
HBase的架構及設計
一.初識HBase
HBase其實就是Hadoop的database,它是一種分散式的,面向列的開源資料庫,類似 Google Bigtable 利用 GFS 作為其檔案儲存系統,HBase 利用 Hadoop HDFS 作為其檔案儲存系統;Google 執行 MapReduce 來處理 Bigtable 中的海量資料,HBase 同樣利用 Hadoop MapReduce 來處理 HBase 中的海量資料;Google Bigtable 利用 Chubby 作為協同服務,HBase 利用 Zookeeper 作為對應。,目前是Apache的頂級專案,它不同於一般的關係型資料庫,適合儲存半結構化的資料
Hbase一般具有以下特點:
(1)線性擴充套件:當儲存空間不足時,可以通過簡單的增加節點的方式進行擴充套件——通過增加 RegionServer 進行擴充套件,而且只需要將它可以放到普通的伺服器中即可。
(2)面向列:與關係型資料庫——諸如Mysql不同的是,HBase面向列族來儲存資料,即同一個列族裡的資料在邏輯上儲存在同一個檔案中。
(3)大表:百萬級甚至億級的行和列。
(4)稀疏:列可以動態增加,由於資料的多樣性,整體上會有非常多的列,但每一行資料可能只對應少數的列,一般情況下,一行資料中,只有少數的列有值,HBase並不儲存,因此表可以設計地非常稀疏。
(5)面向海量資料:
(6)高讀寫場景:HBase適合批量大資料高速寫入資料庫。
二.HBase表檢視
1.概念檢視
一般關係型資料:列的屬性在使用前定義好,而行可以動態擴充套件。
HBase:列族必須在使用前定義好,列,時間戳和行都能動態擴充套件。

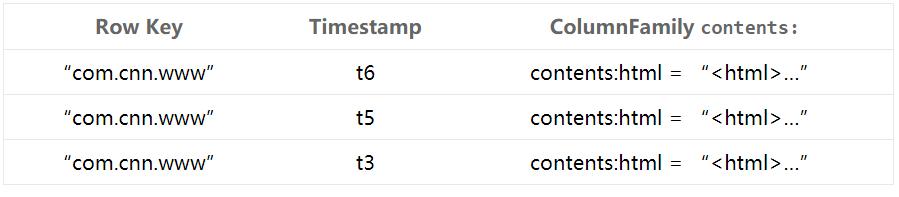
Table(表):HBase table由多個row組成。
Row(行):每一row代表著一個數據物件,每一row都是以一個rowkey(行鍵)和一個或者多個column組成。rowkey是每個資料物件的唯一標識的,按字母順序排序,即row也是按照這個順序來進行儲存的。所以,rowkey的設計相當重要(rowkey設計學問之深我都感覺可以專門搞一個學科來研究了
Column(列):column由column family和column qualifier組成,由冒號(:)進行進行間隔。比如family:qualifier。
Column Family(列族):在 HBase,column family是一些column的集合。一個column family所有column成員是有著相同的字首。比如,courses:history和courses:math都是courses的成員。冒號(:)是column family的分隔符,用來區分字首和列名。column字首必須是可列印的字元,剩下的部分列名可以是任意位元組陣列。column family必須在table建立的時候宣告。column隨時可以新建。在邏輯上,一個的column family成員在檔案系統上都是儲存在一起。因為儲存優化都是針對column family級別的,這就意味著,一個column family的所有成員的是用相同的方式訪問的。
Column Qualifier(列限定符):column family中的資料通過column qualifier來進行對映。column qualifier也沒有特定的資料型別,以二進位制位元組來儲存。比如某個column family “content”,其 column qualifier可以設定為"content:html" 和 "content:pdf"。雖然column family是在table建立時就固定了,但column qualifier是可變的,可能在不同的row之間有很大不同。
Cell(單元格):cell是row、column family和column qualifier的組合,包含了一個值和一個timestamp,用於標識值的版本。
Timestamp(時間戳):每個值都會有一個timestamp,作為該值特定版本的識別符號。預設情況下,timestamp代表了當資料被寫入RegionServer的時間,但你也可以在把資料放到cell時指定不同的timestamp。
2.物理檢視

三.HBase物理儲存模型
HBase的底層實現如下圖所示:

