
Spark讀寫Hbase的二種方式對比
作者:Syn良子 出處:http://www.cnblogs.com/cssdongl 轉載請註明出處
一.傳統方式
這種方式就是常用的TableInputFormat和TableOutputFormat來讀寫hbase,如下程式碼所示
![commonSparkHbaseReadWrite_thumb[1]](http://images2015.cnblogs.com/blog/1050555/201612/1050555-20161230184436148-1613467404.png)
簡單解釋下,用sc.newAPIHadoopRDD根據conf中配置好的scan來從Hbase的資料列族中讀取包含(ImmutableBytesWritable, Result)的RDD,
隨後取出rowkey和value的鍵值對兒利用StatCounter進行一些最大最小值的計算最終寫入hbase的統計列族.
二.SparkOnHbase方式
重點介紹第二種方式,這種方式其實是利用Cloudera-labs開源的一個HbaseContext的工具類來支援spark用RDD的方式批量讀寫hbase,先給個傳送門大家感受下
雖然這個hbase-spark的module在Hbase上的整合任務很早就完成了,但是已知釋出的任何版本我還沒找到該模組,不知道什麼情況,再等等吧
那麼問題來了,這種方式的優勢在哪兒呢,官方的解釋我翻譯如下
1>無縫的使用Hbase connection
2>和Kerberos無縫整合
3>通過get或者scan直接生成rdd
4>利用RDD支援hbase的任何組合操作
5>為通用操作提供簡單的方法,同時通過API允許不受限制的未知高階操作
6>支援java和scala
7>為spark和 spark streaming提供相似的API
ok,由於hbaseContext是一個只依賴hadoop,hbase,spark的jar包的工具類,因此可以拿過來直接用
廢話不說,直接用我除錯過的程式碼來感受下
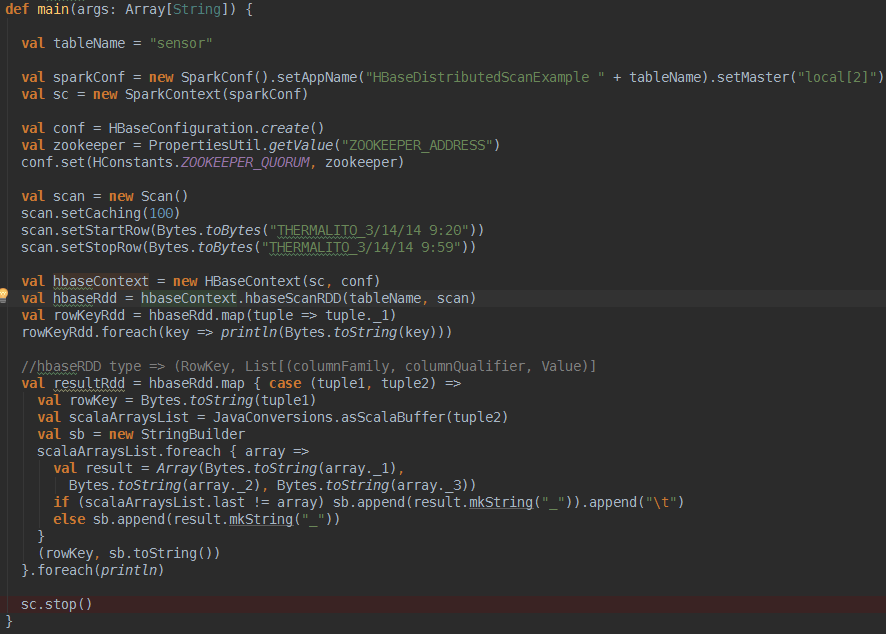
想用HbaseContext很簡單,如上面程式碼所示,需要說明的是hbaseContext的hbaseScanRDD方法,這個方法返回的是一個
(RowKey, List[(columnFamily, columnQualifier, Value)]型別的RDD,如下剛開始用的挺不習慣的.還得迴圈取出來rowkey對應的這麼多列,這裡你如果對它的RDD返回型別不爽,官方很貼心的提供了另外一個方法怎麼樣,是不是看著很眼熟了?你可以自定義第三個引數(ImmutableBytesWritable, Result),對函式f進行自定義來返回你自己喜歡的RDD格式,
程式執行結果如下,過濾出了9:20到9:58所有的rowkey以及對應的列

當然HbaseContext還有其他bulkGet,bulkPut,bulkDelete等,都是可以直接將hbase的操作轉換成RDD,只要轉成RDD了,那麼rdd的這麼多transform和action就可以玩的很happy了.
參考資料