
Spark學習(拾)- Spark Streaming進階與案例實戰
實戰之updateStateByKey運算元的使用
updateStateByKey操作允許您在使用新資訊不斷更新狀態的同時維護任意狀態。要使用它,您需要執行兩個步驟。
1、定義狀態——狀態可以是任意資料型別。
2、定義狀態更新函式——用函式指定如何使用以前的狀態和輸入流中的新值更新狀態。
在每個批處理中,Spark將為所有現有鍵應用狀態更新功能,而不管它們是否在批處理中有新資料。如果update函式不返回任何值,那麼鍵-值對將被消除。
讓我們用一個例子來說明這一點。
需求:統計到目前為止累積出現的單詞的個數(需要保持住以前的狀態)
package com.imooc. Checkpointing
流應用程式必須全天候執行,因此必須能夠適應與應用程式邏輯無關的故障(例如,系統故障、JVM崩潰等等)。為了實現這一點,Spark流需要將足夠的資訊檢查點到容錯儲存系統,以便能夠從故障中恢復。有兩種型別的資料是檢查點。
- Metadata checkpointing——將定義流計算的資訊儲存到容錯儲存(如HDFS)。它用於從執行流應用程式驅動程式的節點的故障中恢復(稍後將詳細討論)。元資料包括:
- Configuration——用於建立流應用程式的配置。
- DStream operations——定義流應用程式的DStream操作集。
- Incomplete batches—作業已排隊但尚未完成的批處理。
- Data checkpointing——將生成的RDDs儲存到可靠的儲存中。在一些跨多個批處理組合資料的有狀態轉換中,這是必要的。在這種轉換中,生成的rdd依賴於前幾個批次的rdd,這使得依賴鏈的長度隨著時間的推移而不斷增加。為了避免恢復時間的無界增長(與依賴鏈成比例),有狀態轉換的中間rdd定期檢查可靠儲存(例如HDFS),以切斷依賴鏈。
總之,元資料檢查點主要用於從驅動程式故障中恢復,而資料或RDD檢查點甚至對於使用有狀態轉換的基本功能也是必要的。
何時啟用檢查點
必須為有下列任何要求的應用程式啟用檢查點:
- 有狀態轉換的使用——如果在應用程式中使用updateStateByKey或reduceByKeyAndWindow(具有逆函式),那麼必須提供檢查點目錄來允許週期性的RDD檢查點。
- 從執行應用程式的驅動程式的故障中恢復——元資料檢查點用於恢復進度資訊。
注意,沒有上述有狀態轉換的簡單流應用程式可以在不啟用檢查點的情況下執行。在這種情況下,從驅動程式故障中恢復也是部分的(一些接收到但未處理的資料可能會丟失)。這通常是可以接受的,許多人以這種方式執行Spark流應用程式。對非hadoop環境的支援有望在未來得到改進。
如何配置請參考官網
http://spark.apache.org/docs/2.2.0/streaming-programming-guide.html#how-to-configure-checkpointing
實戰之將統計結果寫入到MySQL資料庫中
需求:計算到目前為止累積出現的單詞個數寫入到MySQL
新增依賴:
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.38</version>
</dependency>
編寫:
需求:將統計結果寫入到MySQL
create table wordcount(
word varchar(50) default null,
wordcount int(10) default null
);
通過該sql將統計結果寫入到MySQL
insert into wordcount(word, wordcount) values(’" + record._1 + “’,” + record._2 + “)”
package com.imooc.spark
import java.sql.DriverManager
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* 使用Spark Streaming完成詞頻統計,並將結果寫入到MySQL資料庫中
*/
object ForeachRDDApp {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setAppName("ForeachRDDApp").setMaster("local[2]")
val ssc = new StreamingContext(sparkConf, Seconds(5))
val lines = ssc.socketTextStream("localhost", 6789)
val result = lines.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _)
//result.print() //此處僅僅是將統計結果輸出到控制檯
//TODO... 將結果寫入到MySQL(以下程式碼會報錯)
// 這是不正確的,因為這需要將連線物件序列化並從驅動程式傳送到工作程式。這樣的連線物件很少能夠跨機器進行傳輸。此錯誤可能表現為序列化錯誤
// result.foreachRDD(rdd =>{
// val connection = createConnection() // executed at the driver
// rdd.foreach { record =>
// val sql = "insert into wordcount(word, wordcount) values('"+record._1 + "'," + record._2 +")"
// connection.createStatement().execute(sql)
// }
// })
result.print()
result.foreachRDD(rdd => {
rdd.foreachPartition(partitionOfRecords => {
val connection = createConnection()
partitionOfRecords.foreach(record => {
