
天池 O2O 優惠券使用預測思路解析與程式碼實戰
個人網站:redstonewill.com
前陣子因為機器學習訓練營的任務安排,需要打一場 AI 比賽。然後就瞭解到最近熱度很高且非常適合新人入門的一場比賽:天池新人實戰賽o2o優惠券使用預測。今天,紅色石頭把這場比賽的一些初級理論分析和程式碼實操分享給大家。本文會講解的很細,目的是帶領大家走一遍比賽流程,實現機器學習理論分析到比賽實戰的進階。話不多說,我們開始吧!
比賽介紹
首先附上這場比賽的連結:
本賽題的比賽背景是隨著移動裝置的完善和普及,移動網際網路+各行各業進入了高速發展階段,這其中以 O2O(Online to Offline)消費最為吸引眼球。本次大賽為參賽選手提供了 O2O 場景相關的豐富資料,希望參賽選手通過分析建模,精準預測使用者是否會在規定時間(15 天)內使用相應優惠券。
從機器學習模型的角度來說,這是一個典型的分類問題,其過程就是根據已有訓練集進行訓練,得到的模型再對測試進行測試並分類。整個過程如下圖所示:
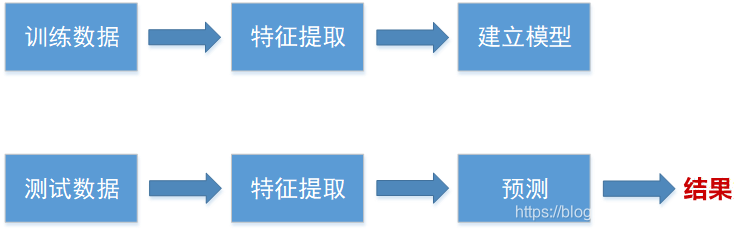
評估方式
我們知道評估一個機器學習模型有多種方式,最常見的例如準確率(Accuracy)、精確率(Precision)、召回率(Recall)。一般使用精確率和召回率結合的方式 F1 score 能較好地評估模型效能(特別是在正負樣本不平衡的情況下)。而在本賽題,官方規定的評估方式是 AUC,即 ROC 曲線與橫座標圍成的面積。如下圖所示:
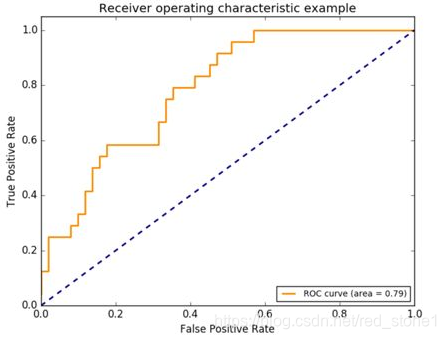
關於 ROC 和 AUC 的概念這裡不加解釋,至於為什麼要使用 ROC 和 AUC 呢?因為 ROC 曲線有個很好的特性:當測試集中的正負樣本的分佈變化的時候,ROC曲線能夠保持不變。也就是說能夠更好地處理正負樣本分佈不均的場景。
資料集匯入
對任何機器學習模型來說,資料集永遠是最重要的。接下來,我們就來看看這個比賽的資料集是什麼樣的。
首先來看一下大賽提供給我們的資料集:
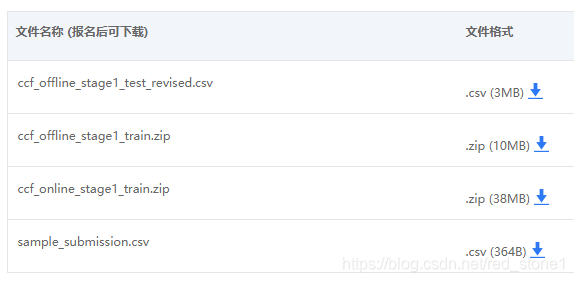
總共有四個檔案,分別是:
-
ccf_offline_stage1_test_revised.csv
-
ccf_offline_stage1_train.csv
-
ccf_online_stage1_train.csv
-
sample_submission.csv
其中,第 2 個是線下訓練集,第 1 個是線下測試集,第 3 個是線上訓練集(本文不會用到),第 4 個是預測結果提交到官網的檔案格式(需按照此格式提交才有效)。也就是說我們使用第 2 個檔案來訓練模型,對第 1 個檔案進行預測,得到使用者在 15 天內使用優惠券的概率值。
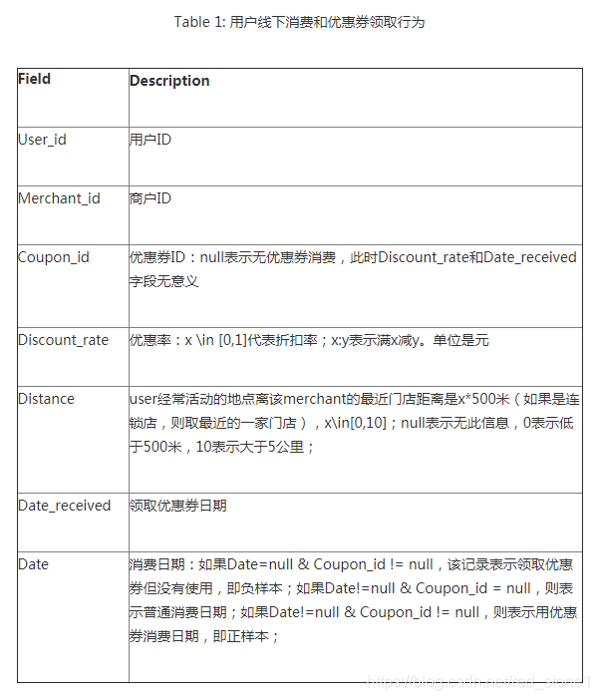
接下來,對 2、1、4 檔案中欄位進行列舉,欄位解釋如下圖所示。
ccf_offline_stage1_train.csv:
ccf_offline_stage1_test_revised.csv:
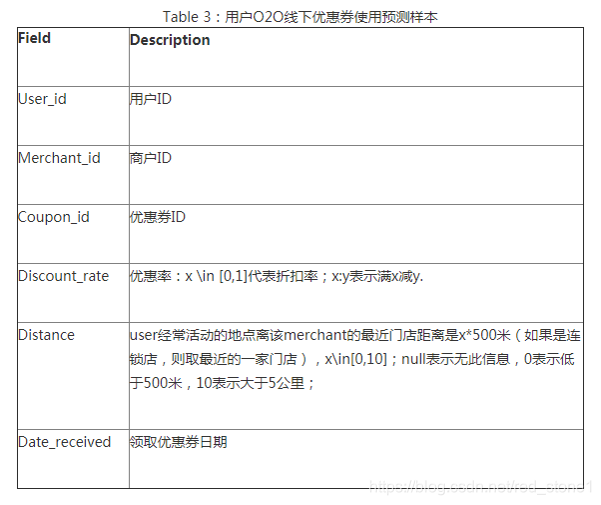
sample_submission.csv:

重點記住兩個欄位:Date_received 是領取優惠券日期,Date 是消費日期。待會我將詳細介紹。
介紹完幾個資料檔案和欄位之後,我們就來編寫程式,匯入訓練集和測試集,同時匯入需要用到的庫。
# import libraries necessary for this project
import os, sys, pickle
import numpy as np
import pandas as pd
from datetime import date
from sklearn.model_selection import KFold, train_test_split, StratifiedKFold, cross_val_score, GridSearchCV
