
邏輯迴歸求解(機器學習python)
梯度下降

Logistic regression
- 目的:分類還是迴歸?它是經典的二分類演算法!
- 機器學習演算法選擇:先邏輯迴歸再用複雜的,能簡單還是用簡單的
- 邏輯迴歸的決策邊界:可以是非線性的
Sigmoid 函式
- 公式: g(z)=1/(1+e−z)
- 自變數取值為任意實數,值域[0, 1]
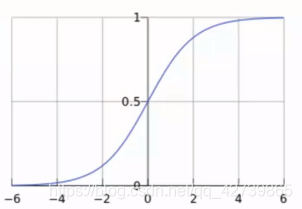
解釋:將任意的輸入對映到了[0, 1]區間,我們線上性迴歸中可以得到一個預測值,再將該值對映到Sigmoid函式中這樣就完成了由值到概率的轉換,也就是分類任務
邏輯迴歸




相關推薦
邏輯迴歸求解(機器學習python)
梯度下降 Logistic regression 目的:分類還是迴歸?它是經典的二分類演算法! 機器學習演算法選擇:先邏輯迴歸再用複雜的,能簡單還是用簡單的 邏輯迴歸的決策邊界:可以是非線性的 Sigmoid 函式 公式:
機器學習演算法(一):邏輯迴歸模型(Logistic Regression, LR)
轉自:https://blog.csdn.net/weixin_39910711/article/details/81607386 線性分類器:模型是引數的線性函式,分類平面是(超)平面;非線性分類器:模型分介面可以是曲面或者超平面的組合。 典型的線性分類器有感知機,LDA,邏輯斯特迴歸,SVM
機器學習之核函式邏輯迴歸(機器學習技法)
從軟間隔SVM到正則化從引數ξ談起在軟間隔支援向量機中引數ξ代表某一個資料點相對於邊界犯錯的程度,如下圖:在資料點沒有違反邊界時ξ的值為0,在違反邊界時的值就會大於0。所以總的來說ξ的值等於max(1 - y(WZ + b) , 0)。所以我們把問題合併如下:這樣這個問題就變
機器學習之支援向量機迴歸(機器學習技法)
核函式山脊迴歸Represent Theorem表達理論就是指如果一個模型是帶有L2正則化的線性模型,那麼它在最佳化的時候的權重引數值W*將能夠用Z空間的資料的線性組合來表示。它的推論就是L2的正則化線性模型能夠核函式化如下圖所示:現在我們的目標就是用核函式的方式去解決迴歸問
機器學習之線性迴歸(機器學習基石)
引子 在一個二元分類的問題中我們通常得到的結果是1/0,而在分類的過程中我們會先計算一個得分函式然後在減去一個門檻值後判斷它的正負若為正則結果為1若為負結果為0。 事實上從某種角度來看線性迴歸只是二元分類步驟中的一個擷取它沒有後面取正負號的操作,它的輸出結果為一個實數而非
一個博士(機器學習方向)關於發論文的幾點忠告
轉載於知乎:https://www.zhihu.com/question/25157730 問題:讀機器學習方向。 發現機器學習演算法比較固定,演算法應用於文字和影象處理。 畢業要求發表級別較高的期刊論文,演算法都已經存在甚至被改進過, 怎麼能寫出自己的東西呢?沒有idea,也就沒有實驗。 怎麼
ml課程:線性迴歸、邏輯迴歸入門(含程式碼實現)
以下是我的學習筆記,以及總結,如有錯誤之處請不吝賜教。 本文主要介紹簡單的線性迴歸、邏輯迴歸先關推倒,以及案例程式碼。 昨天做專案發現K-means都忘了,想想之前很多基礎都忘了,於是決定重新開始學一遍ml的基礎內容,順便記錄一下,也算是梳理自己的知識體系吧。 機器學習:目前包括有監
一個博士(機器學習方向)的忠告
轉 一個博士(機器學習方向)的忠告 轉載於:https://blog.csdn.net/dengheCSDN/article/details/81877437 原轉載於知乎:https://www.zhi
邏輯迴歸模型總結-機器學習
邏輯迴歸被廣泛的用來解決分類問題。由於分類是非線性問題,所以建模的主要難點是如何把非線性問題轉換為線性問題。 在模型評估層面,討論了兩類相互有關聯的評估指標。對於分類問題的預測結果,可以定義為相應的查準查全率。對於基於概率的分類模型,還可以繪製它的ROC曲線,以及計算曲線線面的面積AUC。
機器學習之神經網路(機器學習技法)
