特徵和第四個特徵,方差均為0,因此被刪除掉了。
2. 對映方法-PCA(主成份分析)
- API:sklearn.decomposition
- 本質:PCA是一種分析、簡化資料集的技術
- 目的:使資料壓縮,儘可能降低原資料的維數(複雜度),損失少量資訊。
- 作用:可以消減迴歸分析或者聚類分析中特徵的數量。
- 通過一個例子來說明何為主成份分析:

- 如上圖所示,如何對一個立體物體進行二維表示
- 第一張圖明顯看不出是個什麼東西,第二張圖也一樣,第三張圖勉強能夠看出是個灑水壺但不明顯,第四張圖一眼就能看出來了。主成份分析就是如何通過低緯度表示出高緯度的資料並且主要特徵都不缺失。因此一般我們當特徵數量上百時會考慮資料的簡化,進行PCA操作,如果特徵只有幾個或幾十個一般是沒有必要去進行PCA操作的。PCA操作即會把資料改變,也會降低特徵數量。
- 簡易示例:
from sklearn.decomposition import PCA
def pca():
'''
主成份分析進行資料降維
:return: None
'''
datalist = [[2,8,4,5], [6,3,0,8], [5,4,9,1]]
pca = PCA(n_components=0.9) # n_components:可以是小數 0-1,小數代表資料保留百分之多少,根據經驗一般在90%-95%;可以是整數(一般不用),代表減少到的特徵數量
data = pca.fit_transform(datalist)
print(data)
return None
if __name__ == '__main__':
pca()
- 輸出結果如下:
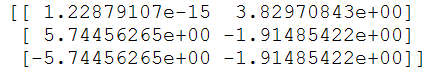
如上圖所示,通過pca處理,將原有的四個特徵,在制定保留90%資料時,降維到兩個特徵。
3. 特徵選擇與主成份分析如何選擇
- 一般特徵數量較多(過百)時採用主成份分析,較少時採用特徵選擇
4. 小結
- 至此,特徵工程三塊知識點:1. 特徵抽取;2. 特徵預處理;3. 資料降維。已經總結完畢,後期再穿插更深入的內容。