from sklearn.pipeline import Pipeline
from sklearn.linear_model import SGDClassifier, LogisticRegression
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import log_loss, roc_auc_score, auc, roc_curve
from sklearn.preprocessing import MinMaxScaler
# display for this notebook
%matplotlib inline
%config InlineBackend.figure_format = 'retina'
匯入資料:
dfoff = pd.read_csv('data/ccf_offline_stage1_train.csv')
dfon = pd.read_csv('data/ccf_online_stage1_train.csv')
dftest = pd.read_csv('data/ccf_offline_stage1_test_revised.csv')
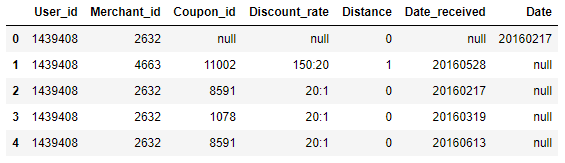
dfoff.head(5)
是訓練集前 5 行顯示如下:
接下來,我們來做個簡單統計,看一看究竟使用者是否使用優惠券消費的情況。
print('有優惠卷,購買商品:%d' % dfoff[(dfoff['Date_received'] != 'null') & (dfoff['Date'] != 'null')].shape[0])
print('有優惠卷,未購商品:%d' % dfoff[(dfoff['Date_received'] != 'null') & (dfoff['Date'] == 'null')].shape[0])
print('無優惠卷,購買商品:%d' % dfoff[(dfoff['Date_received'] == 'null') & (dfoff['Date'] != 'null')].shape[0])
print('無優惠卷,未購商品:%d' % dfoff[(dfoff['Date_received'] == 'null') & (dfoff['Date'] == 'null')].shape[0])
有優惠卷,購買商品:75382
有優惠卷,未購商品:977900
無優惠卷,購買商品:701602
無優惠卷,未購商品:0
可見,很多人(701602)購買商品卻沒有使用優惠券,也有很多人(977900)有優惠券但卻沒有使用,真正使用優惠券購買商品的人(75382)很少!所以,這個比賽的意義就是把優惠券送給真正可能會購買商品的人。
特徵提取
毫不誇張第說,構建機器學習模型,特徵工程可能比選擇哪種演算法更加重要。接下來,我們就來研究一下哪些特徵可能對模型訓練有用。
1.打折率(Discount_rate)
首先,第一個想到的特徵應該是優惠卷的打折率。因為很顯然,一般情況下優惠得越多,使用者就越有可能使用優惠券。那麼,我們就來看一下訓練集中優惠卷有哪些型別。
print('Discount_rate 型別:\n',dfoff['Discount_rate'].unique())
Discount_rate 型別:
[‘null’ ‘150:20’ ‘20:1’ ‘200:20’ ‘30:5’ ‘50:10’ ‘10:5’ ‘100:10’ ‘200:30’ ‘20:5’ >‘30:10’ ‘50:5’ ‘150:10’ ‘100:30’ ‘200:50’ ‘100:50’ ‘300:30’ ‘50:20’ ‘0.9’ ‘10:1’ >‘30:1’ ‘0.95’ ‘100:5’ ‘5:1’ ‘100:20’ ‘0.8’ ‘50:1’ ‘200:10’ ‘300:20’ ‘100:1’ >‘150:30’ ‘300:50’ ‘20:10’ ‘0.85’ ‘0.6’ ‘150:50’ ‘0.75’ ‘0.5’ ‘200:5’ ‘0.7’ >‘30:20’ ‘300:10’ ‘0.2’ ‘50:30’ ‘200:100’ ‘150:5’]