神經網路的動機感知器的線性融合前面我們知道了將簡單的模型進行融合之後會得到一個非常強大的模型。我們試著將感知器(簡單的二元分類模型)做線性融合之後得到下圖:其中每一個節點都是一個感知器,其第一層的感知器都是由前一層X向量與W權重的線性組合,而第二層的感知器又是由前一層的得到的
決策樹,decision的pyton程式碼和註釋(機器學習實戰)
Decison Tree的註釋:畫圖部分不給註釋了 from math import log import numpy def calcShannonEnt(dataSet): numEntries = len(dataSet) labelCounts =
決策樹的一般思路分析(機器學習實戰)
'''決策樹:在構造決策樹時最重要的是確定劃分資料時,哪個特徵起決定性作用為了確定起決定性作用的特徵,必須先計算資訊的增益,獲得資訊增益最高的特徵就是最好的選擇集合資訊的度量方式稱為熵————資訊的期望資訊的定義:若待分類事物存在多個劃分,則符號xi的資訊定義為l(xi)=l
感知機學習演算法(PLA)的修正過程的理解(機器學習基石)
原理 首先,PLA修正過程的數學表示: 在一個迴圈中,t代表當前的迭代次數 1. 找到一個錯誤分類的點(xt,ytxt,yt): sign(wTtxn(t))≠yn(t)sign(wtTxn(t))≠yn(t) 2. 修正該錯誤 Wt+1←Wt+yn
機器學習中的噪音(機器學習基石)
noise的產生在機器學習中我們在獨立隨機抽樣的時候會出現一些搞錯的資訊,這些錯誤的資料我們稱之為雜訊(或者噪音 noise),一般可以歸結為一下兩種(以二分為例):輸出錯誤:1.同樣的一筆資料會出現兩種不同的評判 2.在同樣的評判下會有不同的後續處理。輸入錯誤:1.在收
機器學習實戰(四)邏輯迴歸LR(Logistic Regression)
目錄 0. 前言 1. Sigmoid 函式 2. 梯度上升與梯度下降 3. 梯度下降法(Gradient descent) 4. 梯度上升法(Gradient ascent) 5. 梯度下降/上升法的數學推導
機器學習:邏輯回歸(損失函數)
梯度 模型 分享圖片 com info 而且 機器學習 邏輯 分類 # # 由於邏輯回歸解決的是分類問題,而且是二分類,因此定義損失函數時也要有兩類 # 1)如果 y = 1(p ≥ 0.5),p 越小,損失函數越大; # 2)如果 y = 0(p ≤ 0.5),
Python實現邏輯迴歸演算法(一)
本次用Python實現邏輯迴歸演算法,邏輯迴歸是應用非常廣泛的一個分類及其學習演算法,它將資料擬合到一個logit函式中,從而完成對事件發生的概率進行預測。本次學習筆記主要參考了《Python進行資料分析與挖掘實踐》和作者@寒小陽的部落格,地址如下:http://blog.c
機器學習 Python scikit-learn 中文文件(3)使用 scikit-learn 介紹機器學習
與官方文件完美匹配的中文文件,請訪問 https://www.studyai.cn 與官方文件完美匹配的中文文件,請訪問 https://www.studyai.cn Logo 首頁 安裝 文件 案例 Fork me on GitHub Previous scikit-learn
機器學習 Python scikit-learn 中文文件(2)教程目錄
與官方文件完美匹配的中文文件,請訪問 https://www.studyai.cn 與官方文件完美匹配的中文文件,請訪問 https://www.studyai.cn scikit-learn 教程 使用 scikit-learn 介紹機器學習 機器學習:問題設定 載入示例資
機器學習 Python scikit-learn 中文文件 (1)
與官方文件完美匹配的中文文件,請訪問 https://www.studyai.cn 與官方文件完美匹配的中文文件,請訪問 https://www.studyai.cn Logo 首頁 安裝 文件 案例 ‹› scikit-learn 在Python中進行機器學習 簡單且高效的