
OpenCV3.3中決策樹(Decision Tree)介面簡介及使用
OpenCV 3.3中給出了決策樹Decision Tres演算法的實現,即cv::ml::DTrees類,此類的宣告在include/opencv2/ml.hpp檔案中,實現在modules/ml/src/tree.cpp檔案中。其中:
(1)、cv::ml::DTrees類:繼承自cv::ml::StateModel,而cv::ml::StateModel又繼承自cv::Algorithm;
(2)、create函式:為static,new一個DTreesImpl物件用來建立一個DTrees物件;
(3)、setMaxCategories/getMaxCategories函式:設定/獲取最大的類別數,預設值為10;
(4)、setMaxDepth/getMaxDepth函式:設定/獲取樹的最大深度,預設值為INT_MAX;
(5)、setMinSampleCount/getMinSampleCount函式:設定/獲取最小訓練樣本數,預設值為10;
(6)、setCVFolds/getCVFolds函式:設定/獲取CVFolds(thenumber of cross-validation folds)值,預設值為10,如果此值大於1,用於修剪構建的決策樹;
(7)、setUseSurrogates/getUseSurrogates函式:設定/獲取是否使用surrogatesplits方法,預設值為false;
(8)、setUse1SERule/getUse1SERule函式:設定/獲取是否使用1-SE規則,預設值為true;
(9)、setTruncatePrunedTree/getTruncatedTree函式:設定/獲取是否進行剪枝後移除操作,預設值為true;
(10)、setRegressionAccuracy/getRegressionAccuracy函式:設定/獲取迴歸時用於終止的標準,預設值為0.01;
(11)、setPriors/getPriors函式:設定/獲取先驗概率數值,用於調整決策樹的偏好,預設值為空的Mat;
(12)、getRoots函式:獲取根節點索引;
(13)、getNodes函式:獲取所有節點索引;
(14)、getSplits函式:獲取所有拆分索引;
(15)、getSubsets函式:獲取分類拆分的所有bitsets;
(16)、load函式:load已序列化的model檔案。
以下是從資料集MNIST中提取的40幅影象,0,1,2,3四類各20張,每類的前10幅來自於訓練樣本,用於訓練,後10幅來自測試樣本,用於測試,如下圖:

測試程式碼如下:
#include "opencv.hpp"
#include <string>
#include <vector>
#include <memory>
#include <algorithm>
#include <opencv2/opencv.hpp>
#include <opencv2/ml.hpp>
#include "common.hpp"
///////////////////////////////////// Decision Tree ////////////////////////////////////////
int test_opencv_decision_tree_train()
{
const std::string image_path{ "E:/GitCode/NN_Test/data/images/digit/handwriting_0_and_1/" };
cv::Mat tmp = cv::imread(image_path + "0_1.jpg", 0);
CHECK(tmp.data != nullptr);
const int train_samples_number{ 40 };
const int every_class_number{ 10 };
cv::Mat train_data(train_samples_number, tmp.rows * tmp.cols, CV_32FC1);
cv::Mat train_labels(train_samples_number, 1, CV_32FC1);
float* p = (float*)train_labels.data;
for (int i = 0; i < 4; ++i) {
std::for_each(p + i * every_class_number, p + (i + 1)*every_class_number, [i](float& v){v = (float)i; });
}
// train data