根據列印的結果來看,打折率分為 3 種情況:
-
‘null’ 表示沒有打折
-
[0,1] 表示折扣率
-
x:y 表示滿 x 減 y
那我們的處理方式可以構建 4 個函式,分別提取 4 種特徵,分別是:
-
打折型別:getDiscountType()
-
折扣率:convertRate()
-
滿多少:getDiscountMan()
-
減多少:getDiscountJian()
函式程式碼如下:
# Convert Discount_rate and Distance
def getDiscountType(row):
if row == 'null':
return 'null'
elif ':' in row:
return 1
else:
return 0
def convertRate(row):
"""Convert discount to rate"""
if row == 'null':
return 1.0
elif ':' in row:
rows = row.split(':')
return 1.0 - float(rows[1])/float(rows[0])
else:
return float(row)
def getDiscountMan(row):
if ':' in row:
rows = row.split(':')
return int(rows[0])
else:
return 0
def getDiscountJian(row):
if ':' in row:
rows = row.split(':')
return int(rows[1])
else:
return 0
def processData(df):
# convert discount_rate
df['discount_type'] = df['Discount_rate'].apply(getDiscountType)
df['discount_rate'] = df['Discount_rate'].apply(convertRate)
df['discount_man'] = df['Discount_rate'].apply(getDiscountMan)
df['discount_jian'] = df['Discount_rate'].apply(getDiscountJian)
print(df['discount_rate'].unique())
return df
然後,對訓練集和測試集分別進行進行 processData()函式的處理:
dfoff = processData(dfoff)
dftest = processData(dftest)
處理之後,我們可以看到訓練集和測試集都多出了 4 個新的特徵:discount_type、discount_rate、discount_man、discount_jian。

2.距離(Distance)
距離欄位表示使用者與商店的地理距離,顯然,距離的遠近也會影響到優惠券的使用與否。那麼,我們就可以把距離也作為一個特徵。首先看一下距離有哪些特徵值:
print('Distance 型別:',dfoff['Distance'].unique())
Distance 型別: [‘0’ ‘1’ ‘null’ ‘2’ ‘10’ ‘4’ ‘7’ ‘9’ ‘3’ ‘5’ ‘6’ ‘8’]
然後,定義提取距離特徵的函式:
# convert distance
dfoff['distance'] = dfoff['Distance'].replace('null', -1).astype(int)
print(dfoff['distance'].unique())
