Centos7.5搭建Hadoop2.8.5完全分散式叢集
一、基礎環境設定
1. 準備4臺客戶機(VMware虛擬機器)
系統版本:Centos7.5
192.168.208.128 ——Master
192.168.208.129 ——Slaver-1
192.168.208.130 ——Slaver-2
192.168.208.130 ——Slaver-3
2. 配置hosts檔案,使4臺客戶機能夠以主機名相互訪問
[[email protected] ~]# vi /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.208.128 Master
192.168.208.129 Slaver-1
192.168.208.130 Slaver-2
192.168.208.131 Slaver-3
# 將hosts檔案傳送給其它3臺客戶機
[ 3. 為4臺客戶機配置jdk環境
我們選擇配置jdk1.8.0_181,點選此處下載。
[[email protected] ~]# wget http://download.oracle.com/otn-pub/java/jdk/8u181-b13/96a7b8442fe848ef90c96a2fad6ed6d1/jdk-8u181-linux-x64.tar.gz
# 解壓
[ 4. 關閉防火牆,SELinux
a. iptables
# 臨時關閉
[[email protected] ~]# service iptables stop
# 禁止開機啟動
[[email protected] ~]# chkconfig iptables offb.firewalld
CentOS7版本後防火牆預設使用firewalld,預設是沒有iptables的,所以關閉防火牆的命令如下:
# 臨時關閉
[[email protected] ~]# systemctl stop firewalld
# 禁止開機啟動,輸出如下,則表示禁止成功
[[email protected] ~]# systemctl disable firewalld
Removed symlink /etc/systemd/system/multi-user.target.wants/firewalld.service.
Removed symlink /etc/systemd/system/dbus-org.fedoraproject.FirewallD1.service.c.關閉SELinux
# 永久關閉SELinux
[[email protected] ~]# vi /etc/selinux/config
#disabled - No SELinux policy is loaded.
SELINUX=disabled # 此處將SELINUX=enforcing改為SELINUX=disabled
# SELINUXTYPE= can take one of three two values:
# 修改SELinux配置後,需重啟客戶機才能生效
[[email protected] ~]# reboot
# 重啟之後,檢視SELinux狀態
[[email protected] ~]# /usr/sbin/sestatus
SELinux status: disabled # 如果輸出如是,則表示SELinux永久關閉成功5. 設定SSH免金鑰
關於ssh免密碼的設定,要求每兩臺主機之間設定免密碼,自己的主機與自己的主機之間也要求設定免密碼。在這裡,為了避免後面的各種許可權問題,我們直接使用root賬戶來設定面金鑰登陸。
[[email protected] ~]$ ssh-keygen -t rsa
[[email protected] ~]$ ssh-copy-id node-1
[[email protected] ~]$ ssh-copy-id node-2
