
語音識別ASR技術通識
上午看了一篇文章: 語音識別的痛點在哪,從互動到精準識別如何做? | 硬創公開課 感覺沒看懂,下午就看到了團長精心總結的這篇ASR技術通識。給個大大的��!
語音識別(Automatic Speech Recognition),一般簡稱ASR;是將聲音轉化為文字的過程,相當於人類的耳朵。
語音識別原理流程:“輸入——編碼——解碼——輸出”
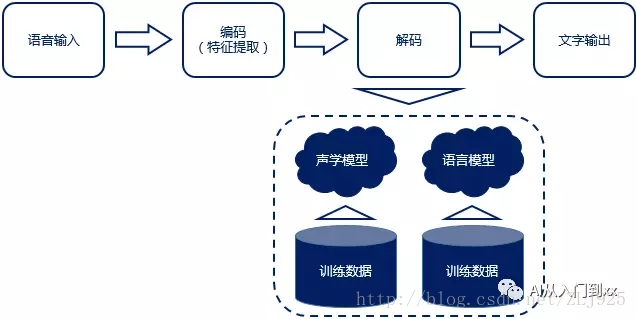
1、語音識別,大體可分為“傳統”識別方式與“端到端”識別方式,其主要差異就體現在聲學模型上。
“傳統”方式的聲學模型一般採用隱馬爾可夫模型(HMM),而“端到端”方式一般採用深度神經網路(DNN)。
語音識別的應用,就這麼簡單?不是的,在實際場景,有很多種異常情況,都會導致語音識別的效果大打折扣,比如距離太遠了不行,發音不標準不行,環境嘈雜不行,想打斷也不行,等等。所以,還需要有各種解決方案來配合。
2、遠場語音識別(Farfield Voice Recognition)
遠場語音識別,簡稱遠場識別,口語中可更簡化為“遠場”。下面主要說3個概念:
語音啟用檢測、語音喚醒、以及麥克風陣列。
1)語音啟用檢測(voice active detection,VAD)
A)需求背景:在近場識別場景,比如使用語音輸入法時,使用者可以用手按著語音按鍵說話,結束之後鬆開,由於近場情況下信噪比(signal to noise ratio, SNR))比較高,訊號清晰,簡單演算法也能做到有效可靠。 但遠場識別場景下,使用者不能用手接觸裝置,這時噪聲比較大,SNR下降劇烈,必須使用VAD了。
B)定義:判斷什麼時候有語音什麼時候沒有語音(靜音)。 後續的語音訊號處理或是語音識別都是在VAD截取出來的有效語音片段上進行的。
2)語音喚醒 (voice trigger,VT)
A)需求背景:在近場識別時,使用者可以點選按鈕後直接說話,但是遠場識別時,需要在VAD檢測到人聲之後,進行語音喚醒,相當於叫這個AI(機器人)的名字,引起ta的注意,比如蘋果的“Hey Siri”,Google的“OK Google”,亞馬遜Echo的“Alexa”等。
B)定義:可以理解為喊名字,引起聽者的注意。 VT判斷是喚醒(啟用)詞,那後續的語音就應該進行識別了;否則,不進行識別。
C)難點:語音識別,不論遠場還是進場,都是在雲端進行,但是語音喚醒基本是在(裝置)本地進行的,要求更高——
C.1)喚醒響應時間。據傅盛說,世界上所有的音箱,除了Echo和他們做的小雅智慧音箱能達到1.5秒之外,其他的都在3秒以上。
C.2)功耗要低。iphone 4s出現Siri,但直到iphone 6s之後才允許不接電源的情況下直接喊“hey Siri”進行語音喚醒。這是因為有6s上有一顆專門進行語音啟用的低功耗晶片,當然演算法和硬體要進行配合,演算法也要進行優化。
C.3)喚醒效果。喊它的時候它不答應這叫做漏報,沒喊它的時候它跳出來講話叫做誤報。漏報和誤報這2個指標,是此消彼長的,比如,如果喚醒詞的字數很長,當然誤報少,但是漏報會多;如果喚醒詞的字數很短,漏報少了,但誤報會多,特別如果大半夜的突然唱歌或講故事,會特別嚇人的……
C.4)喚醒詞。技術上要求,一般最少3個音節。比如“OK google”和“Alexa”有四個音節,“hey Siri”有三個音節;國內的智慧音箱,比如小雅,喚醒詞是“小雅小雅”,而不能用“小雅”。
注:一般產品經理或行業交流時,直接說漢語“語音喚醒”,而英文縮寫“VT”,技術人員可能用得多些。
3)麥克風陣列(Microphone Array)
A)需求背景:在會議室、戶外、商場等各種複雜環境下,會有噪音、混響、人聲干擾、回聲等各種問題。特別是遠場環境,要求拾音麥克風的靈敏度高,這樣才能在較遠的距離下獲得有效的音訊振幅,同時近場環境下又不能爆音(振幅超過最大量化精度)。另外,家庭環境中的牆壁反射形成的混響對語音質量也有不可忽視的影響。
