
爬蟲 智聯招聘
阿新 • • 發佈:2018-12-18
1,原理
通過Python的requests庫,向網站伺服器傳送請求,伺服器返回相關網頁的原始碼,再通過正則表示式等方式在網頁原始碼中提取出我們想要的資訊。
2,網頁分析
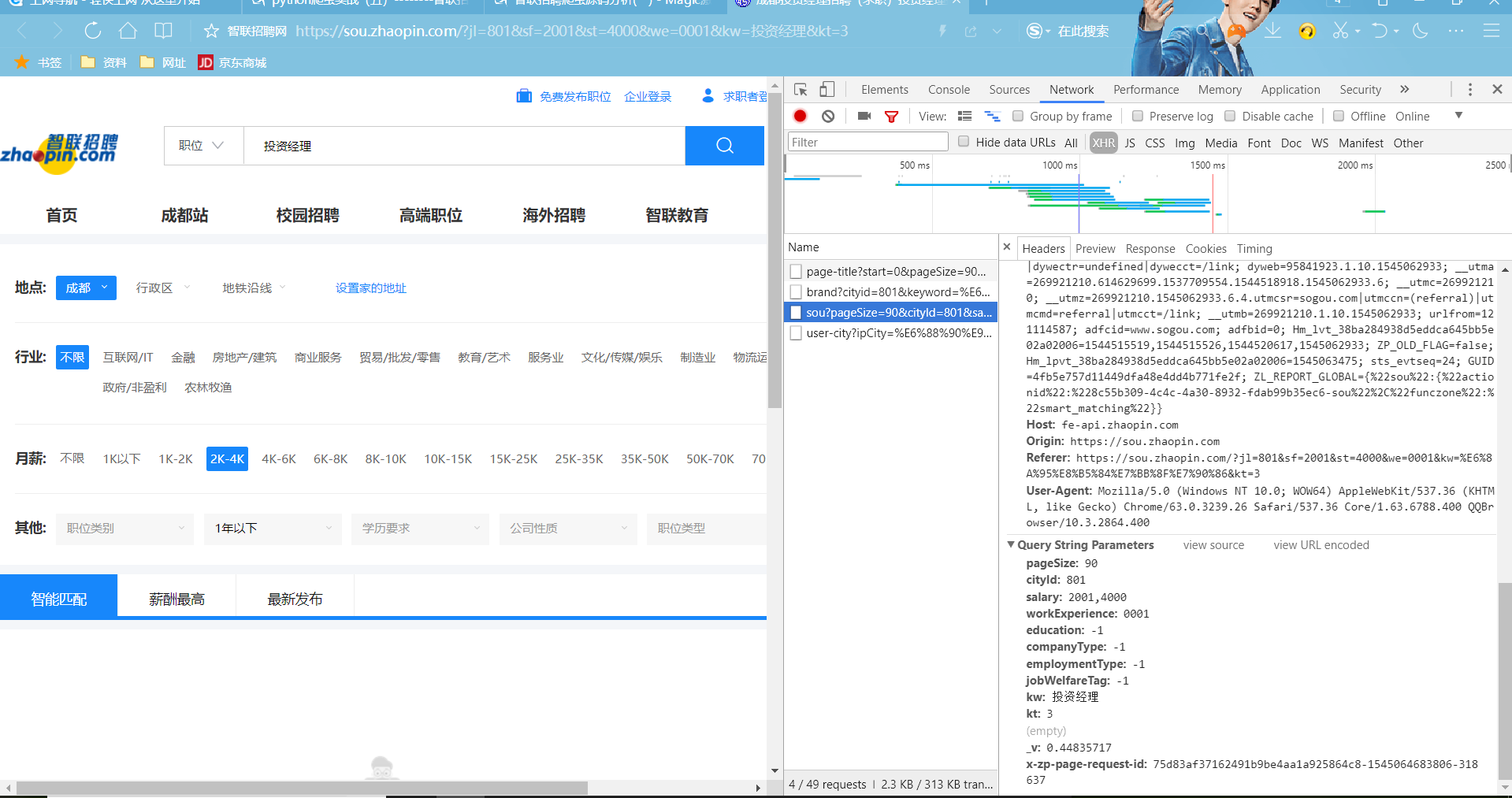
通過對網址分析,kw=投資經理和搜尋欄的收縮內容一樣,sf=2001