
TensorFlow影象識別(物體分類)入門教程
本文主要介紹瞭如何使用TensorFlow環境執行一個最基本的影象分類器(Win10系統)。原始碼地址https://github.com/sourcedexter/tfClassifier/tree/master/image_classification (這個大神好像改名了,原來叫akshaypai來著)
一.基礎概念介紹
1.物體分類的思想
物體分類,也就是訓練系統識別各個物體,如貓咪、狗狗、汽車等。TensorFlow是谷歌開發出的人工智慧學習系統,相當於我們的執行環境。
2.神經網路與Inception v3體系結構模型
神經網路示意圖如下: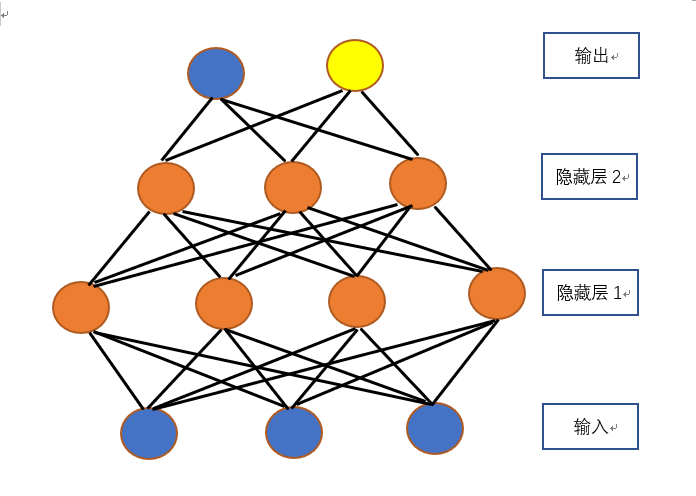
通俗了講,就是將若干個輸入,進行若干次操作(線性或者非線性),最後輸出結果。Inception v3模型是谷歌釋出的一個深層卷積網路模型。我們使用的retrain_new.py指令碼就是使用了Inception v3模型進行一個遷移學習。
3.訓練集、測試集和驗證集
訓練集用來訓練模型,驗證集用來驗證模型是否進行了過擬合,測試集用來測試模型的準確程度。三種圖片集的比例會對準確度產生影響。
4.學習速率
不同的學習速率會導致不同的結果。如果速率過大,會導致準確率在訓練的過程中不斷上下跳動,如果速率過小會導致在訓練結束前無法到達預期準確度。
二.環境搭建
1.Python環境搭建
2.TensorFlow環境搭建(gpu)
(1)直接pip安裝。命令:
pip install tensorflow-gpu這樣就安裝好TensorFlow了,但是我們還需要GPU加速,所以還需要安裝cuda和cuDnn(專門為deep learning準備的加速庫)。
(2)cuda安裝
下載完後正常安裝就可以了。
(3)cuDnn庫下載
下載完後解壓縮,出現如下資料夾結構:
然後將這三個資料夾下的檔案分別拷貝到cuda對應的資料夾下面就行了。
到這裡還不能完整的執行,還需要配置一下環境變數:cuda安裝完成後預設的環境變數配置不對,CUDA_PATH是C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v8.0,但是這樣不能直接訪問到bin和lib\x64下的程式包,在path中加上這兩個路徑即可。
(4)測試
用如下程式碼測試:
import tensorflow as tf
hello = tf.constant('Hello, TensorFlow!')
