
機器學習 K-means 聚類演算法 C++
阿新 • • 發佈:2018-12-16
筆記:
尚未解決的問題 :
1. 只支援二維,而不支援三維或更高,需要模板元
2. 尚未實現如何刪除極端點, 即預處理
3. 尚未視覺化
編譯環境 Ubuntu gcc 5.4 編譯選項 g++ -std=c++14
#include <iostream> #include <functional> #include <fstream> #include <cstdlib> #include <ctime> #include <vector> #include <tuple> #include <memory> #include <string> #include <cmath> #include <array> #include <list> #include <assert.h> #include "scopeguard.h" using point = std::tuple<double, double>; using oneCluster = std::vector<point>; void print(const std::vector<oneCluster>& clusters) { for(const auto& it : clusters) { std::cout << "\n\n*******************\n\n"; for(const auto& r : it) { std::cout << "( " << std::get<0>(r) << " , "; std::cout << std::get<1>(r) << " )\n"; } } } // 讀取檔案內容 std::vector< point > readData(const std::string& path) { // std::unique_ptr std::ifstream in(path.c_str()); YHL::ON_SCOPE_EXIT([&]{ in.close(); std::cout << "資料集檔案已關閉\n\n"; }); auto items = 0; in >> items; auto x = 0.00, y = 0.00; std::vector< point > dataSet; for(int i = 0;i < items; ++i) { in >> x >> y; dataSet.emplace_back(std::make_tuple<double, double>(std::move(x), std::move(y))); } for(const auto& it : dataSet) std::cout << std::get<0>(it) << "\t" << std::get<1>(it) << "\n"; return dataSet; } // 計算兩個點之間的距離, 在這裡選擇的是歐氏距離 inline double getDistance(const point& a, const point& b) { return sqrt(pow(std::get<0>(a) - std::get<0>(b), 2) + pow(std::get<1>(a) - std::get<1>(b), 2)); } // 在這些簇中心點 centers 中, one 這個點選離自己最近的一個,返回這個最近的中心店 const int getLabel(const point& one, const oneCluster& centers) { // 計算 one 每一個 cluster 中心的距離, 返回距離最近的那個 cluster auto Min = 1e6; int label = -1, centerSize = centers.size(); for(int i = 0;i < centerSize; ++i) { auto ans = getDistance(centers[i], one); if(ans < Min) { Min = ans; label = i; } } return label; } // 給定一個簇,計算簇的中心,在這裡選擇的是 x, y 均值點 point getCenter(const oneCluster& one) { double mean_x, mean_y = 0.00; for(const auto& it : one) { mean_x += std::get<0>(it); // 取橫座標 mean_y += std::get<1>(it); // 取縱座標 } int scale = one.size(); return std::make_tuple<double, double>(mean_x / scale, mean_y / scale); } // 給定聚類結果 clusters, 和這些簇的中心 centers,預估聚類效果,方式多樣 const double getEvaluate(const std::vector<oneCluster>& clusters, const oneCluster& centers) { double ans = 0; int lSize = clusters.size(), rSize = centers.size(); // 一個簇對應一箇中心點 assert(lSize == rSize); for(int i = 0;i < lSize; ++i) { // it 代表一個簇, 計算這個簇每一個點 和 "虛擬"中心點的距離(中心點可能不在簇中,畢竟求的是均值所在) int oneSize = clusters[i].size(); for(int k = 0;k < oneSize; ++k) { ans += getDistance(clusters[i][k], centers[i]); // 第 i 個簇的每個點, 計算和這個簇的中心點的距離 } } return ans; } // 給定資料集 dataSet, 