
大資料----Spark中的 決策樹 及 SVM 建模
#一、演算法解釋
使用決策樹二元分類分析StumbleUpon資料集,預測網頁是暫時性(Ephemeral)或是長青的(Evergreen), 並且調校引數找出最佳引數組合,提高預測準確度。決策樹的優點:條例清晰、方法簡單、易於理解、使用範圍廣等。
決策樹介紹: 當我們使用決策樹分類演算法訓練資料後,會以 feature(特徵欄位)與label(標籤欄位)建立決策樹。
###決策樹
當我們使用歷史資料執行訓練時會建立決策樹。可是決策樹不可能無限成長,因此我們必須限制它的最大分支與深度,
所以必須設定下列引數:
-a. maxBins 引數:
決策時每一個節點最大分支數
-b. maxDepth 引數:
決策樹最大深度
-c. Impurity 引數:
決策樹分裂節點時的方法,為什麼選擇特徵進行分支
當樹的父節點在分裂子節點時,以什麼方法作為依據?例如,溼度以60為分割點,分為大於60或小於60;或者溼度
以50為分割點,分為大於50或小於50.到底哪種方式比較好呢?此時有Gini 與 Entropy 兩種判斷方式:
-i. 基於係數**(Gini)**:
由義大利統計學家Corrado Gini 發明,用於計算數值散步程度(Statistical Dispersion,統計離差)的指標。
決策樹演算法對每種特徵欄位分割點計算估值,選擇分裂後最小的基尼指數(Gini)方式。
-ii. 熵(Entropy):
熵(Entropy)也被用於計算機系統混亂的程度。決策樹演算法對每種特徵欄位分割點計算估值,選擇分裂後最小的熵(Entropy)方式。
###SVM
SVM,即Support Vector Machine(支援向量機),是一種使用線性分割平面的二元分類演算法。其原理是通過尋求結構化風險最小來提高學習機泛化能力,實現經驗風險和置信範圍的最小化,從而達到在統計樣本量較少的情況下,亦能獲得良好統計規律的目的。其基本模型定義為特徵空間上的間隔最大的線性分類器,即支援向量機的學習策略便是間隔最大化,最終可轉化為一個凸二次規劃問題的求解。
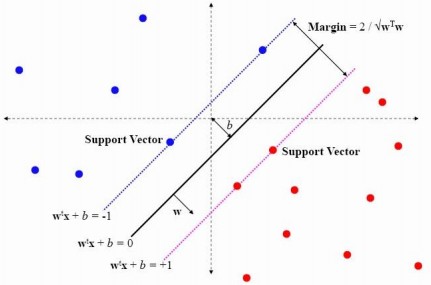
###建立步驟
"""
構建機器學習模型步驟;
1、如何蒐集資料 ?
歷史資料
2、如何進行資料準備 ?
提取特徵欄位和標籤欄位 - 特徵工程 (花費時間最多的)
3、如何訓練模型 ?
使用什麼演算法進行訓練模型
4、如何使用模型預測 ?
使用訓練的模型如決策樹模型,進行預測
5、如何評估模型的準確率?
使用某一個標準來評估模型的準確率,二元分類中使用 AUC 作為評估標準
6、模型訓練引數如何影響準確率?
訓練模型時,針對演算法傳遞不同的引數將會影響準確率和訓練時間。
如使用決策樹演算法,其中引數impurity、maxDepth、maxBins的值設定
7、如何找出準確率最高的引數組合?
不同的引數,不同的組合得到的模型不一樣,準確率也不癢。
8、如何確認是否Overfiiting(過度訓練,過擬合):
Overfiting(過度訓練)是指機器學習所學到的模型過度貼近trainData,從而導致誤差變得很大。
我們使用另一組資料testData再次測試,以避免overfitting的問題。
- 如果訓練評估階段是AUC很高,但是測試階段AUC很低,代表可能有overfitting的問題。
- 如果測試與訓練評估階段的結果中AUC差異不大,就代表無overfitting的問題。
"""