
機器學習特徵工程之特徵預處理
特徵預處理是什麼?
通過特定的統計方法(數學方法)講資料轉換成演算法要求的資料。
數值型資料:
- 歸一化
- 標準化
缺失值
類別型資料:one-hot編碼
時間型別:時間的切分
特徵選擇的意義
在對資料進行異常值、缺失值、資料轉換等處理後,我們需要從當前資料集中選出有意義的特徵,然後輸入到演算法模型中進行訓練。
對資料集進行特徵選擇主要基於以下幾方面的考慮:
1.冗餘的特徵會影響阻礙模型找尋資料潛在的規律,若冗餘的特徵過多,還會造成維度容災,佔用大量的時間空間,使演算法執行效率大打折扣。
2.去除不相關的特徵會降低學習任務的難度,保留關鍵的特徵更能直觀的看出資料潛在的規律。
那麼,該如何進行特徵選擇呢?通常,要從兩方面考慮來選擇特徵:
1.特徵是否具有發散性:
如果一個特徵不發散,例如方差接近於0,也就是說樣本在這個特徵上基本上沒有差異,這個特徵對於樣本的區分並沒有什麼用。
2.特徵與目標的相關性:
如果一個特徵不發散,例如方差接近於0,也就是說樣本在這個特徵上基本上沒有差異,這個特徵對於樣本的區分並沒有什麼用。
根據特徵選擇的標準,又能分為filter、wrapper、embedded三種方法。
歸一化

Scikit-learn歸一化處理API:sklearn。preprocession.MinMaxScaler

歸一化步驟:
1.例項化MinMaxScalar
2.通過fit_transform轉換
歸一化總結
在特定場景下最大值和最小值是變化的,另外,最大值個最小值非常容易受異常點影響,所以歸一化方法的穩定性較差,只適合傳統精確小資料場景。
標準化
特點:通過對原始資料進行變換把資料變化到均值為0,標準差為1範圍內。

結合歸一化來談標準化
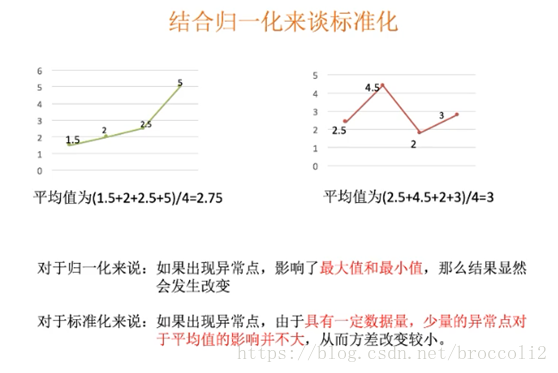
大多數使用標準化。
標準化API:scikit-learn.preprocessing.StandardScaler
目的:縮放資料。
StandardScaler語法

標準化步驟:
1.例項化StandardScaler
2.通過fit_transform轉換