[[email protected] ~]$ ssh-copy-id node-3注:每一臺客戶機都要做如上設定,所以,最好的方式是:按上述方法配置好一臺虛擬機器之後,再克隆出其它幾臺。
二、安裝hadoop叢集
1. 下載hadoop2.8.5二進位制檔案
2. hadoop安裝目錄
為了統一管理,我們將hadoop的安裝路徑定為/usr/opt/hadoop下,建立目錄後,我們將hadoop二進位制檔案解壓至這個目錄下。
3. 配置core-site.xml
hadoop的配置檔案,在/opt/hadoop/hadoop-2.8.5/etc/hadoop下,
[[email protected] ~]# cd /opt/hadoop/hadoop-2.8.5/etc/hadoop
[[email protected] hadoop]# vi core-site.xml<configuration>
<!--配置hdfs檔案系統的名稱空間-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://Master:9000</value>
</property>
<!-- 配置操作hdfs的存衝大小 -->
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
<!-- 配置臨時資料儲存目錄 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop/hadoop-2.8.5/tmp</value>
</property>
</configuration>
4. 配置hdfs-site.xml
[[email protected] hadoop]# vim hdfs-site.xml<configuration>
<!--配置副本數-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--hdfs的元資料儲存位置-->
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/hadoop/hadoop-2.8.5/hdfs/name</value>
</property>
<!--hdfs的資料儲存位置-->
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/hadoop/hadoop-2.8.5/hdfs/data</value>
</property>
<!--hdfs的namenode的web ui 地址-->
<property>
<name>dfs.http.address</name>
<value>Master:50070</value>
</property>
<!--hdfs的snn的web ui 地址-->
<property>
<name>dfs.secondary.http.address</name>
<value>Master:50090</value>
</property>
<!--是否開啟web操作hdfs-->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<!--是否啟用hdfs許可權(acl)-->
<property>
<name>dfs.permissions</name>
<value>false</value> </property>
</configuration>5. 配置mapred-site.xml
[[email protected] hadoop]# cp mapred-site.xml.template mapred-site.xml
[[email protected] hadoop]# vim mapred-site.xml<configuration>
<!--指定maoreduce執行框架-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value> </property>