它由相關服務和檔案組成 ,HBase主要有兩種檔案——WAL和Hfile,由於它們均以HDFS作為底層實現,在實際的儲存中,會劃分成更小的檔案塊——因此,我們無從得知,也沒有那個精力及必要去思考某張表具體儲存在哪些datanode中。
1.Client
客戶端用於提交管理或讀寫請求,採用RPC與HMaster和HRegionserver進行通訊。它還會快取查詢資訊,這樣如果隨後有相似的請求,可以直接通過快取定位,而不用再次查詢meta表。
2.Zookeeper
為HBase提供協同管理服務,當HRegionserver上線時會將自己註冊到Zookeeper中——起到監控的作用,當某個HRegionserver死掉時,能及時通知HMaster進行處理。Zookeeper提供目錄表的位置——hbase:meta,此表同樣按照rowkey排序——我們在找到一個rowkey時,就能找到相鄰的rowkey,篇幅有限,這裡就不詳細介紹hbase:meta表結構了。
3.HMaster
在實際的叢集中,該程序多執行在namenode中 ,它負責監控HRegionserver:
(1)操作表
(2)分配新的Region
(3)HRegionserver掛掉之後重新為Region分配HRegionserver(不一定是在原HRegionserver)
HBase同樣可以實現多HMaster,但同一時刻只能有一個HMaster處於活躍狀態——當某個HMaster突然暴斃或者租期到了(當該HMaster被啟用時,Zookeeper會給它一個租期)之時,就會啟動另一個HMaster。
4.HRegionserver
它負責參與具體的Region的管理,直接響應客戶端的讀寫請求,HRegionserver執行在datanode,一般來說一個datanode執行一個HRegionserver。
5.HRegion
HRegion是對錶進行劃分的基本單元,一個表在建立的時候只有一個Region,但隨著記錄地增加會越來越大,到達某個閾值之後會被Split——按行健進行劃分——每個Region包含表的所有列族——某一行的資料完全可以在某個Region中全部獲取——但是預設的切分常常會產生資料傾斜,實際開發中採用預分割槽的方式。Split之後,HMaster會重新分配HRegionserver,然後更新Hbase:meta表。
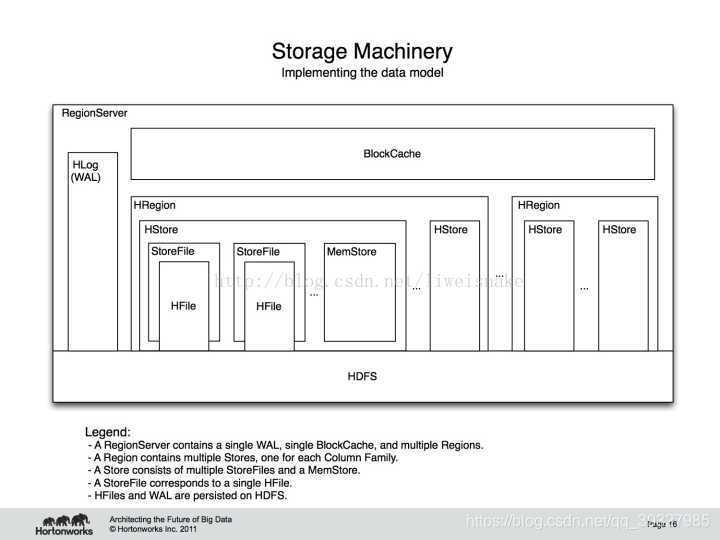
(1)HStore
每一個HRegion包含若干Stores,每個Store對應一個HBase表中的列族——面向列族進行儲存這一說法就是來源於此,一個表足夠大時,會被劃分成若干Split,每個Split對應一個Region。
關於Region的切分細節如下:
在HBase0.94版本~2.0版本IncreasingToUpperBoundRegionSplitPolicy 是預設的split策略,這個策略中,最小的分裂大小和table的某個region server的region 個數有關,當store file的大小大於如下公式得出的值的時候就會split,公式如下:
Min (R^2 * “hbase.hregion.memstore.flush.size”, “hbase.hregion.max.filesize”) R為同一個table中在同一個region server中region的個數。