sess = tf.Session()三.基本使用
1.資料集的收集與建立
我用的是2018全球AI挑戰賽的資料集。連結:https://challenger.ai/datasets/lad2018
下載完後,將所有資料夾都放在一個資料夾下(我自己建立了一個叫DataSet),結構如下: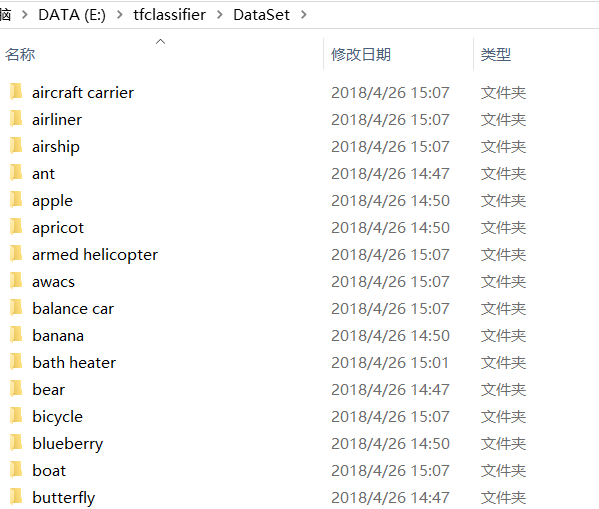
資料夾的名字就是最後輸出的分類的結果。
每一個資料夾下都是圖片(不能再有子資料夾),即:
2.訓練模型
訓練模型使用retrain_new.py指令碼。在命令列執行,命令格式如下:python retrain_new.py --model_dir 存放classify_image_graph_def.pb的路徑 --image_dir 剛才的建立的DataSet的路徑 --output_graph 產生的,pb檔案的存放路徑 --output_labels 產生的output_labels.txt的 存放路徑 --how_many_training_steps 訓練步數 --learning_rate 學習速率 --testing_percentage 測試集比例 --validation_percentage 驗證集比例
示例命令:
python retrain_new.py --model_dir E:\tfclassifier\image_classification\inception --image_dir E:\tfclassifier\DataSet --output_graph E:\tfclassifier\image_classification\output_dir\output_graph.pb --output_labels E:\tfclassifier\image_classification\output_dir\output_labels.txt --how_many_training_steps 500 --learning_rate 0.3 --testing_percentage 10 --validation_percentage 10說明:
model_dir引數:指定了model的存放位置,就是我們的inception資料夾
image_dir引數:指定了資料集的位置
output_graph引數:產生的output_graph.pb檔案的存放路徑(後面要用)
output_labels 引數:產生的output_labels.txt的存放路徑(後面要用)
how_many_training_steps引數:訓練步數,和學習速率配合調整(我用的500)
learning_rate引數:學習速率,和訓練步數配合調整(我用的0.3,常用的有0.001,0.01,0.1,0.3,1,3,可自己調整嘗試一下)
testing_percentage引數:測試集比例
validation_percentage引數:驗證集比例
注意:訓練會在根目錄下生成一個tmp資料夾,存放相關檔案,即:
3.測試模型
核心的檔案是output_graph.pb檔案(我們訓練所產生的圖,是一個二進位制檔案)和output_labels.txt檔案。 使用retrain_model_classifier.py指令碼來測試模型。命令格式如下: E: cd E:\tfclassifier\image_classification(進入retrain_model_classifier.py指令碼所在的目錄) python retrain_model_classifier.py 要識別圖片的路徑 例如: python retrain_model_classifier.py D:\test2\testPic.jpg
然後會看到一些版本資訊,和輸出結果(紅框部分):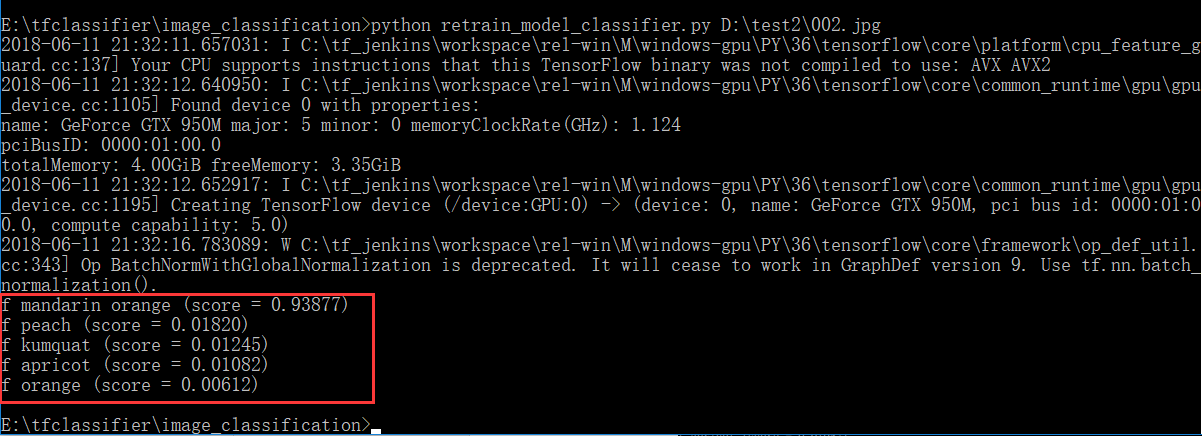
四.遇到的問題以及解答
1.版本對應問題
Python版本,cuda版本和cuDNN版本都是對應的,如果結果中出現了亂碼,很大概率是版本的問題。
2.帶引數的python指令碼編寫與執行
想讓python指令碼帶引數,可以在python指令碼的末尾新增如下格式的程式碼:
執行時需要在python xxx.py後加上“--image_dir 引數”就可以了。
3.測試指令碼的調整
要不斷訓練、測試,不斷調整引數,直到訓練快要結束的時候,驗證比例達到穩定,並且在90以上,我們才認為系統較為完善。