val sql = "insert into wordcount(word, wordcount) values('" + record._1 + "'," + record._2 + ")"
connection.createStatement().execute(sql)
})
connection.close()
})
})
ssc.start()
ssc.awaitTermination()
}
/**
* 獲取MySQL的連線
*/
def createConnection() = {
Class.forName("com.mysql.jdbc.Driver")
DriverManager.getConnection("jdbc:mysql://localhost:3306/imooc_spark", "root", "root")
}
}
存在的問題:
-
對於已有的資料做更新,而是所有的資料均為insert
改進思路:
a) 在插入資料前先判斷單詞是否存在,如果存在就update,不存在則insert
b) 工作中:HBase/Redis -
每個rdd的partition建立connection,建議大家改成連線池
foreachrdd的操作官方詳解:
http://spark.apache.org/docs/2.2.0/streaming-programming-guide.html#design-patterns-for-using-foreachrdd
實戰之視窗函式的使用
window:定時的進行一個時間段內的資料處理
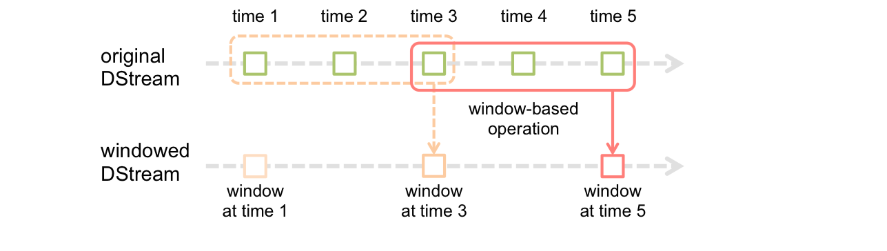
Spark流還提供了視窗計算,允許您在滑動的資料視窗上應用轉換。上圖演示了這個滑動視窗。
如圖所示,每當視窗滑過源DStream時,位於該視窗內的源rdd被組合起來並對其進行操作,從而生成視窗化DStream的rdd。在這個特定的例子中,操作應用於過去3個時間單元的資料,並以2個時間單元進行幻燈片演示。這表明任何視窗操作都需要指定兩個引數。
- window length視窗長度-視窗的持續時間。
- sliding interval滑動間隔-執行視窗操作的間隔。
這兩個引數必須是源DStream批處理間隔的倍數。
讓我們用一個例子來說明視窗操作。例如,您希望通過在最後30秒的資料中每10秒生成單詞計數來擴充套件前面的示例。為此,我們必須在過去30秒的資料中對(word, 1)鍵值對的DStream應用reduceByKey操作。這是使用reduceByKeyAndWindow操作完成的。
// Reduce last 視窗長度30 seconds of data, every 滑動間隔10 seconds
//這2個引數和我們的batch size有關係:倍數
val windowedWordCounts = pairs.reduceByKeyAndWindow((a:Int,b:Int) => (a + b), Seconds(30), Seconds(10))
一些常見的視窗操作如下。所有這些操作都使用上述兩個引數——windowLength和slideInterval
| Transformation | Meaning |
|---|---|
| window(windowLength, slideInterval) | 返回一個新的DStream,它是根據源DStream的視窗批次計算的。 |
| countByWindow(windowLength, slideInterval) | 返回流中元素的滑動視窗數。 |
| reduceByWindow(func, windowLength, slideInterval) | 返回一個新的單元素流,通過使用func在滑動間隔內聚合流中的元素而建立。該函式應該是關聯的和可交換的,以便可以並行正確計算。 |
| reduceByKeyAndWindow(func, windowLength, slideInterval, [numTasks]) | 當在(K,V)對的DStream上呼叫時,返回(K,V)對的新DStream,其中使用給定的reduce函式func 在滑動視窗中的批次聚合每個鍵的值。注意:預設情況下,這使用Spark的預設並行任務數(本地模式為2,在群集模式下,數量由config屬性確定spark.default.parallelism)進行分組。您可以傳遞可選 numTasks引數來設定不同數量的任務。 |
| reduceByKeyAndWindow(func, invFunc, windowLength, slideInterval, [numTasks]) | 上述更有效的版本,reduceByKeyAndWindow()其中使用前一視窗的reduce值逐步計算每個視窗的reduce值。這是通過減少進入滑動視窗的新資料,並“反向減少”離開視窗的舊資料來完成的。一個例子是當視窗滑動時“新增”和“減去”鍵的計數。但是,它僅適用於“可逆減少函式”,即那些具有相應“反向減少”函式的減函式(作為引數invFunc)。同樣reduceByKeyAndWindow,reduce任務的數量可通過可選引數進行配置。請注意,必須啟用檢查點才能使用此操作。 |
| countByValueAndWindow(windowLength, slideInterval, [numTasks]) | 當在(K,V)對的DStream上呼叫時,返回(K,Long)對的新DStream,其中每個鍵的值是其在滑動視窗內的頻率。同樣 reduceByKeyAndWindow,reduce任務的數量可通過可選引數進行配置。 |
需求:每隔多久計算某個範圍內的資料:每隔10秒計算前30分鐘的wc
==> 每隔sliding interval統計前window length的值
只是運算元的不同;其他都是和上面程式碼邏輯一樣的。
實戰之黑名單過濾
訪問日誌 ==> DStream
20180808,zs
20180808,ls
20180808,ww
==> (zs: 20180808,zs)(ls: 20180808,ls)(ww: 20180808,ww)
黑名單列表 ==> RDD
zs
ls