hbase.hregion.memstore.flush.size

hbase.hregion.max.filesize hbase.hregion.memstore.flush.size 預設值 128MB。
hbase.hregion.max.filesize預設值為10GB 。
如果初始時R=1,那麼Min(128MB,10GB)=128MB,也就是說在第一個flush的時候就會觸發分裂操作。
當R=2的時候Min(2*2*128MB,10GB)=512MB ,當某個store file大小達到512MB的時候,就會觸發分裂。
如此類推,當R=9的時候,store file 達到10GB的時候就會分裂,也就是說當R>=9的時候,store file 達到10GB的時候就會分裂。
Store的儲存過程是HBase儲存的核心過程,每個Store包含一個MemStore(記憶體中的快取)和若干StoreFiles(磁碟上的檔案HFile)。當在HBae中插入資料時,會先存到MemStore中;查詢資料時也會先從MemStore檢視,找不到時再到HFile中查詢,若在HFile中找到了結果,會將結果快取到MemStore中,當MemStore中的資料到達閾值時,會執行Flush操作,將MemStore寫成一個單獨的StoreFile,當StoreFile到達一定個數時,會觸發Compact操作——合併為一個大的StoreFile。
(2)合併
StoreFile的合併有兩種方式,分別是minor和major。minor時把最新生成的幾個StoreFile進行合併,每次進行Flush操作之後,都會觸發合併,或者由單獨的程序定期觸發合併檢查。minor合併的檔案由以下四個引數決定:
hbase.hstore.compaction.min 最小檔案合併數 必須大於1 預設是3
hbase.hstore.compaction.max 最大檔案合併數 預設是10
hbase.hstore.compaction.min.size 最小合併檔案大小 設定為Flush的閾值
hbase.hstore.compaction.max.size 最大合併檔案大小

hbase.hstore.compaction.max
合併檢查時,會檢視當前的StoreFile是否符合條件。最小合併檔案數不要設定的太大,這樣不僅會延遲minor合併操作,還會增加每次合併時的資源消耗和執行時間。最小合併檔案大小設定為MenStore Flush的閾值,這樣每個新生成的StoreFile都符合條件,因為設定了最大合併檔案的大小,當合並後的檔案大於這個大小時,那麼再執行合併檢查就會被排除在外,這樣設計的好處是,每次進行minor合併的檔案都是比較新和比較小的檔案。
major合併是把所有的StoreFile合併成一個單獨的StoreFile,進行合併檢查時會事先檢查從上次執行major合併到現在是否達到hbase.hregion.majorcompaction制定的閾值(我看的那本書上是24h,但我查的官網7天),若達到這個時間,則進行major合併操作。

hbase.hregion.majorcompaction
除了由Flush之後和執行緒定期地觸發合併檢查之外,還可以有相應的shell命令(compact,major_compact)和API(majorCompact())觸發。
Flush觸發條件:
1.Regionserver全域性的memstore大小,超過該大小會觸發Flush,預設為heap的40%。