&st=4000和選擇工資2k-4k有一定的關係,we=0001和工資經驗一年以下。我們看network -XHR中的Query String Parameters中對應的工資等等都有一定關聯。
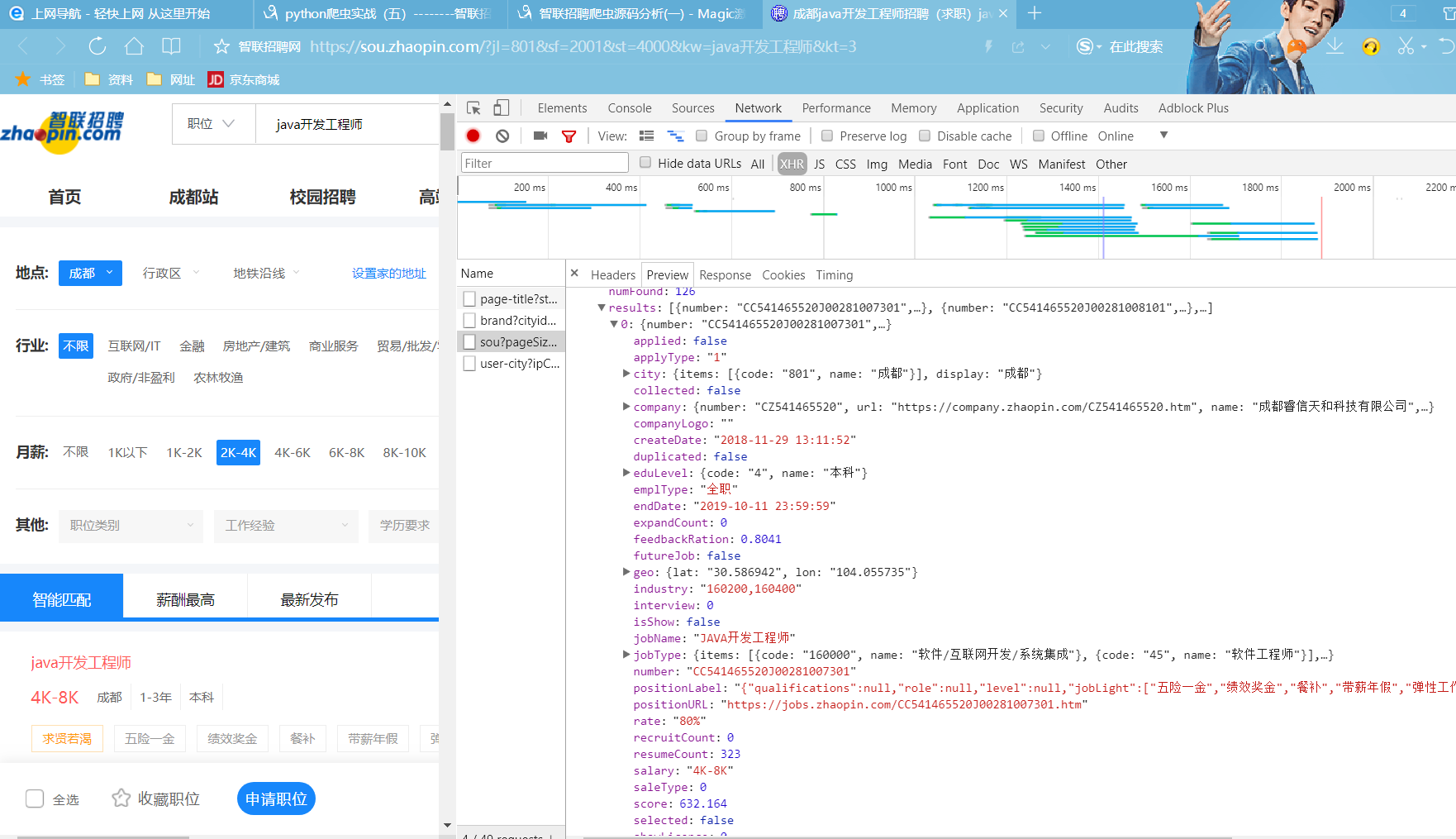
我們看到網頁的一些招聘資訊在Preview中的results中一 一對應。
import csv |