
Golang百萬級高併發實踐
寫在前面
Go語言作為新興的語言,最近發展勢頭很是迅猛,其最大的特點就是原生支援併發。它使用的是“協程(goroutine)模型”,和傳統基於 OS 執行緒和程序實現不同,Go
語言的併發是基於使用者態的併發,這種併發方式就變得非常輕量,能夠輕鬆執行幾萬併發邏輯。
Go 的併發屬於 CSP 併發模型的一種實現,CSP 併發模型的核心概念是:“不要通過共享記憶體來通訊,而應該通
過通訊來共享記憶體”。這在 Go 語言中的實現就是 Goroutine 和 Channel。

場景描述
在一些場景下,有大規模請求(十萬或百萬級qps),我們處理的請求可能不需要立馬知道結果,例如資料的打點,檔案的上傳等等。這時候我們需要非同步化處理。常用的方法有使用resque、MQ、RabbitMQ等。這裡我們在Golang語言裡進行設計實踐。
方案演進
直接使用goroutine
在Go語言原生併發的支援下,我們可以直接使用一個goroutine(如下方式)去並行處理這個請求。但是,這種方法明顯有些不好的地方,我們沒法控制goroutine產生數量,如果處理程式稍微耗時,在單機萬級十萬級qps請求下,goroutine大規模爆發,記憶體暴漲,處理效率會很快下降甚至引發程式崩潰。
...
go handle(request)
...
goroutine協同帶快取的管道
我們定義一個帶快取的管道;
var queue = make(chan job, MAX_QUEUE_SIZE)
然後起一個協程處理管道傳來的請求;
go func(){
for {
select {
case job := <-queue:
job.Do(request)
case <- quit:
return
}
}
}()
接收請求,傳送job進行處理
job := &Job{request}
queue <- job
講真,這種方法使用了緩衝佇列一定程度上了提高了併發,但也是治標不治本,大規模併發只是推遲了問題的發生時間。當請求速度遠大於佇列的處理速度時,緩衝區很快被打滿,後面的請求一樣被堵塞了。
job佇列+工作池
只用緩衝佇列不能解決根本問題,這時候我們可以參考一下執行緒池的概念,定一個工作池(協程池),來限定最大goroutine數目。每次來新的job時,從工作池裡取出一個可用的worker來執行job。這樣一來即保障了goroutine的可控性,也儘可能大的提高了併發處理能力。
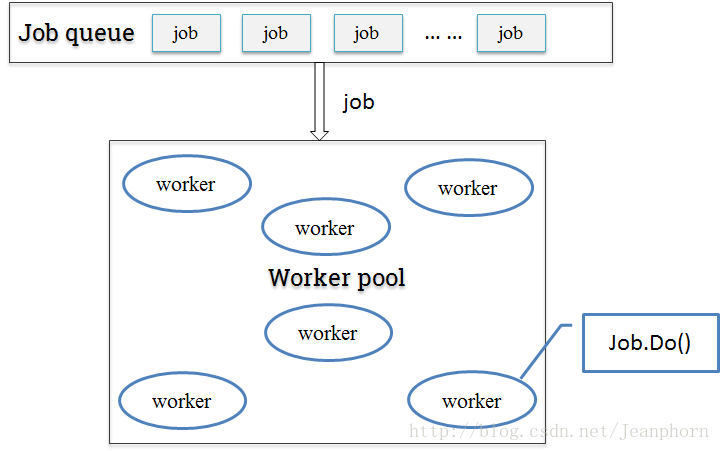
工作池實現
首先,我們定義一個job的介面, 具體內容由具體job實現;
type Job interface {
Do() error
}
然後定義一下job佇列和work池型別,這裡我們work池也用golang的channel實現。
// define job channel
type JobChan chan Job
// define worker channer
type WorkerChan chan JobChan
我們分別維護一個全域性的job佇列和工作池。
var (
JobQueue JobChan
WorkerPool WorkerChan
)
worker的實現。每一個worker都有一個job channel,在啟動worker的時候會被註冊到work pool中。啟動後通過自身的job channel取到job並執行job。
type Worker struct {
JobChannel JobChan
quit chan bool
}
func (w *Worker) Start() {
go func() {
for {
// regist current job channel to worker pool
WorkerPool <- w.JobChannel
select {
case job := <-w.JobChannel:
if err := job.Do(); err != nil {
fmt.printf("excute job failed with err: %v", err)
}
// recieve quit event, stop worker
case <-w.quit:
return
}
}
}()
}
實現一個分發器(Dispatcher)。分發器包含一個worker的指標陣列,啟動時例項化並啟動最大數目的worker,然後從job佇列中不斷取job選擇可用的worker來執行job。
type Dispatcher struct {
Workers []*Worker
quit chan bool
}
func (d *Dispatcher) Run() {
for i := 0; i < MaxWorkerPoolSize; i++ {
worker := NewWorker()
d.Workers = append(d.Workers, worker)
worker.Start()
}
for {
select {
case job := <-JobQueue:
go func(job Job) {
jobChan := <-WorkerPool
jobChan <- job
}(job)
// stop dispatcher
case <-d.quit:
return
}
}
}