
O2O優惠券使用預測
一、背景
通過分析使用者線上線下的消費行為,建立模型,預測現階段使用者是否會在規定時間內使用相應優惠券,以便商家個性化投放,提高優惠券核銷率。
資料為使用者在2016年1月1日至2016年6月30日之間真實線上線下消費行為,預測使用者在2016年7月領取優惠券後15天以內的線下使用情況。
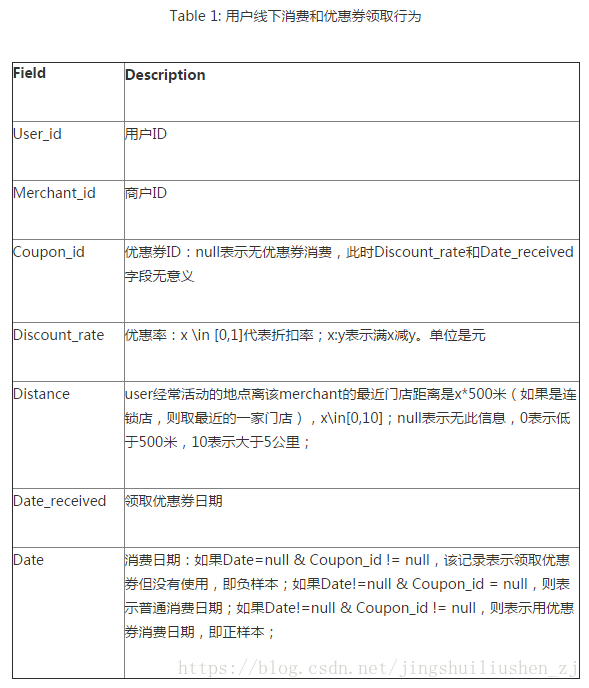
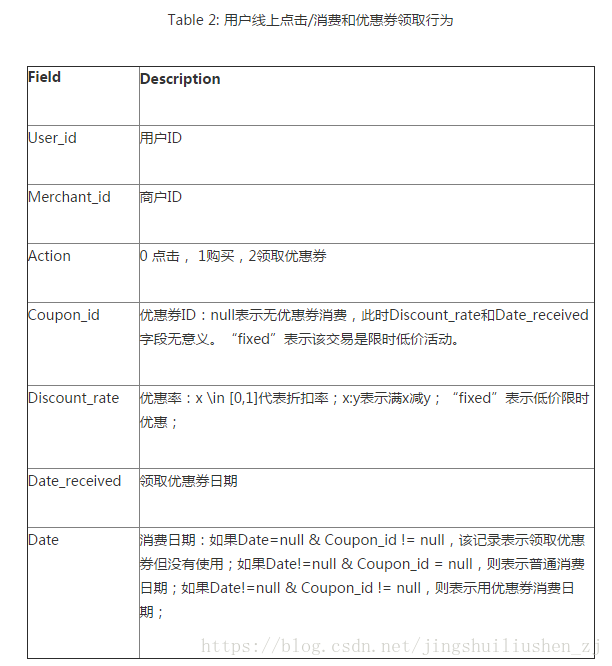
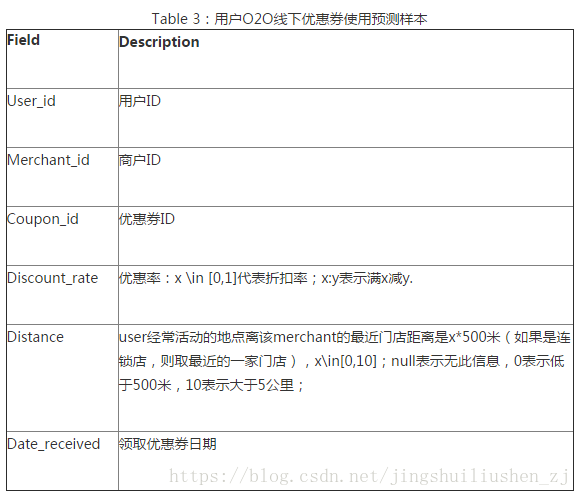
資料分析: 1、預測集中的使用者,是線下訓練資料集裡出現過的使用者,也就是老使用者。 2、根據經驗,我們知道活躍使用者更可能使用優惠券,活躍商家所發出的優惠券更可能被使用,使用者對某個商家的喜愛程度越高越可能使用這個商家發的優惠券 3、使用者在週末更有時間更可能使用優惠券 4、預測集中的商家,幾乎都是線下訓練資料集中出現過的商家。
二、資料預處理
本題所有資料記錄的時間區間是2016.01.01至2016.06.30,需要預測的是線下2016年7月份使用者領取優惠劵後15天內是否核銷。根據這兩份資料表,我們首先需要對資料集進行劃分(採用滑窗的方式),特徵區間為3.5個月,預測區間為一個月。要保證滑到最後,測試集的預測區間正好是7月。也可以用其他的方式劃分,特徵區間越小,得到的訓練資料集越多。
| 特徵區間(提取feature) | 預測區間(預測label) | |
|---|---|---|
| 訓練集 | 20160101~20160413 | 20160414~20160514 |
| 驗證集 | 20160201~20160514 | 20160515~20160615 |
| 測試集 | 20160315~20160630 | 20160701~20160731 |
為什麼要這樣劃分呢?第一,劃分訓練集和驗證集,方便我們交叉驗證;第二,我們的訓練和預測是與時間有關係的,如果是用train_test_split隨機劃分,可能會導致訓練資料是6月份,而預測資料卻是5月份,這與現實是不符合的,這就是資料洩露:
資料洩露就是說用了不該用的資料,比如 (1)在訓練模型時,利用了測試集的資料、資訊 (2)在當前使用了未來的資料 (3)在交叉驗證進行調參時,使用了驗證集的資訊參與模型建立 具體說下第三點,比如對特徵進行標準化,正確的方法應該是在訓練集上標準化,然後應用到驗證集上,而非先標準化,再劃分驗證集。再比如說,要對資料進行pca降維,應該是在訓練集上pca,然後作用到驗證集上,而非對整個資料集進行pca。通常都忽略了這一點。
如果資料集劃分的不好,可能會導致在訓練資料上效果很好,線下測試也還不錯,但是在線上表現卻不好。
注意資料集的劃分是不能只根據Date_Received(優惠券領取日期)來劃分,否則劃分出來的資料都是有優惠券的使用者,沒有領取優惠券的使用者資料都被丟棄了。 因為我們要預測的是使用者領取優惠券之後的使用情況,所以,預測區間可以根據使用者領取優惠券時間來劃分,特徵區間麻煩一點,如果消費時間不為空,通過消費時間劃分;如果消費時間為空,則根據優惠券領取時間劃分。(不能單純的用領取時間或消費時間劃分,因為這兩個時間都可能是空)
測試集的預測區間的劃分是從ccf_offline_stage1_test_revised.csv中讀取的。
#劃分特徵區間資料集,通過領取時間和消費時間
def filter_feature_data(data,start_time,end_time):
return data[((data['Date'] > start_time) & (data['Date'] < end_time))|((data['Date']=='null')&(data['Date_received'] > start_time) & (data['Date_received'] < end_time))]