==>(zs: true)(ls: true)
==> 20180808,ww
leftjoin
(zs: [<20180808,zs>, ]) x
(ls: [<20180808,ls>, ]) x
(ww: [<20180808,ww>, ]) ==> tuple 1
package com.imooc.spark
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* 黑名單過濾
*/
object TransformApp {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
/**
* 建立StreamingContext需要兩個引數:SparkConf和batch interval
*/
val ssc = new StreamingContext(sparkConf, Seconds(5))
/**
* 構建黑名單
*/
val blacks = List("zs", "ls")
val blacksRDD = ssc.sparkContext.parallelize(blacks).map(x => (x, true))
val lines = ssc.socketTextStream("localhost", 6789)
val clicklog = lines.map(x => (x.split(",")(1), x)).transform(rdd => {
rdd.leftOuterJoin(blacksRDD)
.filter(x=> x._2._2.getOrElse(false) != true)
.map(x=>x._2._1)
})
clicklog.print()
ssc.start()
ssc.awaitTermination()
}
}
實戰之Spark Streaming整合Spark SQL操作
您可以輕鬆地在流資料上使用DataFrames和SQL操作。您必須使用StreamingContext使用的SparkContext建立一個SparkSession。此外,這樣做可以在驅動程式失敗時重新啟動。這是通過建立一個延遲例項化的SparkSession單例例項來實現的。如下面的例子所示。它修改了前面的單詞計數示例,以使用DataFrames和SQL生成單詞計數。每個RDD都被轉換為一個DataFrame,註冊為一個臨時表,然後使用SQL查詢。
<!-- Spark SQL 依賴-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
package com.imooc.spark
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.SparkSession
import org.apache.spark.streaming.{Seconds, StreamingContext, Time}
/**
* Spark Streaming整合Spark SQL完成詞頻統計操作
*/
object SqlNetworkWordCount {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setAppName("ForeachRDDApp").setMaster("local[2]")
val ssc = new StreamingContext(sparkConf, Seconds(5))
val lines = ssc.socketTextStream("localhost", 6789)
val words = lines.flatMap(_.split(" "))
// Convert RDDs of the words DStream to DataFrame and run SQL query
words.foreachRDD { (rdd: RDD[String], time: Time) =>
val spark = SparkSessionSingleton.getInstance(rdd.sparkContext.getConf)
import spark.implicits._
// Convert RDD[String] to RDD[case class] to DataFrame
val wordsDataFrame = rdd.map(w => Record(w)).toDF()
// Creates a temporary view using the DataFrame
wordsDataFrame.createOrReplaceTempView("words")
// Do word count on table using SQL and print it
val wordCountsDataFrame =
spark.sql("select word, count(*) as total from words group by word")
println(s"========= $time =========")
wordCountsDataFrame.show()
}
ssc.start()
ssc.awaitTermination()
}
/** Case class for converting RDD to DataFrame */
case class Record(word: String)
/** Lazily instantiated singleton instance of SparkSession */
object SparkSessionSingleton {
@transient private var instance: SparkSession = _
def getInstance(sparkConf: SparkConf): SparkSession = {
if (instance == null) {
instance = SparkSession
.builder
.config(sparkConf)
.getOrCreate()
}
instance
}
}
}