聚成 k 類, 閾值 thresholdValue(預估差 < 閾值 就結束) std::vector< oneCluster > K_means(const oneCluster& dataSet, const int k, const double thresholdValue) { // 還可以預處理,刪掉極端點 auto dataSize = dataSet.size(); assert(k <= dataSize); // 如果聚類數 > 資料量,這是錯誤的 oneCluster centers; // 先選定 k 個隨機的中心點 std::vector<int> book(k, 0); srand(time(nullptr)); for(int i = 0;i < k; ++i) { auto j = rand() % dataSize; while(book[j] == 1) j = rand() % dataSize; centers.emplace_back(dataSet[j]); } // clusters 儲存的每一個元素都是一個簇, 預先分配 K 個簇的空間 std::vector< oneCluster > clusters; clusters.assign(k, oneCluster()); double oldValue = 0.00, newValue = 0.00; int cnt = 0; while(true) { std::cout << "\n\n********** 第 " << ++cnt << " 次聚類 ************\n\n"; // 每個點找出離它最近的中心點, 放在第 label 個簇中 for(const auto& it : dataSet) { auto label = getLabel(it, centers); assert(0 <= label and label < k); clusters[label].emplace_back(it); } print(clusters); // 重新計算每個簇的中心點 for(int i = 0;i < k; ++i) { centers[i] = getCenter(clusters[i]); std::cout << "第 " << i + 1 << " 個簇的中心點是 : "; std::cout << "( " << std::get<0>(centers[i]) << " , " << std::get<1>(centers[i]) << " )\n"; } // 重新衡量這次的最小函式值 oldValue = newValue; // 先儲存上次的最小均方差之和 newValue = getEvaluate(clusters, centers); if(abs(newValue - oldValue) < thresholdValue) // 如果變化小於閾值,就結束 return clusters; // NVO // 每次聚類,得到的聚類都是不一樣的,所以上次的記錄要清空 for(auto &it : clusters) it.clear(); } return std::vector< oneCluster >(); } int main() { auto dataSet = readData("k-means(1).txt"); auto clusters = K_means(dataSet, 3, 0.5); print(clusters); return 0; } /* 尚未解決的問題 : 1. 只支援二維,而不支援三維或更高,需要模板元 2. 尚未實現如何刪除極端點, 即預處理 3. 尚未視覺化 */
生成測試資料的程式碼:
利用 C++ 生成隨機小數, 聲稱自己的資料集:
#include <iostream> #include <fstream> #include <ctime> #include <random> #include "scopeguard.h" int main() { std::ofstream out("k-means(1).txt", std::ios::trunc); YHL::ON_SCOPE_EXIT([&]{ out.close(); }); int num = 380; out << num << "\n"; std::default_random_engine e(time(0)); std::uniform_real_distribution<double> a(0, 4); std::uniform_real_distribution<double> b(6, 8); std::uniform_real_distribution<double> c(-3, -6); for(int i = 0;i < num - 80; ++i) { int choice = rand() % 3; switch(choice) { case 0 : { out << a(e) << " " << a(e) << "\n"; // 這一塊比較集中,位於第一象限 break; } case 1 : { out << b(e) << " " << c(e) << "\n"; // 這一塊比較集中,位於第四象限 break; } case 2 : { out << c(e) << " " << c(e) << "\n"; // 這一比較集中,位於第三象限 break; } } } std::uniform_real_distribution<double> d(-10, 10); // 剩下的是大範圍內隨機, 1, 2, 3, 4象限都有 for(int i = 0; i < 80; ++i) out << d(e) << " " << d(e) << "\n"; return 0; }
測試結果:
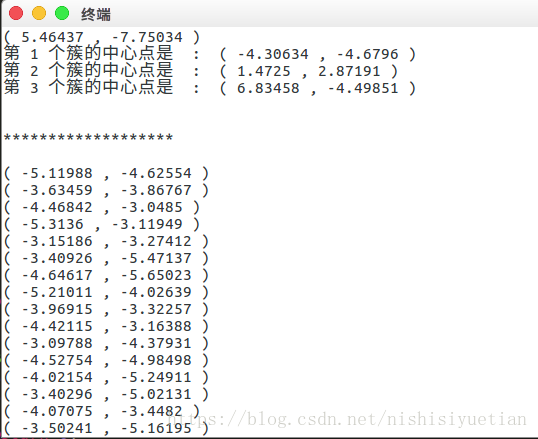
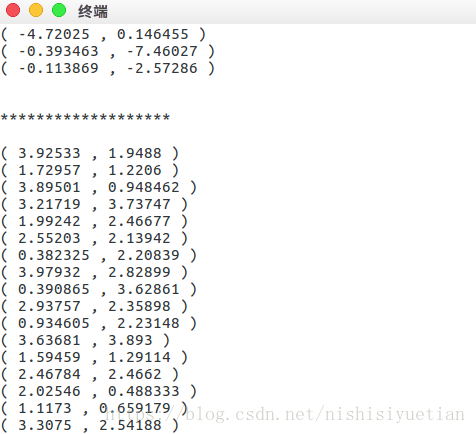

可見元素基本集中在三個象限中