for (int i = 0; i < 4; ++i) {
static const std::vector<std::string> digit{ "0_", "1_", "2_", "3_" };
static const std::string suffix{ ".jpg" };
for (int j = 1; j <= every_class_number; ++j) {
std::string image_name = image_path + digit[i] + std::to_string(j) + suffix;
cv::Mat image = cv::imread(image_name, 0);
CHECK(!image.empty() && image.isContinuous());
image.convertTo(image, CV_32FC1);
image = image.reshape(0, 1);
tmp = train_data.rowRange(i * every_class_number + j - 1, i * every_class_number + j);
image.copyTo(tmp);
}
}
cv::Ptr<cv::ml::DTrees> dtree = cv::ml::DTrees::create();
dtree->setMaxCategories(4);
dtree->setMaxDepth(10);
dtree->setMinSampleCount(10);
dtree->setCVFolds(0);
dtree->setUseSurrogates(false);
dtree->setUse1SERule(false);
dtree->setTruncatePrunedTree(false);
dtree->setRegressionAccuracy(0);
dtree->setPriors(cv::Mat());
dtree->train(train_data, cv::ml::ROW_SAMPLE, train_labels);
const std::string save_file{ "E:/GitCode/NN_Test/data/decision_tree_model.xml" }; // .xml, .yaml, .jsons
dtree->save(save_file);
return 0;
}
int test_opencv_decision_tree_predict()
{
const std::string image_path{ "E:/GitCode/NN_Test/data/images/digit/handwriting_0_and_1/" };
const std::string load_file{ "E:/GitCode/NN_Test/data/decision_tree_model.xml" }; // .xml, .yaml, .jsons
const int predict_samples_number{ 40 };
const int every_class_number{ 10 };
cv::Mat tmp = cv::imread(image_path + "0_1.jpg", 0);
CHECK(tmp.data != nullptr);
// predict datta
cv::Mat predict_data(predict_samples_number, tmp.rows * tmp.cols, CV_32FC1);
for (int i = 0; i < 4; ++i) {
static const std::vector<std::string> digit{ "0_", "1_", "2_", "3_" };
static const std::string suffix{ ".jpg" };
for (int j = 11; j <= every_class_number + 10; ++j) {
std::string image_name = image_path + digit[i] + std::to_string(j) + suffix;
cv::Mat image = cv::imread(image_name, 0);
CHECK(!image.empty() && image.isContinuous());
image.convertTo(image, CV_32FC1);
image = image.reshape(0, 1);
tmp = predict_data.rowRange(i * every_class_number + j - 10 - 1, i * every_class_number + j - 10);