hbase.regionserver.global.memstore.size 2.記憶體中的檔案在自動重新整理之前能夠存活的最長時間,預設為1h。

hbase.regionserver.optionalcacheflushinterval
3.單個Region裡的menstore的快取大小,預設為128M
hbase.hregion.memstore.flush.size
(3)修改和刪除記錄
HBase中修改和刪除操作均是以追加的形式執行的,並不會立即定位到該檔案進行相應操作。修改和刪除操作均是新增一行新的紀錄,修改操作就是新增一行新版本地資料,刪除則是在所新增的記錄上打上了刪除標記,表示要刪除某條記錄,這些操作均會先存入MemStore,Flush侯成為StoreFile,在StoreFile合併時,同時對資料版本進行合併,捨棄多餘的資料版本和具有刪除標記的記錄。
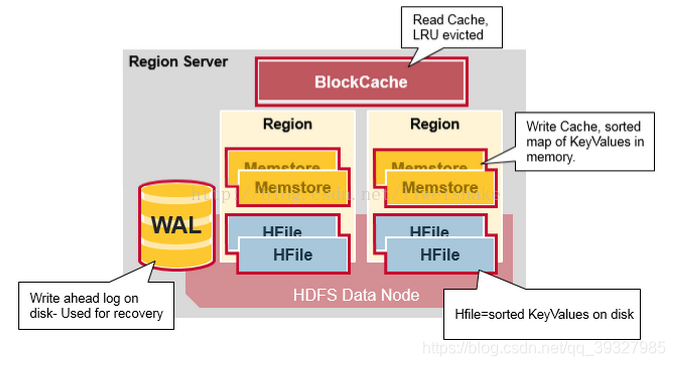
6.WAL
WAL是HBase的預寫日誌檔案——對應於磁碟中實際儲存為HLogFile,記錄使用者對資料的所有操作,儲存在/hbase/WALs目錄中,它的存在是為了防止HRegionserver突然死掉之後MenStore中資料出現丟失——使用者在寫入操作時,記錄會由RegionServer先行寫入WAL中,由圖可以看出,某個RegionSever中的WAL被該RegionSever中所有的Region共享,對比同時寫入多個檔案而言,減少了機械硬碟的定址