dftest['distance'] = dftest['Distance'].replace('null', -1).astype(int)
print(dftest['distance'].unique())
處理之後,我們可以看到訓練集和測試集都多出了 1 個新的特徵:distance。

3.領劵日期(Date_received)
是還有一點很重要的是領券日期,因為一般而言,週末領取優惠券去消費的可能性更大一些。因此,我們可以構建關於領券日期的一些特徵:
-
weekday : {null, 1, 2, 3, 4, 5, 6, 7}
-
weekday_type : {1, 0}(週六和週日為1,其他為0)
-
Weekday_1 : {1, 0, 0, 0, 0, 0, 0}
-
Weekday_2 : {0, 1, 0, 0, 0, 0, 0}
-
Weekday_3 : {0, 0, 1, 0, 0, 0, 0}
-
Weekday_4 : {0, 0, 0, 1, 0, 0, 0}
-
Weekday_5 : {0, 0, 0, 0, 1, 0, 0}
-
Weekday_6 : {0, 0, 0, 0, 0, 1, 0}
-
Weekday_7 : {0, 0, 0, 0, 0, 0, 1}
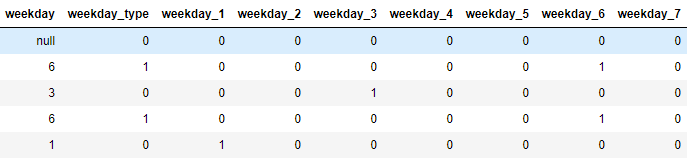
其中用到了獨熱編碼,讓特徵更加豐富。相應的這 9 個特徵的提取函式為:
def getWeekday(row):
if row == 'null':
return row
else:
return date(int(row[0:4]), int(row[4:6]), int(row[6:8])).weekday() + 1
dfoff['weekday'] = dfoff['Date_received'].astype(str).apply(getWeekday)
dftest['weekday'] = dftest['Date_received'].astype(str).apply(getWeekday)
# weekday_type : 週六和週日為1,其他為0
dfoff['weekday_type'] = dfoff['weekday'].apply(lambda x: 1 if x in [6,7] else 0)
dftest['weekday_type'] = dftest['weekday'].apply(lambda x: 1 if x in [6,7] else 0)
# change weekday to one-hot encoding
weekdaycols = ['weekday_' + str(i) for i in range(1,8)]
#print(weekdaycols)
tmpdf = pd.get_dummies(dfoff['weekday'].replace('null', np.nan))
tmpdf.columns = weekdaycols
dfoff[weekdaycols] = tmpdf
tmpdf = pd.get_dummies(dftest['weekday'].replace('null', np.nan))
tmpdf.columns = weekdaycols
dftest[weekdaycols] = tmpdf
這樣,我們就會在訓練集和測試集上發現增加了 9 個關於領券日期的特徵:
好了,經過以上簡單的特徵提取,我們總共得到了 14 個有用的特徵:
-
discount_rate
-
discount_type
-
discount_man
-
discount_jian
-
distance
-
weekday
-
weekday_type
-
weekday_1
-
weekday_2
-
weekday_3
-
weekday_4
-
weekday_5
-
weekday_6
-
weekday_7
好了,我們的主要工作已經完成了大半!
