
轉載:分散式系統的思考
在討論常見架構前,先簡單瞭解下CAP理論:
CAP 是 Consistency、Availablity 和 Partition-tolerance 的縮寫。分別是指:
-
一致性(Consistency):每次讀操作都能保證返回的是最新資料;
-
可用性(Availablity):任何一個沒有發生故障的節點,會在合理的時間內返回一個正常的結果;
-
分割槽容忍性(Partition-tolerance):當節點間出現網路分割槽,照樣可以提供服務。
CAP理論指出:CAP三者只能取其二,不可兼得。其實這一點很好理解:
-
首先,單機系統都只能保證CP。
-
有兩個或以上節點時,當網路分割槽發生時,叢集中兩個節點不能互相通訊。此時如果保證資料的一致性C,那麼必然會有一個節點被標記為不可用的狀態,違反了可用性A的要求,只能保證CP。
-
反之,如果保證可用性A,即兩個節點可以繼續各自處理請求,那麼由於網路不通不能同步資料,必然又會導致資料的不一致,只能保證AP。
一、單例項
單機系統很顯然,只能保證CP,犧牲了可用性A。單機版的MySQL,Redis,MongoDB等資料庫都是這種模式。
實際中,我們需要一套可用性高的系統,即使部分機器掛掉之後仍然可以繼續提供服務。
二、多副本
相比於單例項,這裡多了一個節點去備份資料。
對於讀操作來說,因為可以訪問兩個節點中的任意一個,所以可用性提升。
對於寫操作來說,根據更新策略分為三種情況:
1.同步更新:即寫操作需要等待兩個節點都更新成功才返回。這樣的話如果一旦發生網路分割槽故障,寫操作便不可用,犧牲了A。
2.非同步更新:即寫操作直接返回,不需要等待節點更新成功,節點非同步地去更新資料(FastDFS檔案系統的儲存節點就是用這種方式,寫完一份資料之後立即返回結果,副本資料由同步執行緒寫入其他同group的節點)。這種方式,犧牲了C來保證A,即無法保證資料是否更新成功,還有可能會由於網路故障等原因,導致資料不一致。
3.折衷:更新部分節點成功後便返回。
這裡,先介紹一下類Dynamo系統用於控制分散式儲存系統中的一致性級別的策略--NWR:
*N:同一份資料的副本個數
*W:寫操作需要確保成功的副本個數
*R:讀操作需要讀取的副本個數
當W+R>N時,由於讀寫操作覆蓋到的副本集肯定會有交集,讀操作只要比較副本集資料的修改時間或者版本號即可選出最新的,所以系統是強一致性的;反之,當W+R<=N時是弱一致性的。
如:(N,W,R)=(1,1,1)為單機系統,是強一致性的;(N,W,R)=(2,1,1)位常見的master-slave模式,是弱一致性的。
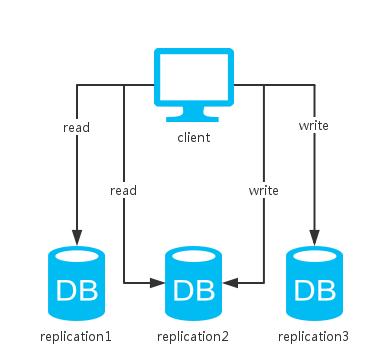
舉例:
> 如像Cassandra中的折衷型方案QUORUM,只要超過半數的節點更新成功便返回,讀取時返回多副本的一致的值。然後,對於不一致的副本,可以通過read repair的方式解決。read repair:讀取某條資料時,查詢所有副本中的這條資料,比較資料與大多數副本的最新資料是否一致,若否,則進行一致性修復。其中,W + R > N,故而是強一致性的。
> 又如Redis的master-slave模式,更新成功一個節點即返回,其他節點非同步去備份資料。這種方式只保證了最終一致性。最終一致性:相比於資料時刻保持一致的強一致性,最終一致性允許某段時間內資料不一致。但是隨著時間的增長,資料最終會到達一致的狀態。其中,W+R<N,所以只能保證最終一致性。
此外,N越大,資料可靠性越好,但是由於W或者R越大,讀寫開銷越大,效能越差,所以一般需要總和考慮一致性,可用性和讀寫效能,設定W,R都為N/2+1。
其實,折衷方案和非同步更新的方式從本質上來說是一樣的,都是損失一定的C來換取A的提高。而且,會產生'腦裂'的問題--即網路分割槽時節點各自處理請求,無法同步資料,當網路恢復時,導致不一致。
一般的,資料庫都會提供分割槽恢復的解決方案:
1.從源頭解決:如設定節點通訊的超時時間,超時後'少數派'節點不提供服務。這樣便不會出現資料不一致的情況,不過可用性降低。
2.從恢復解決:如在通訊恢復時,對不同節點的資料進行比較、合併,這樣可用性得到了保證。但是在恢復完成之前,資料是不一致的,而且可能出現數資料衝突。
光這樣還不夠,當資料量較大時,由於一臺機器的資源有限並不能容納所有的資料,我們會向把資料分到好幾臺機器上儲存。
三、分片
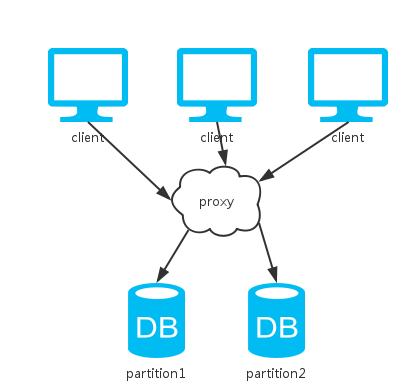
相比於單例項,這裡多了一個節點去分割資料。
由於所有資料只有一份,一致性得以保證;節點間不需要通訊,分割槽容忍性也有。
然而,當任意一個節點掛掉,丟失了一部分的資料,系統可用性得不到保證。
綜上,這和單機版的方案一樣,都只能保證CP。
那麼,有哪些好處呢?
1.某個節點掛掉只會影響部分服務,即服務降級;
2.由於分片了資料,可以均衡負載;
3.資料量增大/減小後可以相應的擴容/縮容。
大多數的資料庫服務都提供了分片的功能。如Redis的slots,Cassandra的patitions,MongoDB的shards等。
基於分片解決了資料量大的問題,可是我們還是希望我們的系統是高可用的,那麼,如何犧牲一定的一致性去保證可用性呢?
四、叢集
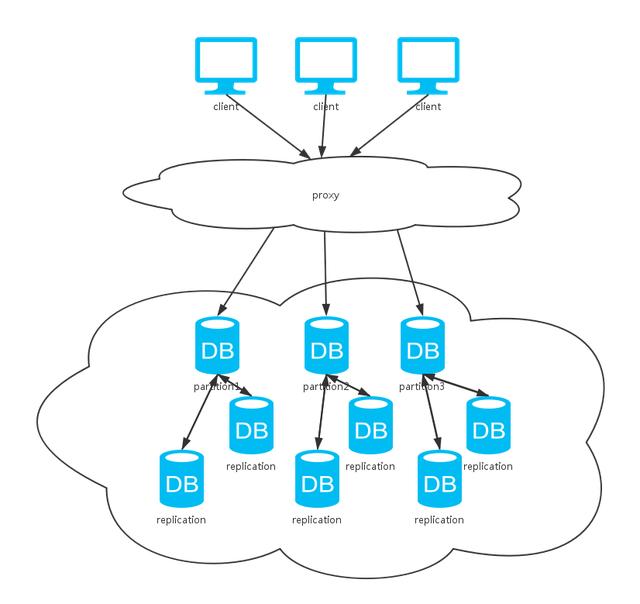
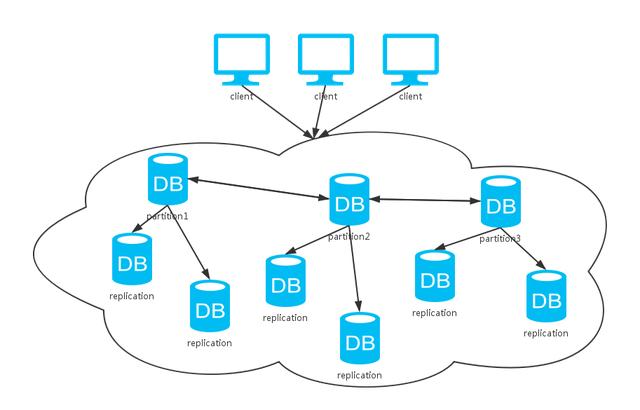
可以看到,上面這種方式綜合了前兩種方式。同上分析,採用不同的資料同步策略,系統CAP保證各有不同。不過,一般資料庫系統都會提供可選的配置,我們根據不同的場景選擇不同的特性。
其實,對於大多數的非金融類網際網路公司,要求並非強一致性,而是可用性和最終一致性的保證。這也是NoSQL流行於網際網路應用的一大原因,相比於強一致性系統的ACID原則,它更加傾向於BASE:
>Basically Available:基本可用性,即允許分割槽失敗,除了問題僅服務降級;
>Soft-state:軟狀態,即允許非同步;
>Eventual Consistency:最終一致性,允許資料最終一致性,而不是時刻一直。
五、總結
基本上,上面討論的幾種方式已經涵蓋了大多數的分散式儲存系統了。我們可以看到,這些個方案總是需要通過犧牲一部分去換取另一部分,總沒法達到100%的CAP。選擇哪種方案,依據就是在特定場景下,究竟哪些特性是更加重要的了。
轉載:
https://blog.csdn.net/lavorange/article/details/52489998
https://www.toutiao.com/a6322572198263996673/?tt_from=weixin&utm_campaign=client_share&app=news_article&utm_source=weixin&iid=3669662677&utm_medium=toutiao_ios&wxshare_count=1