次數,加快了資料的處理素速度,但這樣看來也有一個不可忽視的缺點——當恢復資料時,需要為WAL中"亂成一團"的記錄"找到自己的家"(即我這條記錄作用於哪條Region)——因此,每一行記錄在寫入之前都應該附帶自己的"家庭地址",不然我咋知道你住哪兒。HLogFile每個儲存單元均包含兩部分——HLogKey和KeyValue,HLogKey中記錄了寫入資料所隸屬的表(Table)以及Region寫入時間(TimeStamp)及序列編號;KeyValue則對應StoreFile的實體記憶體HFile中的KeyValue元資料。
四.HBase讀寫流程
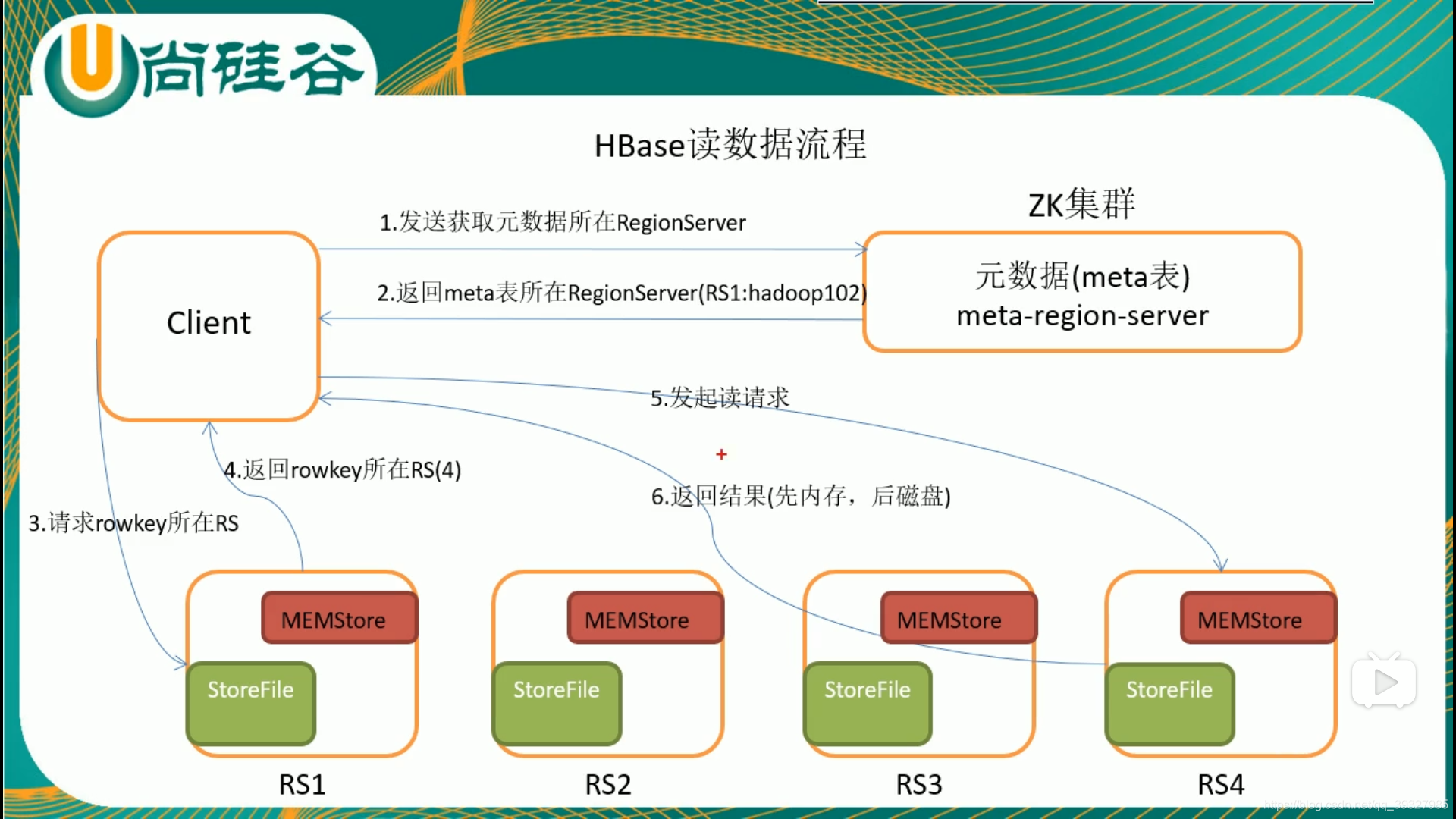
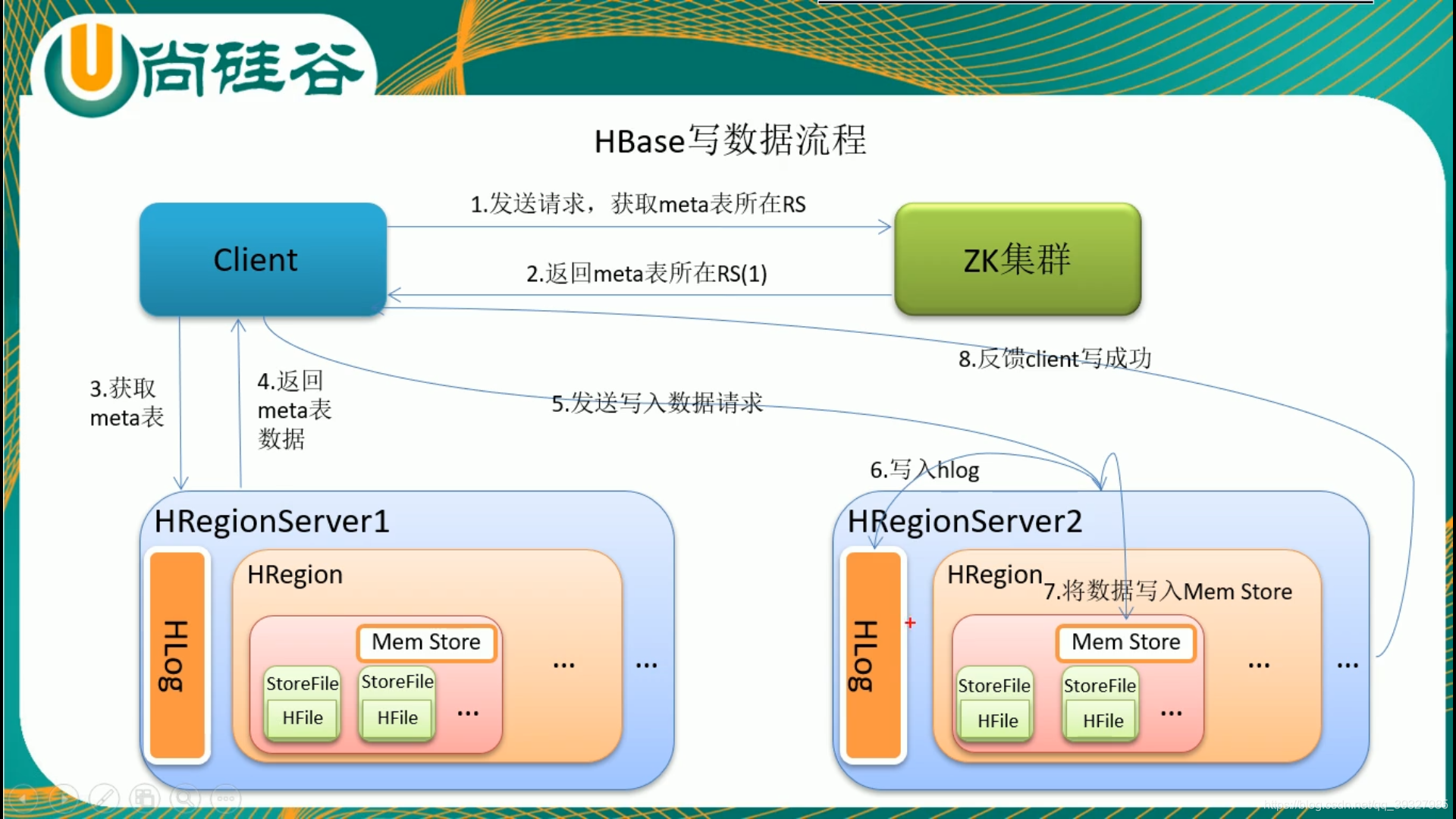
由於memstore的存在,HBase的寫會比讀快。
參考:《Hadoop大資料 處理技術基礎與實踐》
https://blog.csdn.net/liweisnake/article/details/78086262
http://www.importnew.com/21958.html
https://www.cnblogs.com/niurougan/p/3976519.html
部分圖片來源: https://blog.csdn.net/liweisnake/article/details/78086262
http://www.importnew.com/21958.html
某知名培訓機構