image.copyTo(tmp);
}
}
cv::Mat result;
cv::Ptr<cv::ml::DTrees> dtrees = cv::ml::DTrees::load(load_file);
dtrees->predict(predict_data, result);
CHECK(result.rows == predict_samples_number);
cv::Mat predict_labels(predict_samples_number, 1, CV_32FC1);
float* p = (float*)predict_labels.data;
for (int i = 0; i < 4; ++i) {
std::for_each(p + i * every_class_number, p + (i + 1)*every_class_number, [i](float& v){v = (float)i; });
}
int count{ 0 };
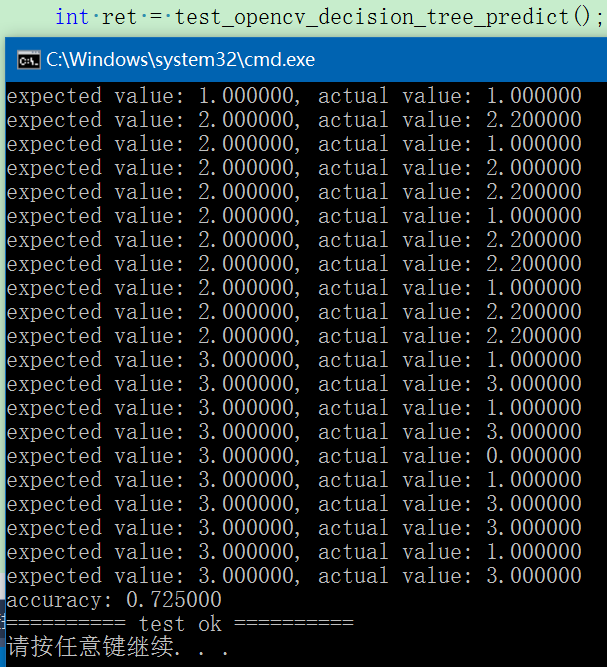
for (int i = 0; i < predict_samples_number; ++i) {
float value1 = ((float*)predict_labels.data)[i];
float value2 = ((float*)result.data)[i];
fprintf(stdout, "expected value: %f, actual value: %f\n", value1, value2);
if (int(value1) == int(value2)) ++count;
}
fprintf(stdout, "accuracy: %f\n", count * 1.f / predict_samples_number);
return 0;
}
相關推薦
OpenCV3.3中決策樹(Decision Tree)介面簡介及使用
OpenCV 3.3中給出了決策樹Decision Tres演算法的實現,即cv::ml::DTrees類,此類的宣告在include/opencv2/ml.hpp檔案中,實現在modules/ml/src/tree.cpp檔案中。其中:(1)、cv::ml::DTrees類
機器學習入門 - 1. 介紹與決策樹(decision tree)
recursion machine learning programmming 機器學習(Machine Learning) 介紹與決策樹(Decision Tree)機器學習入門系列 是 個人學習過程中的一些記錄與心得。其主要以要點形式呈現,簡潔明了。1.什麽是機器學習?一個比較概括的理解是:
決策樹 ( decision tree)詳解
決策樹演算法的基本流程 決策樹顧名思義就是基於樹對問題的決策和判別的過程,是人類在面對決策問題時一種很自然的處理機制,下面有個例子 通過決策樹得出最終的結果。 &nb
決策樹(Decision Tree) | 繪製決策樹
01 起 在這篇文章中,我們講解了如何訓練決策樹,然後我們得到了一個字典巢狀格式的決策樹結果,這個結果不太直觀,不能一眼看著這顆“樹”的形狀、分支、屬性值等,怎麼辦呢? 本文就上文得到的決策樹,給出決策樹繪製函式,讓我們對我們訓練出的決策樹一目瞭然。 在繪製決
決策樹 (decision tree)
通過訓練,我們可以從樣本中學習到決策樹,作為預測模型來預測其它樣本。兩個問題: 我們說要訓練/學習,訓練/學習什麼? 為什麼決策樹可以用來預測?或者說它的泛化能力的來源是哪? #什麼是決策樹? 一棵“樹”,目的和作用是“決策”。一般來說,每個節點上都儲存了一個切分,輸入資料通過切分繼續訪問子節點,直到葉
決策樹 Decision Tree 簡介
決策樹(Decision Tree)及其變種是另一類將輸入空間分成不同的區域,每個區域有獨立引數的演算法。決策樹分類演算法是一種基於例項的歸納學習方法,它能從給定的無序的訓練樣本中,提煉出樹型的分類模型。樹中的每個非葉子節點記錄了使用哪個特徵來進行類別的判斷,每個葉子節點則代表
機器學習方法(四):決策樹Decision Tree原理與實現技巧
歡迎轉載,轉載請註明:本文出自Bin的專欄blog.csdn.net/xbinworld。 技術交流QQ群:433250724,歡迎對演算法、技術、應用感興趣的同學加入。 前面三篇寫了線性迴歸,lasso,和LARS的一些內容,這篇寫一下決策樹這個經典的分
機器學習---決策樹decision tree的應用
