期末大作業,最後一週上課檢查(更新)
阿新 • • 發佈:2018-12-17
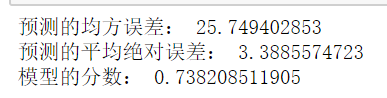
一、boston房價預測 #1.讀取資料 from sklearn.datasets import load_boston #匯入房價資料集 boston=load_boston() boston.data #讀取房價資料 boston.target boston.data.shape #2.訓練集與測試集劃分 from sklearn.model_selection import train_test_split #匯入訓練集和測試集包 x_train,x_test,y_train,y_test=train_test_split(boston.data,boston.target,test_size=0.3) #劃分訓練集與測試集 #3.線性迴歸模型:建立13個變數與房價之間的預測模型,並檢測模型好壞。 from sklearn.linear_model import LinearRegression LineR=LinearRegression() #線性迴歸 LineR.fit(x_train,y_train) #對資料進行訓練 print(LineR.coef_,LineR.intercept_) #通過資料訓練得出迴歸方程的斜率和截距 from sklearn.metrics import regression # 檢測模型好壞 y_pred= LineR.predict(x_test) print("預測的均方誤差:", regression.mean_squared_error(y_test,y_pred)) # 計算模型的預測指標 print("預測的平均絕對誤差:", regression.mean_absolute_error(y_test,y_pred)) print("模型的分數:",LineR.score(x_test, y_test)) # 輸出模型的分數 #4.多項式迴歸模型:建立13個變數與房價之間的預測模型,並檢測模型好壞。 from sklearn.preprocessing import PolynomialFeatures poly=PolynomialFeatures(degree=2) x_poly_train=poly.fit_transform(x_train) LineR=LinearRegression() #建立多項迴歸模型 LineR.fit(x_poly_train,y_train) x_poly_test=poly.transform(x_test) #多項迴歸預測模型 y_pred1=LineR.predict(x_poly_test) # 檢測模型好壞 print("預測的均方誤差:", regression.mean_squared_error(y_test,y_pred1)) print("預測的平均絕對誤差:", regression.mean_absolute_error(y_test,y_pred1)) # 計算模型的預測指標 print("模型的分數:",LineR.score(x_poly_test, y_test)) # 輸出模型的分數 5. 比較線性模型與非線性模型的效能,並說明原因。 線性迴歸模型和非線性迴歸模型的區別是:線性就是每個變數的指數都是1,而非線性就是至少有一個變數的指數不是1。 線性迴歸模型,是利用數理統計中迴歸分析,來確定兩種或兩種以上變數間相互依賴的定量關係的一種統計分析方法。 而非線性迴歸,是在掌握大量觀察資料的基礎上,利用數理統計方法建立因變數與自變數之間的迴歸關係函式表示式(稱迴歸方程式)。迴歸分析中,當研究的因果關係只涉及因變數和一個自變數時,叫做一元迴歸分析;當研究的因果關係涉及因變數和兩個或兩個以上自變數時,叫做多元迴歸分析。