#劃分預測區間資料集,根據領取時間
def filter_label_data(data,start_time,end_time):
return data[(data['Date_received'] > start_time) & (data['Date_received'] < end_time)]
#劃分線下資料集
def offline_data_split(origin,test_data):
#訓練集
train_feature_data=filter_feature_data(origin,train_feature_start_time,train_feature_end_time)
train_label_data=filter_label_data(origin,train_label_start_time,train_label_end_time)
#驗證集
validate_feature_data = filter_feature_data(origin, validate_feature_start_time, validate_feature_end_time)
validate_label_data = filter_label_data(origin, validate_label_start_time, validate_label_end_time)
#測試集
predict_feature_data = filter_feature_data(origin, predict_feature_start_time, predict_feature_end_time)
predict_label_data = filter_label_data(test_data.astype(str), predict_label_start_time, predict_label_end_time)
return train_feature_data,train_label_data,validate_feature_data,validate_label_data,predict_feature_data,predict_label_data
# 劃分線上資料集
def online_data_split(origin):
# 訓練集
train_feature_data = filter_feature_data(origin, train_feature_start_time, train_feature_end_time)
# 驗證集
validate_feature_data = filter_feature_data(origin, validate_feature_start_time, validate_feature_end_time)
# 測試集
predict_feature_data = filter_feature_data(origin, predict_feature_start_time, predict_feature_end_time)
return train_feature_data, validate_feature_data,predict_feature_data
檢視哪些列有空值:
data=pd.read_csv('data/ccf_offline_stage1_train.csv')
print(data.isnull().any())
輸出(True為有空值):
User_id False
Merchant_id False
Coupon_id True
Discount_rate True
Distance True
Date_received True
Date True
dtype: bool
三、特徵工程
特徵區間的特徵提取
我們的預測目標是七月份使用者領券使用情況,即用或者不用,轉化為二分類問題,然後通過分類演算法預測結果。 因此通過Date和Date_received兩個列來生成target。 然後是特徵提取,包括使用者特徵、商戶特徵、優惠券特徵、使用者商戶組合特徵、使用者優惠券組合特徵。