B)定義:由一定數目的聲學感測器(一般是麥克風)組成,用來對聲場的空間特性進行取樣並處理的系統。

C)能幹什麼 a)語音增強(Speech Enhancement):當語音訊號被各種各樣的噪聲(包括語音)干擾甚至淹沒後,從含噪聲的語音訊號中提取出純淨語音的過程。
b)聲源定位(Source Localization):使用麥克風陣列來計算目標說話人的角度和距離,從而實現對目標說話人的跟蹤以及後續的語音定向拾取。
c)去混響(Dereverberation):聲波在室內傳播時,要被牆壁、天花板、地板等障礙物形成反射聲,並和直達聲形成疊加,這種現象稱為混響。

d)聲源訊號提取/分離:聲源訊號的提取就是從多個聲音訊號中提取出目標訊號,聲源訊號分離技術則是需要將多個混合聲音全部提取出來。

D)分類 a)按陣列形狀分:線性、環形、球形麥克風。 在原理上,三者並無太大區別,只是由於空間構型不同,導致它們可分辨的空間範圍也不同。
比如,在聲源定位上,線性陣列只有一維資訊,只能分辨180度; 環形陣列是平面陣列,有兩維資訊,能分辨360度; 球性陣列是立體三維空間陣列,有三維資訊,能區分360度方位角和180度俯仰角。
b)按麥克風個數分:單麥、雙麥、多麥 麥克風的個數越多,對說話人的定位精度越高,在嘈雜環境下的拾音質量越高; 但如果互動距離不是很遠,或者在一般室內的安靜環境下,5麥和8麥的定位效果差異不是很大。
傅盛說,全行業能做“6+1”麥克風陣列(環形對稱分佈6顆,圓心中間有1顆)的公司可能不超過兩三家,包括獵戶星空(以前行業內叫獵豹機器人)在內。而Google Home目前採用的是2mic的設計。
E)問題
a)距離太遠時(比如10m、20m),錄製訊號的信噪比會很低,演算法處理難度很大;
b)對於便攜裝置來說,受裝置尺寸以及功耗的限制,麥克風的個數不能太多,陣列尺寸也不能太大。——分散式麥克風陣列技術則是解決當前問題的一個可能途徑。
c)麥克風陣列技術仍然還有很大的提升空間,尤其是背景噪聲很大的環境裡,如家裡開電視、開空調、開電扇,或者是在汽車裡面等等。
整體來說,遠場語音識別時,需要前後端結合去完成。
一方面在前端使用麥克風陣列硬體,通過聲源定位及自適應波束形成做語音增強,在前端完成遠場拾音,並解決噪聲、混響、回聲等帶來的影響。
另一方面,由於近場、遠場的語音訊號,在聲學上有一定的規律差異,所以在後端的語音識別上,還需要結合基於大資料訓練、針對遠場環境的聲學模型,才能較好解決識別率的問題。
4)全雙工(Full-Duplex)
A)需求背景:在傳統的語音喚醒方案中,是一次喚醒後,進行語音識別和互動,互動完成再進入待喚醒狀態。但是在實際人與人的交流中,人是可以與多人對話的,而且支援被其他人插入和打斷。
B)定義: 單工:a和b說話,b只能聽a說 半雙工:參考對講機,A:能不能聽到我說話,over;B:可以可以,over 全雙工:參考打電話,A:哎,老王啊!balabala……;B:balabala……
C)包含feature 人聲檢測、智慧斷句、拒識(無效的語音和無關說話內容)和回聲消除(Echo Cancelling,在播放的同時可以拾音) 特別說下回聲消除的需求背景:近場環境下,播放音樂或是語音播報的時候可以按鍵停止這些,但遠場環境下,遠端揚聲器播放的音樂會回傳給近端麥克風,此時就需要有效的回聲消除演算法來抑制遠端訊號的干擾。
5)糾錯 A)需求背景:做了以上硬體、演算法優化後,語音識別就會OK了嗎?還不夠。因為還會因為同音字(詞)等各種異常情況,導致識別出來的文字有偏差,這時,就需要做“糾錯”了。
B)使用者主動糾錯。 比如使用者語音說“我們今天,不對,明天晚上吃啥?”,經過雲端的自然語言理解過程,可以直接顯示使用者真正希望的結果“我們明天晚上吃啥”。

C)根據場景/功能領域不同,AI來主動糾錯。這裡,根據糾錯目標資料的來源,可以進一步劃分為3種:
a)本地為主。 比如,打電話功能。我們一位聯合創始人名字叫郭家,如果說“打電話給guo jia時”,一般語音識別默認出現的肯定是“國家”,但(手機)本地會有通訊錄,所以可以根據拼音,優先在通訊錄中尋找更匹配(相似度較高)的名字——郭家。就顯示為“打電話給郭家”。
b)本地+雲端。 比如,音樂功能。使用者說,“我想聽XX(歌曲名稱)”時,可以優先在本地的音樂庫中去找相似度較高的歌曲名稱,然後到雲端曲庫去找,最後再合在一起(排序)。 我們之前實際測試中發現過的“糾錯例子”包括: 夜半小夜曲—>月半小夜曲 讓我輕輕地告訴你—>讓我輕輕的告訴你 他說—>她說 望凝眉—>枉凝眉 一聽要幸福—>一定要幸福 苦啥—>哭砂 鴿子是個傳說—>哥只是個傳說
c)雲端為主。 比如地圖功能,由於POI(Point of Interest,興趣點,指地理位置資料)資料量太大,直接到雲端搜尋可能更方便(除非是“家”、“公司”等個性化場景)。比如,使用者說“從武漢火車站到東福”,可以被糾正為“從武漢火車站到東湖”。
二、當前技術邊界 各家公司在宣傳時,會說語音識別率達到了97%,甚至98%,但那一般是需要使用者在安靜環境下,近距離、慢慢的、認真清晰發音;而在一些實際場景,很可能還不夠好的,比如——
1、比如在大家都認為相對容易做的翻譯場景,其實也還沒完全可用,臺上演示是一回事,普通使用者使用是另一回事;特別是在一些垂直行業,領域知識很容易出錯;另外,還可詳見《懟一懟那些假機器同傳》
2、車載 大概3、4年前,我們內部做過針對車載場景的語言助手demo,拿到真實場景內去驗證,結果發現,車內語音識別效果非常不理想。而且直到今年,我曾經面試過一位做車內語音互動系統的產品經理,發現他們的驗收方其實也沒有特別嚴格的測試,因為大家都知道,那樣怎麼也通過不了。。。 車內語音識別的難點很多,除了多人說話的干擾,還有胎噪、風噪,以及經常處於離線情況。 據說有的公司專門在做車內降噪,還有些公司想通過智慧硬體來解決,至少目前好像還沒有哪個產品解決好了這個問題,並且獲得了使用者的口碑稱讚的。
3、家庭場景,由於相對安靜和可控,如果遠場做好了,還是有希望的。
4、中英文混合。 特別在聽歌場景,使用者說想聽某首英文歌時,很容易識別錯誤的。這方面,只有傅盛的小雅音箱據說做了很多優化,有待使用者檢驗。
總之,ASR是目前AI領域,相對最接近商用成熟的技術,但還是需要使用者可以配合AI在特定場景下使用。這是不是問題呢?是問題,但其實不影響我們做產品demo和初步的產品化工作,所以反而是我們AI產品經理的發揮機會。
三、瓶頸和機會 1、遠場語音識別,是最近2年的重要競爭領域。因為家庭(音箱)等場景有可能做好、在被催熟。 2、更好的機會在垂直細分領域,比如方言(方言識別能夠支援40多種,而百度有20多種)、特定人群的聲學匹配方案(兒童)
附:相關資料 1、文章 1)《傅盛:人工智慧的破局點是技術和產品結合 | 獵戶星空釋出小雅語音》t.cn/Ro61HkJ
2)《語音識別的痛點在哪,從互動到精準識別如何做?》t.cn/RKFhkUy
3)《自然的語音互動——麥克風陣列》t.cn/RcjwjH9
4)(偏技術)《語音識別的技術原理是什麼?》t.cn/RxkIccJ
5)(偏技術)《語音識別如何處理漢字中的「同音字」現象?》t.cn/RKDhxIT
6)(偏技術)《如何構建中英文混合的語音識別模型?》t.cn/RKDh9DD
2、書籍 網上有人推薦《解析深度學習:語音識別實踐》by @俞棟 ;語音識別工具包是 kaldi。
以上內容,來自飯糰“AI產品經理大本營”,點選這裡可關注:http://fantuan.guokr.net/groups/219/ (如果遇到支付問題,請先關注飯糰的官方微信服務號“fantuan-app”)
作者:黃釗hanniman,圖靈機器人-人才戰略官,前騰訊產品經理,5年AI實戰經驗,8年網際網路背景,微信公眾號/知乎/在行ID“hanniman”,飯糰“AI產品經理大本營”,分享人工智慧相關原創乾貨,200頁PPT《人工智慧產品經理的新起點》被業內廣泛好評,下載量1萬+。