標註標籤 Label
有了特徵之後,我們還需要對訓練樣本進行 label 標註,即確定哪些是正樣本(y = 1),哪些是負樣本(y = 0)。我們要預測的是使用者在領取優惠券之後 15 之內的消費情況。所以,總共有三種情況:
1.Date_received == ‘null’:
表示沒有領到優惠券,無需考慮,y = -1
2.(Date_received != ‘null’) & (Date != ‘null’) & (Date - Date_received <= 15):
表示領取優惠券且在15天內使用,即正樣本,y = 1
3.(Date_received != ‘null’) & ((Date == ‘null’) | (Date - Date_received > 15)):
表示領取優惠券未在在15天內使用,即負樣本,y = 0
好了,知道規則之後,我們就可以定義標籤備註函數了。
def label(row):
if row['Date_received'] == 'null':
return -1
if row['Date'] != 'null':
td = pd.to_datetime(row['Date'], format='%Y%m%d') - pd.to_datetime(row['Date_received'], format='%Y%m%d')
if td <= pd.Timedelta(15, 'D'):
return 1
return 0
dfoff['label'] = dfoff.apply(label, axis=1)
我們可以使用這個函式對訓練集進行標註,看一下正負樣本究竟有多少:
print(dfoff['label'].value_counts())
0 988887
-1 701602
1 64395
Name: label, dtype: int64
很清晰地,正樣本共有 64395 例,負樣本共有 988887 例。顯然,正負樣本數量差別很大。這也是為什麼會使用 AUC 作為模型效能評估標準的原因。
建立模型
接下來就是最主要的建立機器學習模型了。首先確定的是我們選擇的特徵是上面提取的 14 個特徵,為了驗證模型的效能,需要劃分驗證集進行模型驗證,劃分方式是按照領券日期,即訓練集:20160101-20160515,驗證集:20160516-20160615。我們採用的模型是簡單的 SGDClassifier。
1.劃分訓練集和驗證集
# data split
df = dfoff[dfoff['label'] != -1].copy()
train = df[(df['Date_received'] < '20160516')].copy()
valid = df[(df['Date_received'] >= '20160516') & (df['Date_received'] <= '20160615')].copy()
print('Train Set: \n', train['label'].value_counts())
print('Valid Set: \n', valid['label'].value_counts())
2.構建模型
def check_model(data, predictors):
classifier = lambda: SGDClassifier(
loss='log', # loss function: logistic regression
penalty='elasticnet', # L1 & L2
fit_intercept=True, # 是否存在截距,預設存在
max_iter=100,
shuffle=True, # Whether or not the training data should be shuffled after each epoch
n_jobs=1, # The number of processors to use
class_weight=None) # Weights associated with classes. If not given, all classes are supposed to have weight one.