<!--歷史服務的通訊地址-->
<property>
<name>mapreduce.jobhistory.address</name>
<value>Master:10020</value>
</property>
<!--歷史服務的web ui地址-->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>Master:19888</value>
</property>
</configuration>
6. 配置yarn-site.xml
[[email protected] hadoop]# vim yarn-site.xml<configuration>
<!-- Site specific YARN configuration properties -->
<!--指定resourcemanager所啟動的伺服器主機名-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>Master</value>
</property>
<!--指定mapreduce的shuffle-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--指定resourcemanager的內部通訊地址-->
<property>
<name>yarn.resourcemanager.address</name>
<value>Master:8032</value>
</property>
<!--指定scheduler的內部通訊地址-->
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>Master:8030</value>
</property>
<!--指定resource-tracker的內部通訊地址-->
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>Master:8031</value>
</property>
<!--指定resourcemanager.admin的內部通訊地址-->
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>Master:8033</value>
</property>
<!--指定resourcemanager.webapp的ui監控地址-->
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>Master:8088</value>
</property>
</configuration>7. 配置slaves檔案
[[email protected] hadoop]# vim slavesMaster
Slaver-1
Slaver-2
Slaver-38. 配置hadoop-env.sh,指定JAVA_HOME
[[email protected] hadoop]# vim hadoop-env.sh
修改 export JAVA_HOME=/usr/local/java/jdk1.8.0_1819. 配置yarn-env.sh,指定JAVA_HOME
[[email protected] hadoop]# vim yarn-env.sh
修改 export JAVA_HOME=/usr/local/java/jdk1.8.0_18110. 配置mapred-env.sh,指定JAVA_HOME
[[email protected] hadoop]# vim mapred-env.sh
修改 export JAVA_HOME=/usr/local/java/jdk1.8.0_18111. 將hadoop檔案分發到其它幾臺客戶機上
[[email protected] hadoop]# scp -r hadoop/ Slaver-1:`pwd`