1.Python 2.Python機器學習的庫:scikit-learn 2.1 特性: 簡單高效的資料探勘和機器學習分析 對所有使用者開放,根據不同需求高度可重用性 基於Numpy,SciPy和matplotlib 開源的,且可達到商用級別,獲
【機器學習演算法-python實現】決策樹-Decision tree(1) 資訊熵劃分資料集
1.背景 決策書演算法是一種逼近離散數值的分類演算法,思路比較簡單,而且準確率較高。國際權威的學術組織,資料探勘國際會議ICDM (the IEEE International Con
4 決策樹(Decision Tree)
決策樹是一種基本的分類與迴歸方法 以下內容討論用於分類的決策樹,是由訓練資料集估計條件概率的模型 在學習時,利用訓練資料,根據損失函式最小化的原則建立決策樹,模型 在預測時,對新的資料,利用決策樹模型
演算法雜貨鋪——分類演算法之決策樹(Decision tree)
http://www.cnblogs.com/leoo2sk/archive/2010/09/19/decision-tree.html 3.1、摘要 在前面兩篇文章中,分別介紹和討論了樸素貝葉斯分類與貝葉斯網路兩種分類演算法。這兩種演算法都以貝葉斯定
機器學習之決策樹 Decision Tree(三)scikit-learn演算法庫
1、scikit-learn決策樹演算法類庫介紹 scikit-learn決策樹演算法類庫內部實現是使用了調優過的CART樹演算法,既可以做分類,又可以做迴歸。分類決策樹的類對應的是DecisionTreeClassifier,而回歸決策樹的類對應的是D
決策樹(decision tree)的自我理解 (上)
最近在看周志華的《機器學習》,剛好看完決策樹這一章,因此結合網上的一些參考資料寫一下自己的理解。 何為決策樹? 決策樹是一種常見機器學習方法中的一種分類器。它通過訓練資料構建一種類似於流程圖的樹結構,
分類演算法之決策樹(Decision tree)
1.1、決策樹引導 通俗來說,決策樹分類的思想類似於找物件。現想象一個女孩的母親要給這個女孩介紹男朋友,於是有了下面的對話: 女兒:多大年紀了? 母親:26。 女兒:長的帥不帥? 母親:挺帥的。 女兒:
決策樹decision tree分析
本文目的 最近一段時間在Coursera上學習Data Analysis,裡面有個assignment涉及到了決策樹,所以參考了一些決策樹方面的資料,現在將學習過程的筆記整理記錄於此,作為備忘。 演算法原理 決策樹(Decision Tree)是一種簡單但是廣泛使
決策樹(decision tree)的自我理解 (下) 關於剪枝和連續值缺失值處理
對剪枝的粗淺理解 剪枝分預剪枝和後剪枝,顧名思義,預剪枝就是在樹還沒完成之前,預先剪去樹的部分分支,後剪枝就是在整棵樹完成了之後對樹剪去部分分支,從而完成了對樹的精簡操作,避免了因屬性太多而造成的過擬合。 預剪枝(prepruning):在決策樹生成過程中,對每個結點在劃分
決策樹decision tree+SVM+knn+隨機森林+高斯貝葉斯
很多分類器的用法都相似的,下面針對一個訓練集(特徵向量+類別) 介紹幾種常用的分類器方法: 資料集的介紹: kaggle 中 泰坦尼克號的資料集,通過某些特徵提取的方法構造成清洗後的資料集,同時按相同的處理方法處理測試集。 七個特徵屬性+一個決策屬性 不同分類器方法的用法: XTrain與Y
機器學習-決策樹 Decision Tree
咱們正式進入了機器學習的模型的部分,雖然現在最火的的機器學習方面的庫是Tensorflow, 但是這裡還是先簡單介紹一下另一個數據處理方面很火的庫叫做sklearn。其實咱們在前面已經介紹了一點點sklearn,主要是在categorical data encoding那一塊。其實sklearn在資料建模方面
Python sklearn庫中決策樹tree.DecisionTreeClassifier()函式引數介紹
max_leaf_nodes:int,None 可選(預設為None) 在最優方法中使用max_leaf_nodes構建一個樹。最好的節點是在雜質相對減少。如果是None則對葉節點的數目沒有限制。如果不是None則不考慮max_depth.class_weight:dict,list of dicts,
spark機器學習庫指南[Spark 1.3.1版]——決策樹(decision trees)
fuqingchuan 機器學習 2015-03-22 3,477 次瀏覽 GINI, spark, 決策樹, 熵 spark機器學習庫指南[Spark 1.3.1版]——決策樹(decision trees)已關閉評論 下面是章節決策