# 管道機制使得引數集在新資料集(比如測試集)上的重複使用,管道機制實現了對全部步驟的流式化封裝和管理。
model = Pipeline(steps=[
('ss', StandardScaler()), # transformer
('en', classifier()) # estimator
])
parameters = {
'en__alpha': [ 0.001, 0.01, 0.1],
'en__l1_ratio': [ 0.001, 0.01, 0.1]
}
# StratifiedKFold用法類似Kfold,但是他是分層取樣,確保訓練集,測試集中各類別樣本的比例與原始資料集中相同。
folder = StratifiedKFold(n_splits=3, shuffle=True)
# Exhaustive search over specified parameter values for an estimator.
grid_search = GridSearchCV(
model,
parameters,
cv=folder,
n_jobs=-1, # -1 means using all processors
verbose=1)
grid_search = grid_search.fit(data[predictors],
data['label'])
return grid_search
模型採用的是 SGDClassifier,使用了 Python 中的 Pipeline 管道機制,可以使引數集在新資料集(比如測試集)上的重複使用,管道機制實現了對全部步驟的流式化封裝和管理。交叉驗證採用 StratifiedKFold,其用法類似 Kfold,但是 StratifiedKFold 是分層取樣,確保訓練集,測試集中各類別樣本的比例與原始資料集中相同。
3.訓練
接下來就可以使用該模型對訓練集進行訓練了,整個訓練過程大概 1-2 分鐘的時間。
predictors = original_feature
model = check_model(train, predictors)
4.驗證
然後對驗證集中每個優惠券預測的結果計算 AUC,再對所有優惠券的 AUC 求平均。計算 AUC 的時候,如果 label 只有一類,就直接跳過,因為 AUC 無法計算。
# valid predict
y_valid_pred = model.predict_proba(valid[predictors])
valid1 = valid.copy()
valid1['pred_prob'] = y_valid_pred[:, 1]
valid1.head(5)
注意這裡得到的結果 pred_prob 是概率值(預測樣本屬於正類的概率)。
最後,就可以對驗證集計算 AUC。直接呼叫 sklearn 庫自帶的計算 AUC 函式即可。
# avgAUC calculation
vg = valid1.groupby(['Coupon_id'])
aucs = []
for i in vg:
tmpdf = i[1]
if len(tmpdf['label'].unique()) != 2:
continue
fpr, tpr, thresholds = roc_curve(tmpdf['label'], tmpdf['pred_prob'], pos_label=1)
aucs.append(auc(fpr, tpr))
print(np.average(aucs))
0.532344469452
最終得到的 AUC 就等於 0.53。
測試
訓練完模型之後,就是使用訓練好的模型對測試集進行測試了。並且將測試得到的結果(概率值)按照規定的格式儲存成一個 .csv 檔案。
# test prediction for submission
y_test_pred = model.predict_proba(dftest[predictors])
dftest1 = dftest[['User_id','Coupon_id','Date_received']].copy()
dftest1['Probability'] = y_test_pred[:,1]
dftest1.to_csv('submit.csv', index=False, header=False)
dftest1.head(5)
值得注意的是,這裡得到的結果是概率值,最終的 AUC 是提交到官網之後平臺計算的。因為測試集真正的 label 我們肯定是不知道的。
提交結果
好了,最後一步就是在比賽官網上提交我們的預測結果,即這裡的 submit.csv 檔案。提交完之後,過幾個小時就可以看到成績了。整個比賽的流程就完成了。
優化模型
其實,本文所述的整個比賽思路和演算法是比較簡單的,得到的結果和成績也只能算是合格,名次不會很高。我們還可以運用各種手段優化模型,簡單來說分為以下三種:
-
特徵工程
-
機器學習
-
模型融合
總結
本文的主要目的是帶領大家走一遍整個比賽的流程,培養一些比賽中特徵提取和演算法應用方面的知識。這個天池比賽目前還是比較火熱的,雖然沒有獎金,但是參賽人數已經超過 1.1w 了。看完本文之後,希望大家有時間去參加感受一下機器學習比賽的氛圍,將理論應用到實戰中去。
本文完整的程式碼我已經放在了 GitHub 上,有需要的請自行領取:
https://github.com/RedstoneWill/MachineLearningInAction-Camp/tree/master/Week4/o2o%20Code_Easy
同時,本比賽第一名的程式碼也開源了,一同放出,供大家學習:
https://github.com/wepe/O2O-Coupon-Usage-Forecast