[[email protected] hadoop]# scp -r hadoop/ Slaver-2:`pwd`
[[email protected] hadoop]# scp -r hadoop/ Slaver-3:`pwd`三、啟動並驗證hadoop叢集
1. 啟動叢集
第一次啟動叢集,需要格式化namenode,操作如下:
[[email protected] ~]# hdfs namenode -format輸出如下內容,則表示格式化成功

啟動HDFS
格式化成功之後,我們就可以啟動HDFS了,命令如下:
[[email protected] hadoop]# start-dfs.sh
Starting namenodes on [Master]
Master: starting namenode, logging to /opt/hadoop/hadoop-2.8.5/logs/hadoop-root-namenode-Master.out
Slaver-3: starting datanode, logging to /opt/hadoop/hadoop-2.8.5/logs/hadoop-root-datanode-Slaver-3.out
Slaver-2: starting datanode, logging to /opt/hadoop/hadoop-2.8.5/logs/hadoop-root-datanode-Slaver-2.out
Slaver-1: starting datanode, logging to /opt/hadoop/hadoop-2.8.5/logs/hadoop-root-datanode-Slaver-1.out
Starting secondary namenodes [Master]
Master: starting secondarynamenode, logging to /opt/hadoop/hadoop-2.8.5/logs/hadoop-root-secondarynamenode-Master.out啟動Yarn
啟動Yarn時需要注意,我們不能在NameNode上啟動Yarn,而應該在ResouceManager所在的主機上啟動。但我們這裡是將NameNode和ResouceManager部署在了同一臺主機上,所以,我們直接在Master這臺機器上啟動Yarn。
[[email protected] hadoop]# start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /opt/hadoop/hadoop-2.8.5/logs/yarn-root-resourcemanager-Master.out
Slaver-2: starting nodemanager, logging to /opt/hadoop/hadoop-2.8.5/logs/yarn-root-nodemanager-Slaver-2.out
Slaver-1: starting nodemanager, logging to /opt/hadoop/hadoop-2.8.5/logs/yarn-root-nodemanager-Slaver-1.out
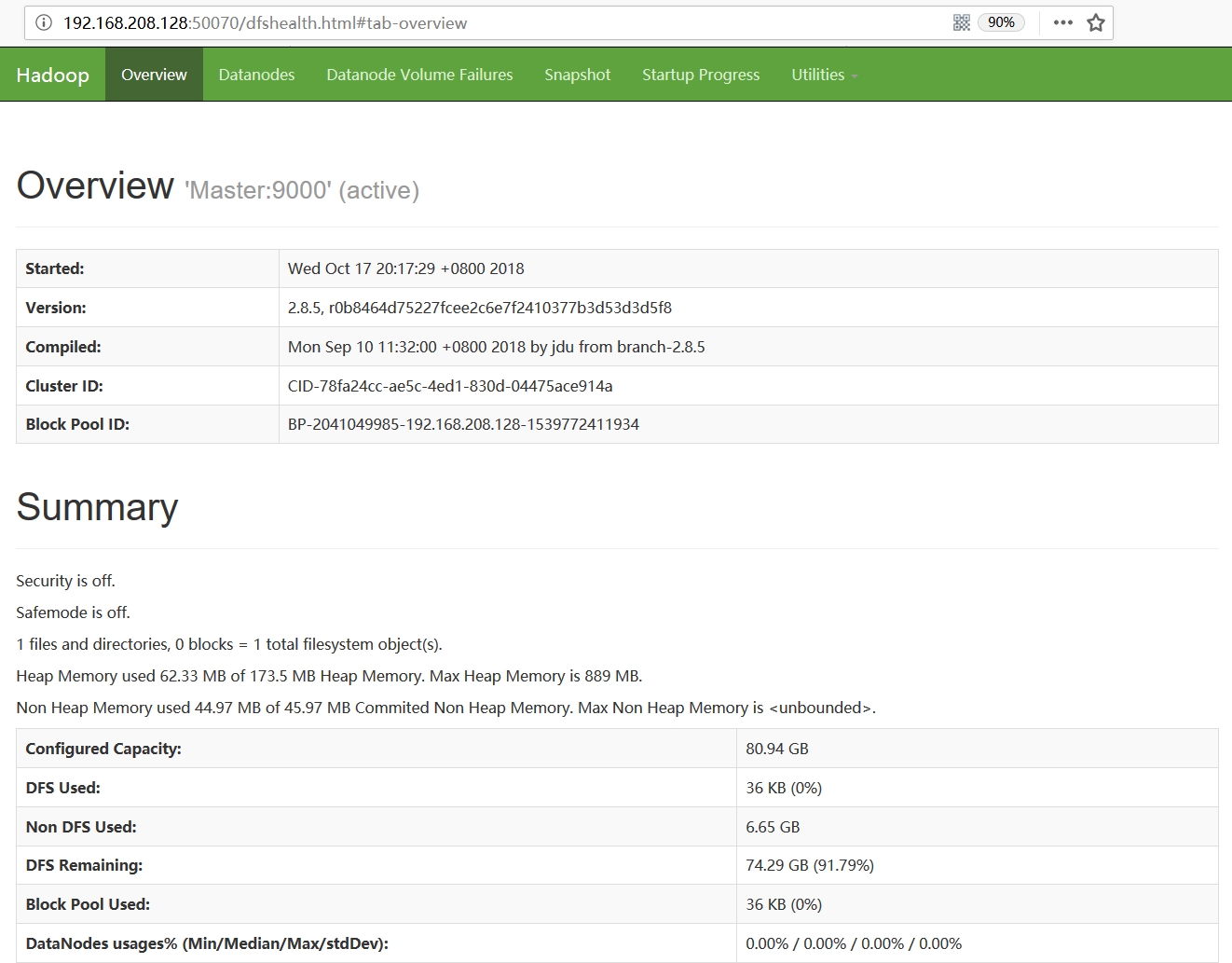
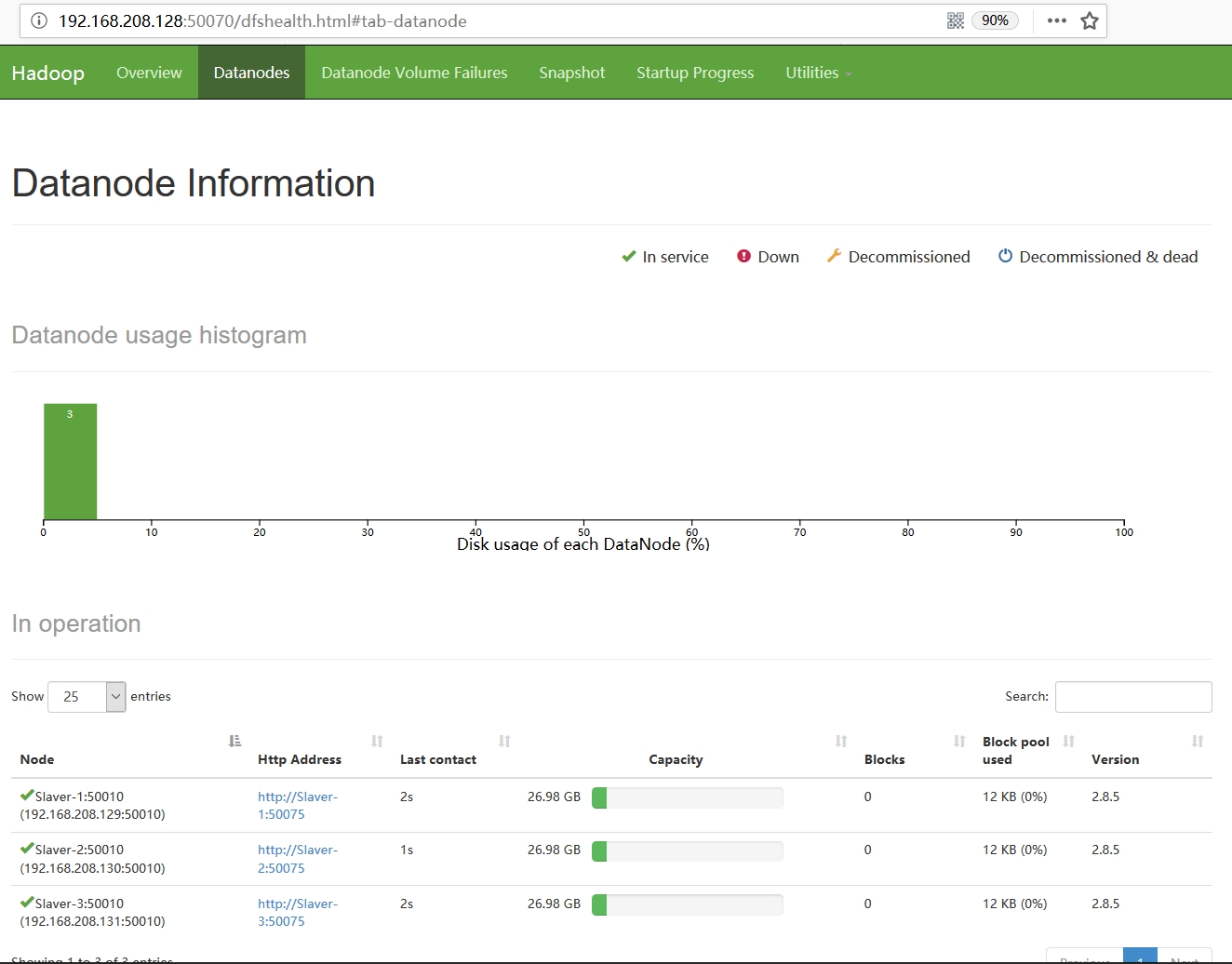
Slaver-3: starting nodemanager, logging to /opt/hadoop/hadoop-2.8.5/logs/yarn-root-nodemanager-Slaver-3.out2. web驗證
至此,我們的叢集就已完全啟動起來了,我們可以通過訪問web頁面,來做最後一步驗證。我們已將web頁面配置在Master主機上,因此,我們訪問http://192.168.208.128:50070/,頁面顯示如下: