
機器學習演算法--KNN近鄰分類演算法
KNN近鄰分類演算法
演算法思想:
存在一個樣本資料集合,也稱為訓練樣本集,並且樣本集中每個資料都存在標籤,即我們知道樣本集中每一資料與所屬分類對應的關係。輸入沒有標籤的資料後,將新資料中的每個特徵與樣本集中資料對應的特徵進行比較,提取出樣本集中特徵最相似資料(最近鄰)的分類標籤。一般來說,我們只選擇樣本資料集中前k個最相似的資料,這就是k近鄰演算法中k的出處,通常k是不大於20的整數。最後選擇k個最相似資料中出現次數最多的分類作為新資料的分類。
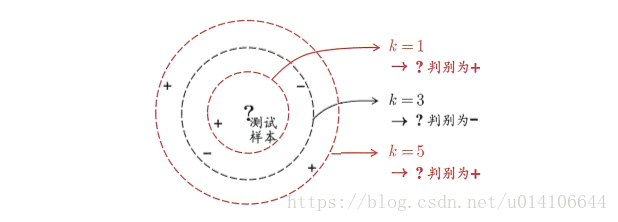
給定一組樣本資料以及分類資訊,給定一組新樣本,求出新樣本的類別情況。
演算法虛擬碼:
對未知類別屬性的資料集中每個點依次執行以下操作:
- 計算已知類別資料集中的點與當前點的距離
- 按照距離遞增排序
- 選取與當前距離最小的k個點
- 確定前k個點所在類別出現的頻率
- 返回前k個點出現頻率最高的類別作為當前點的預測分類
1.距離計算
當給定一組樣本資料時,當樣本的特徵屬性是有序屬性,可以直接進行數值計算來度量兩個樣本之間的距離。如果樣本屬性是有序的可以度量的,把樣本抽象成空間的點,可以採用歐式距離來度量點與點之間的距離。
對於一個函式dist,若其表示距離度量,則應滿足一下性質:
非負性:dist(xi, xj)>=0
同一性:dist(xi, xj)=0,當且僅當xi=xj
對稱性:dist(xi,xj)=dist(xj,xi)
直遞性:dist(xi,xj)<=dist(xi,xk)+dist(xk,xj)
對於樣本Xi=(xi1,xi2...xin),Xj=(xj1,xj2...xjn),常用距離閔科夫斯基距離:
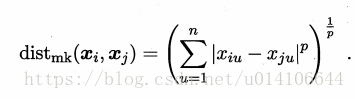
當p=2時,即歐式距離:
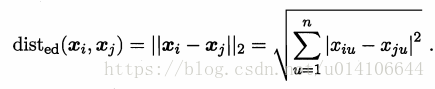
當p=1時,即曼哈頓距離:
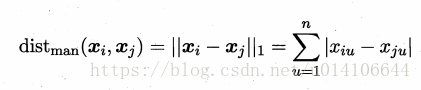
對於無序屬性,不能直接在屬性值上進行距離計算,可採用VDM方式:
mua 屬性u上取值為a大的樣本數 muai 第i個樣本簇在屬性u上取值為a的樣本數,k為總簇數
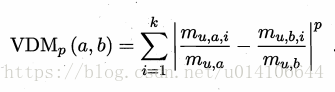
假定有nc個有序屬性 n-nc個無序屬性
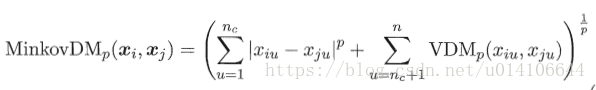
當樣本中屬性權重不同是,可以採用加權距離:

在這裡,為了便於計算,採用歐式距離進行計算
2.資料處理
以機器學習實戰樣例資料為準,
對於一個人的分類有不喜歡的人1,魅力一般的人2,極具魅力的人3。
主要與以下因素有關:每年飛行里程數 玩遊戲所耗時間比 每週消費冰淇淋數
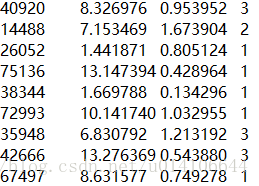
將資料檔案中資料處理,分別讀取到特徵屬性數值矩陣以及類別矩陣,前三列為特徵屬性數值 最後一列為類別數值
def file2matrix(filename):
#開啟檔案
fr = open(filename)
#獲取資料的總行數
numberOfLines = len(fr.readlines())
#生成一個[numberOfLines][3]二維矩陣存放特徵屬性值
returnMat = zeros((numberOfLines, 3))
#分類屬性存放
classLabelVector = []
fr = open(filename)
index = 0
#遍歷每一行
for line in fr.readlines():
#去掉回車
line = line.strip()
#以tab進行切分
listFromLine = line.split('\t')
#前三個元素複製到特徵資料矩陣
returnMat[index,:] = listFromLine[0:3]
#最後一個元素放入類別矩陣
classLabelVector.append(int(listFromLine[-1]))
index += 1
return returnMat, classLabelVector3.分析資料
使用Matplotlib建立原始資料散點圖 ,觀察類別資訊
檢視python已經安裝module

安裝matplotlib
python -m pip install matplotlib
以特徵屬性矩陣二三列顯示如下:
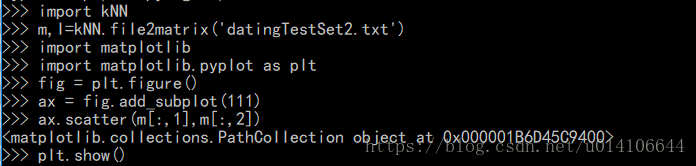
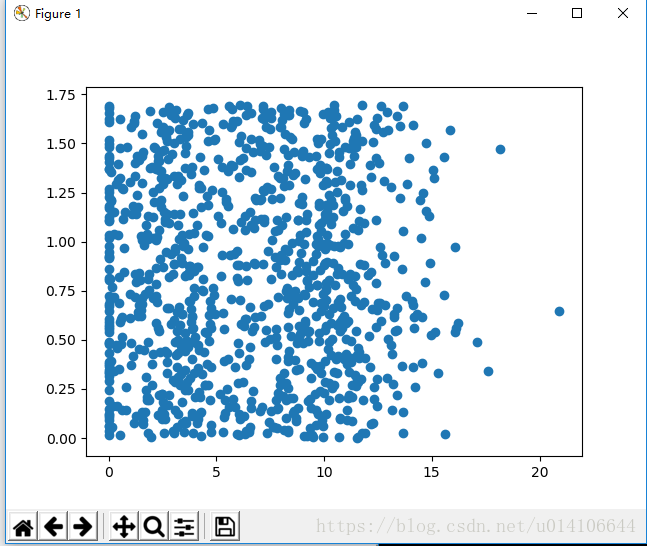
重新載入kNN

>>> import kNN
>>> from numpy import *
>>> import matplotlib
>>> import matplotlib.pyplot as plt
>>> fig = plt.figure()
>>> ax = fig.add_subplot(111)
>>> mat,lab = kNN.file2matrix('datingTestSet.txt')
>>> ax.scatter(mat[:,1], mat[:,2], 15.0*array(map(int,lab)),15.0*array(map(int,lab)))
>>> plt.show()第二三列以及第一二列的顯示結果,可知資料具有明顯的分類概念
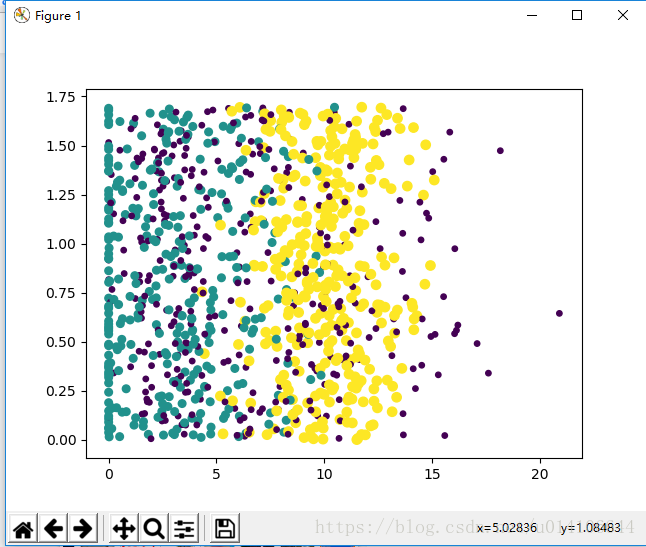

4.歸一化特徵屬性矩陣
歸一化屬性值,消除不同量綱對於結果的影響,常見的歸一化方法有:
4.1 min-max標準化(Min-max normalization)
也叫離差標準化,是對原始資料的線性變換,使結果落到[0,1]區間,轉換函式如下:
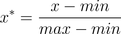
其中max為樣本資料的最大值,min為樣本資料的最小值。
def Normalization(x): return [(float(i)-min(x))/float(max(x)-min(x)) for i in x]
如果想要將資料對映到[-1,1],則將公式換成:
x∗=x−xmeanxmax−xmin x_mean表示資料的均值。
def Normalization2(x): return [(float(i)-np.mean(x))/(max(x)-min(x)) for i in x]
這種方法有一個缺陷就是當有新資料加入時,可能導致max和min的變化,需要重新定義。
4.2 log函式轉換
通過以10為底的log函式轉換的方法同樣可以實現歸一下,具體方法如下:
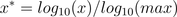
看了下網上很多介紹都是x*=log10(x),其實是有問題的,這個結果並非一定落到[0,1]區間上,應該還要除以log10(max),max為樣本資料最大值,並且所有的資料都要大於等於1。
4.3 atan函式轉換
用反正切函式也可以實現資料的歸一化。
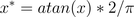
使用這個方法需要注意的是如果想對映的區間為[0,1],則資料都應該大於等於0,小於0的資料將被對映到[-1,0]區間上,而並非所有資料標準化的結果都對映到[0,1]區間上。
4.4 z-score 標準化(zero-mean normalization)
最常見的標準化方法就是Z標準化,也是SPSS中最為常用的標準化方法,spss預設的標準化方法就是z-score標準化。
也叫標準差標準化,這種方法給予原始資料的均值(mean)和標準差(standard deviation)進行資料的標準化。
經過處理的資料符合標準正態分佈,即均值為0,標準差為1,其轉化函式為:
x∗=x−μσ 其中μ為所有樣本資料的均值,σ為所有樣本資料的標準差。
z-score標準化方法適用於屬性A的最大值和最小值未知的情況,或有超出取值範圍的離群資料的情況。
標準化的公式很簡單,步驟如下
1.求出各變數(指標)的算術平均值(數學期望)xi和標準差si ; 2.進行標準化處理: zij=(xij-xi)/si 其中:zij為標準化後的變數值;xij為實際變數值。 3.將逆指標前的正負號對調。 標準化後的變數值圍繞0上下波動,大於0說明高於平均水平,小於0說明低於平均水平。
def z_score(x, axis):
x = np.array(x).astype(float)
xr = np.rollaxis(x, axis=axis)
xr -= np.mean(x, axis=axis)
xr /= np.std(x, axis=axis)
# print(x)
return x
這裡採用min-max歸一化方法
def autoNorm(dataSet):
#取出每一列的最小值 1x3
minVals = dataSet.min(0)
#取出每一列的最大值
maxVals = dataSet.max(0)
#每一列的最大和最小之差
ranges = maxVals - minVals
#生成歸一化陣列
normDataSet = zeros(shape(dataSet))
#行數
m = dataSet.shape[0]
#擴充minVals矩陣為mx3,以原先1x3複製m行
normDataSet = dataSet - tile(minVals, (m,1))
#進行矩陣對應位置相除歸一化
normDataSet = normDataSet/tile(ranges, (m,1)) #element wise divide
return normDataSet, ranges, minVals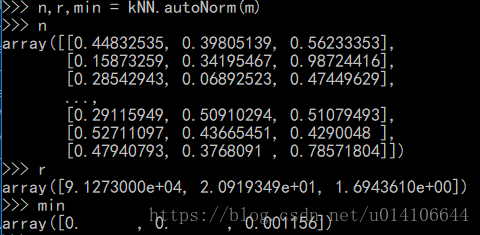
5.KNN演算法實現
計算每個待分類樣本與已分類樣本的距離,排序,選取最小的k個樣本,統計其中每種類別的出現次數排序,返回出現次數最多的類別作為待分類樣本的類別
具體實現如下所示:
def classify0(inX, dataSet, labels, k):
#樣本資料矩陣的行數
dataSetSize = dataSet.shape[0]
#把待計算行向量複製成dataSetSize,與樣本資料矩陣相減
diffMat = tile(inX, (dataSetSize,1)) - dataSet
#計算矩陣的平方
sqDiffMat = diffMat**2
#矩陣每一行相加,組成一個dataSetSize維陣列
sqDistances = sqDiffMat.sum(axis=1)
#開平方,計算距離
distances = sqDistances**0.5
#將distances中的元素從小到大排列,提取其對應的index(索引),然後輸出到sortedDistIndicies
sortedDistIndicies = distances.argsort()
#定義一個字典 key 類別 value 該類別總次數
classCount={}
#計算最近的k個樣本類別出現的次數
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
#不存在對應key返回0
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
#按照第二個元素降序排列
sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]python3 dict.items方法,而非dict.iteritems
其中
1.shape[0]表示矩陣行數
2.tile函式:
tile(a,x): 結果是一維陣列,x是控制a重複次數 tile(a,(x,y)): 結果是一個二維矩陣,其中行數為x,列數是一維陣列a的長度和y的乘積 tile(a,(x,y,z)): 結果是一個三維矩陣,其中矩陣的行數為x,矩陣的列數為y,而z表示矩陣每個單元格里a重複的次數
3.**表示次方
4.argsort() 從小到大排序 返回對應索引
5.sorted函式:sorted 可以對所有可迭代的物件進行排序操作
sorted(iterable[, cmp[, key[, reverse]]])引數說明:
- iterable -- 可迭代物件。
- cmp -- 比較的函式,這個具有兩個引數,引數的值都是從可迭代物件中取出,此函式必須遵守的規則為,大於則返回1,小於則返回-1,等於則返回0。
- key -- 主要是用來進行比較的元素,只有一個引數,具體的函式的引數就是取自於可迭代物件中,指定可迭代物件中的一個元素來進行排序。
- reverse -- 排序規則,reverse = True 降序 , reverse = False 升序(預設)
返回排序之後的物件列表。
6.測試演算法
給定資料集,一部分用於作為樣本資料,一部分作為待測試資料,測試比例為0.1。程式碼如下:
def datingClassTest():
#測試資料的比例
hoRatio = 0.10 #hold out 10%
#從檔案中讀取資料
datingDataMat,datingLabels = file2matrix('datingTestSet2.txt') #load data setfrom file
#歸一化處理資料
normMat, ranges, minVals = autoNorm(datingDataMat)
#樣本總數
m = normMat.shape[0]
#測試樣本的數量
numTestVecs = int(m*hoRatio)
errorCount = 0.0
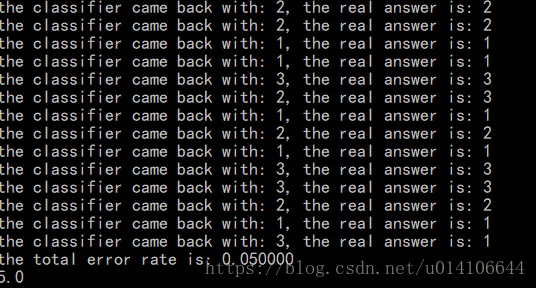
for i in range(numTestVecs):
#前1--numTestVecs作為待分類樣本 numTestVecs--m作為標準樣本資料
classifierResult = classify0(normMat[i,:],normMat[numTestVecs:m,:],datingLabels[numTestVecs:m],3)
print ("the classifier came back with: %d, the real answer is: %d" % (classifierResult, datingLabels[i]))
if (classifierResult != datingLabels[i]): errorCount += 1.0
print ("the total error rate is: %f" % (errorCount/float(numTestVecs)))
print (errorCount)結果如下所示:
7.使用例項--手寫識別系統
trainingDigits中存放樣本資料 testDigits存放測試資料,其中數字8示例如下:



每個數字由32x32二維陣列來表示
第一步進行資料處理,將32x32陣列讀取到一個1x1024的一維陣列中,便於進行計算。
def img2vector(filename):
#產生一個1024陣列
returnVect = zeros((1,1024))
fr = open(filename)
#讀取每一行
for i in range(32):
lineStr = fr.readline()
for j in range(32):
#進行座標變換 第i行第j個元素 放入到32*i+j一維陣列中
returnVect[0,32*i+j] = int(lineStr[j])
return returnVect進行訓練和測試:
載入訓練集,處理訓練集資料,產生訓練集資料矩陣以及類別矩陣
載入測試集,對於每個測試樣本利用KNN演算法計算類別結果,並與標準結果進行比較,統計分類失敗的個數
def handwritingClassTest():
hwLabels = []
#載入訓練集
trainingFileList = listdir('trainingDigits') #load the training set
#訓練樣本總數
m = len(trainingFileList)
#存放訓練樣本總數矩陣mx1024
trainingMat = zeros((m,1024))
for i in range(m):
fileNameStr = trainingFileList[i]
fileStr = fileNameStr.split('.')[0] #take off .txt
classNumStr = int(fileStr.split('_')[0])
#取出該檔案資料的類別
hwLabels.append(classNumStr)
#將資料放入到特徵值資料矩陣
trainingMat[i,:] = img2vector('trainingDigits/%s' % fileNameStr)
testFileList = listdir('testDigits') #iterate through the test set
errorCount = 0.0
mTest = len(testFileList)
for i in range(mTest):
fileNameStr = testFileList[i]
fileStr = fileNameStr.split('.')[0] #take off .txt
classNumStr = int(fileStr.split('_')[0])
vectorUnderTest = img2vector('testDigits/%s' % fileNameStr)
classifierResult = classify0(vectorUnderTest, trainingMat, hwLabels, 3)
print ("the classifier came back with: %d, the real answer is: %d" % (classifierResult, classNumStr))
if (classifierResult != classNumStr): errorCount += 1.0
print ("\nthe total number of errors is: %d" % errorCount)
print ("\nthe total error rate is: %f" % (errorCount/float(mTest)))8.總結
KNN演算法屬於監督學習中的分類,KNN沒有顯示的訓練過程,它是“懶惰學習”的代表,它在訓練階段只是把資料儲存下來,訓練時間開銷為0,等收到測試樣本後進行處理。
優點: 精度高 對異常值不敏感 無資料假定輸入。
缺點:計算複雜度,空間複雜度很高。無法給出任何資料的基礎結構資訊,無法知曉平均例項和典型例項的特徵。