
機器學習中的噪音(機器學習基石)
阿新 • • 發佈:2019-01-31
noise的產生
在機器學習中我們在獨立隨機抽樣的時候會出現一些搞錯的資訊,這些錯誤的資料我們稱之為雜訊(或者噪音 noise),一般可以歸結為一下兩種(以二分為例):
輸出錯誤:1.同樣的一筆資料會出現兩種不同的評判 2.在同樣的評判下會有不同的後續處理。
輸入錯誤:1.在收集資料的時由於資料來源的隨機性會出現錯誤(比如說,客戶在填資訊的時候出現的誤填)
noise的情況下VC維度的可用性
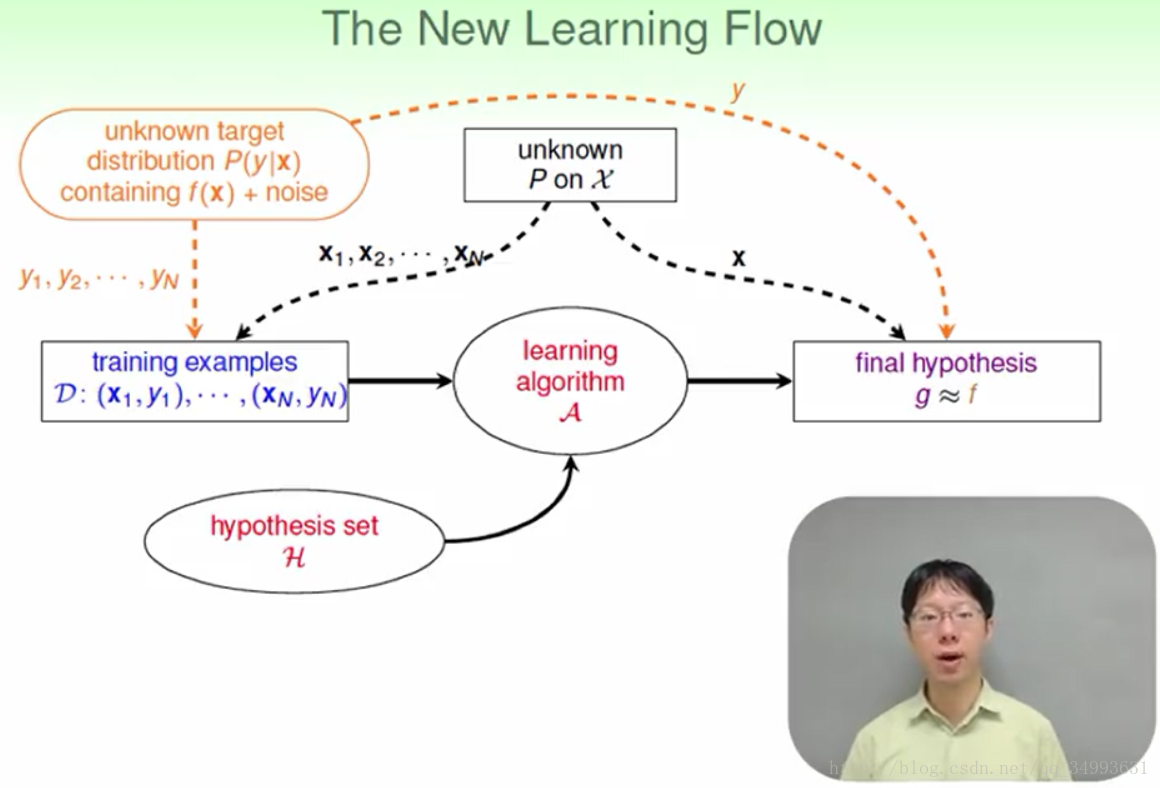
在有noise的情況下我們的資料不會都來自於我們所求的目標函式而是來自於一個帶有noise的分佈,因此我們的f(x)會在產生資料的時候加上一個波動值後變成了f(x)+noise它具有一定的隨機性。
在這裡需要注意的是我們的資料產生於一個帶有noise的分佈,而我們預測的資料也是產生於一個同樣的分佈。直觀的來看只是一個換了分佈的機器學習過程。所以VC維度能夠在有雜訊的情況下學習
noise的代價
我們能夠在有雜訊的資料上學習,通過一個帶有雜訊的分佈,當然我們會犯錯。在遇到一個具體的點的時候,我們會查詢這個點在我們的標籤分佈上的概率p(y | x),比如說這個分佈會告訴我們x的概率為0.7,o的概率是0.3那麼我們就會選擇概率較大的那個選項,但是我們有0.3的機率會犯錯,這就是我們的代價。
修正後的機器學習模型圖如下:
最後感謝臺灣大學林軒田老師。