
Spark讀寫Hbase資料
阿新 • • 發佈:2019-08-06
環境
spark: 2.4.3
hbase: 1.1.5
步驟
- 啟動hadoop-3.1.2,hbase2.2.0
把HBase的lib目錄下的一些jar檔案拷貝到Spark中,這些都是程式設計時需要引入的jar包,需要拷貝的jar檔案包括:所有hbase開頭的jar檔案、guava-12.0.1.jar、protobuf-java-2.5.0.jar
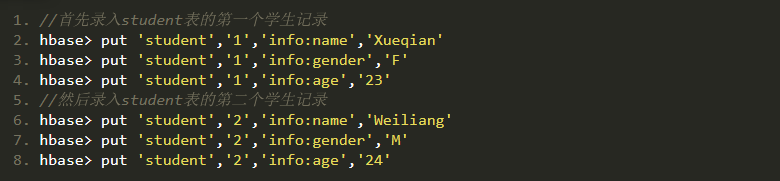
- hbase建表,插入資料
- idea開發spark操作hbase程式碼
build.sbt

- spark讀取hbase資料
import org.apache.hadoop.hbase.client.Put import org.apache.hadoop.hbase.mapreduce.TableInputFormat import org.apache.hadoop.hbase.util.Bytes import org.apache.hadoop.hbase.{HBaseConfiguration, TableName} import org.apache.spark.{SparkConf, SparkContext} object SparkOperateHBase { def main(args: Array[String]) { val conf = HBaseConfiguration.create() val sc = new SparkContext(new SparkConf()) //設定查詢的表名 conf.set(TableInputFormat.INPUT_TABLE, "student") val stuRDD = sc.newAPIHadoopRDD(conf, classOf[TableInputFormat], classOf[org.apache.hadoop.hbase.io.ImmutableBytesWritable], classOf[org.apache.hadoop.hbase.client.Result]) val count = stuRDD.count() println("Students RDD Count:" + count) stuRDD.cache() //遍歷輸出 stuRDD.foreach({ case (_,result) => val key = Bytes.toString(result.getRow) val name = Bytes.toString(result.getValue("info".getBytes,"name".getBytes)) val gender = Bytes.toString(result.getValue("info".getBytes,"gender".getBytes)) val age = Bytes.toString(result.getValue("info".getBytes,"age".getBytes)) println("Row key:"+key+" Name:"+name+" Gender:"+gender+" Age:"+age) }) } }
- spark寫入hbase資料
import org.apache.hadoop.hbase.mapreduce.TableOutputFormat import org.apache.spark._ import org.apache.hadoop.mapreduce.Job import org.apache.hadoop.hbase.io.ImmutableBytesWritable import org.apache.hadoop.hbase.client.Result import org.apache.hadoop.hbase.client.Put import org.apache.hadoop.hbase.util.Bytes object SparkWriteHBase { def main(args: Array[String]): Unit = { val sparkConf = new SparkConf().setAppName("SparkWriteHBase").setMaster("local") val sc = new SparkContext(sparkConf) val tablename = "student" sc.hadoopConfiguration.set(TableOutputFormat.OUTPUT_TABLE, tablename) val job = new Job(sc.hadoopConfiguration) job.setOutputKeyClass(classOf[ImmutableBytesWritable]) job.setOutputValueClass(classOf[Result]) job.setOutputFormatClass(classOf[TableOutputFormat[ImmutableBytesWritable]]) val indataRDD = sc.makeRDD(Array("3,Rongcheng,M,26", "4,Guanhua,M,27")) //構建兩行記錄 val rdd = indataRDD.map(_.split(',')).map { arr => { val put = new Put(Bytes.toBytes(arr(0))) //行健的值 put.addColumn(Bytes.toBytes("info"), Bytes.toBytes("name"), Bytes.toBytes(arr(1))) //info:name列的值 put.addColumn(Bytes.toBytes("info"), Bytes.toBytes("gender"), Bytes.toBytes(arr(2))) //info:gender列的值 put.addColumn(Bytes.toBytes("info"), Bytes.toBytes("age"), Bytes.toBytes(arr(3).toInt)) //info:age列的值 (new ImmutableBytesWritable, put) } } rdd.saveAsNewAPIHadoopDataset(job.getConfiguration()) } }
- sbt打包jar,釋出到測試環境執行spark
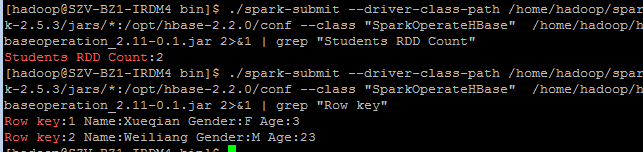
- spark讀取hbase
./spark-submit --driver-class-path /home/hadoop/spark-2.5.3/jars/*:/opt/hbase-2.2.0/conf --class "SparkWriteHBase" /home/hadoop/hbaseoperation_2.11-0.1.jar
- spark寫入hbase
./spark-submit --driver-class-path /home/hadoop/spark-2.5.3/jars/*:/opt/hbase-2.2.0/conf --class "SparkWriteHBase" /home/hadoop/hbaseoperation_2.11-0.1.jar

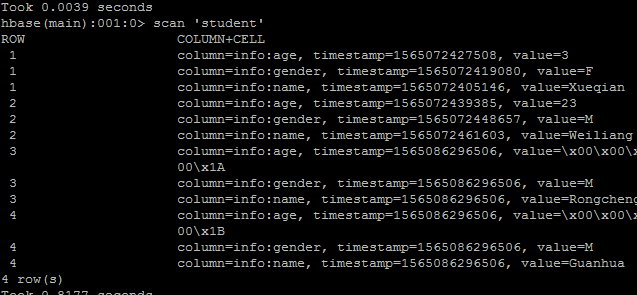
結果顯示:
填坑
步驟1中 把hbase相關jar複製到spark的jars下的hbase資料夾內,執行spark報錯:
Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/hadoop/hbase/HBaseConfiguration
解決辦法:把步驟1中hbase的依賴複製到spark/jars目錄