每一條消費記錄,除了本條提取出來的組合特徵,還有結合訓練集資料計算出來的特徵(比如使用者領取優惠券到消費的等待時間,這是一條的,而使用者優惠券的核銷率,這是通過整個資料集計算出的)。
注意我們預測七月份使用者領取優惠券的使用情況,就要根據使用者的歷史消費使用優惠券的情況,然後當該使用者七月份領取了優惠券之後,來判斷使用者是否會用掉這張優惠券。 使用者相關的特徵(以User_id為基準統計) 1、Date和Date_received兩列---->使用者領取優惠券消費次數、使用者無優惠券消費次數、使用者領取優惠券但沒有消費、使用者優惠券的核銷率 、優惠券領取到使用的時間等待,以15天為界,小於15天:。等待時間越短,這個值越大;大於15天:0. 2、Discount_rate分為兩種:直接折扣消費和滿減----->使用者直接折扣消費、使用者使用優惠券的滿減類別(以1234表示)、折扣率、使用者優惠券消費的各個滿減檔次的次數、使用者優惠券消費平均消費折率、限時低價消費次數(線上+線下) 3、Merchant_id、Coupon_id、Date三列:使用者優惠券消費過的不同商家數量 4、Coupon_id、Date兩列:使用者優惠券消費過的不同優惠券數量 5、Action:點選行為分三種,點選、購買、領取優惠券,每個型別的點選率。(線上) 商家相關的特徵(以Merchant_id為基準統計) 1、Coupon_id、Date兩列:無優惠券消費次數、獲得優惠券但沒有消費次數、優惠券消費次數、優惠券被領取後的核銷率 2、Discount_rate分為兩種:直接折扣消費和滿減----->使用者直接折扣消費、使用者使用優惠券的滿減類別(以1234表示)、折扣率、商家優惠券消費的各個滿減檔次的次數、使用者優惠券消費平均消費折率、 3、Date和Date_received兩列:領取到使用的時間等待 4、User_id、Coupon_id、Date三列:使用本商家優惠券消費過的不同使用者數量 5、User_id、Coupon_id、Date三列:使用者在本商家消費過的不同優惠券數量
使用者-商家相關的特徵(以User_id、Merchant_id為基準統計groupby([‘User_id’, ‘Merchant_id’]) Coupon_id、Date兩列:使用者對商家無優惠券消費次數、使用者對商家獲得優惠券但沒有消費次數、使用者對商家優惠券消費次數、使用者對商家優惠券被領取後的核銷率、使用者對每個商家的不消費次數佔用戶不消費的所有商家的比重、使用者對每個商家的優惠券消費次數佔用戶優惠券消費所有商家的比重、使用者對每個商家的普通消費次數佔用戶普通消費所有商家的比重
這三類特徵提取完成之後儲存在user_features.csv、merchant_features.csv、user_merchant_features.csv三個檔案中,注意,在每個檔案中的User_id是唯一的。
預測區間的特徵提取
這一部分就是結合預測區間的資料(1個月)和前面特徵區間提取出來的特徵資料(3.5個月)生成訓練資料。這個訓練資料就是用來訓練模型的。 因此這一部分依然需要提取特徵資料,除了特徵資料外,還要生成每一條記錄的target(除了最後的測試集的預測區間,它沒有label,是需要我們預測的)。
預測區間的特徵抽取: 1、距離。[0,10]範圍內的數字,/10,如果是空則設為-1. 2、優惠券型別:折扣0,滿減1(滿減檔次不同,也要考慮),無優惠券-1. 3、優惠券折率(主要是計算滿減的折率,折扣的不用計算,可以直接用) 4、使用者和優惠券之間的關係彙總:使用者領取的優惠券數量、使用者領取的每種優惠券的數量、商家被領取的優惠券的數量、商家被領取的每種優惠券的數量、使用者領取每個商家的優惠券數量。 5、使用者和商家的關係彙總:每個使用者相關的商家數量(或領取了優惠券、或購買了東西)、#每個商家相關的使用者數量(或領取了本商家的優惠券、或購買了本商家的東西)
預測區間生成target: Coupon_id、Date兩列非空且領取優惠券時間到消費時間<15天,這樣的target標為1,其餘的為0.
訓練資料:train_features.csv、 標籤資料:labels.csv 在train、validate、predict下各有一份。predict目錄下只有train_features.csv
四、模型訓練
1、xgboost模型訓練。 結果:
model.best_score: 0.868995, model.best_iteration: 91, model.best_ntree_limit: 92
output offline model data
Average auc of train matrix: 0.751128208956236
Average auc of validate matrix 0.6841286615724935
[[113670 5071]
[ 4948 3357]]
檔案執行順序: 1、data_split.py 劃分資料集,線上資料集產生六個檔案,分別是:offline_train_feature_data.csv、offline_train_label_data.csv、offline_validate_feature_data.csv、offline_validate_label_data.csv、 offline_predict_feature_data.csv、offline_train_label_data.csv 線下資料集產生3個檔案:online_train_feature_data.csv、online_validate_feature_data.csv、online_predict_feature_data.csv 2、feature_extract.py 特徵提取,針對訓練集、驗證集、測試集的特徵區間進行特徵提取,產生各自的特徵檔案:user_features.csv、merchant_features.csv、user_merchant_features.csv 3、gen_data.py 產生訓練模型用的資料,仍然是針對訓練集、驗證集、測試集,其中訓練集和驗證集各產生兩個檔案:train_features.csv(第2步產生的特徵.merge(預測區間的特徵))、labels.csv(預測區間的標籤),測試集只產生一個檔案:train_features.csv 4、利用第3步產生的訓練資料,進行模型的訓練,計算AUC值、best_score、混淆矩陣等,訓練好之後,進行test資料集的預測,將結果放在submission.csv中。
隨手記: 1、把常量提取出來在config.py中定義。 2、把資料集劃分後的結果分別寫在csv檔案中,把提取出的特徵DataFrame也寫在csv檔案中,這樣在除錯的時候,後期訓練模型就不用重複前面的操作了,直接讀取檔案就可。 3、pd.read_csv讀取檔案時,一定要注意keep_default_na=False屬性,這會影響後續的一系列資料處理和比較。
引數調優(使用交叉驗證):
- XGBoost內建交叉驗證“cv”,這個函式可以在每一次迭代中使用交叉驗證,並返回理想的決策樹數量(迭代的輪數)。
- 對於給定的學習速率和決策樹數量,使用GridSearchCV進行決策樹特定引數調優(max_depth, min_child_weight, gamma, subsample, colsample_bytree)。
- xgboost的正則化引數的調優。(lambda, alpha)。這些引數可以降低模型的複雜度,從而提高模型的表現。
- 降低學習速率,確定理想引數。
總結與收穫 大資料在實際場景中的應用 特徵提取對提高模型效果的重要性(劃分訓練集、特徵組合) 如何運用python進行資料處理,特徵提取 學習xgboost的引數設定與調優