
XXL Job原始碼分析
一.XXL JOB專案原始碼整體概括
1. 原始碼整體概括說明
這個專案是作為工程開發的同學們很值得學習的一個開源專案。程式碼整體風格比較好,模組化清晰。程式碼邏輯遵行Web的MVC架構,採用Spring boot + Mybatis的框架組合來組織程式碼。 程式碼總體分為三部分: 一.xxl-job-core: 這是公共服務模組,比如提供RPC遠端排程,執行緒管理等。從業務角度去分析這個模組是沒有意義的,很容易一腦霧水,因為這個模組不是獨立的服務,它只是為xxl-job-admin和xxl-job-executors-sample提供了功能模組。
二. xxl-job-admin: web互動的後臺引擎,這裡稱為排程中心。主要負責下面幾件事情:
- 負責web端互動:作為Web後臺引擎,提供了登入許可權管理,任務增刪改查操作,執行器組管理,GLUE任務線上編輯,日誌管理等
- 與MySQL資料庫互動,把資料持久化。
- 提供RPC介面,供執行器註冊,維持和執行器的心跳。
- 與quartz互動,把任務排程的事情交給quartz去做。
三. xxl-job-executors-sample。主要做以下兩件事情:
- 執行器初始化,並且主動註冊到排程中心那裡去。
- bean的方式注入我們線下編輯好的任務。
整體架構圖如下。後續章節會對細節進行展開闡述。

2.分析該專案原始碼時一些必須的知識
磨刀不誤砍材工,在正式深入分析這個專案之前,有些知識有必要預知下: 1.quartz的用法。 2.freemarker渲染前端介面的原理和用法。 3.java基本功,以及spring boot和mybatis相關框架知識。
2.1 quartz簡單介紹
xxl job的任務排程是依賴於quartz的。quartz可用於建立執行數十,數百甚至數十萬個作業的簡單或複雜的計劃; 任務定義為標準Java元件的任務,可以執行任何可以對其進行程式設計的任何內容。我們先從quartz官網的一個例子說起:
// 第一步,定義任務類。這個class必須要實現Job介面的execute方法。
public class HelloJob implements Job {
private static Logger _log = LoggerFactory.getLogger(HelloJob.class);
public 從上面的demo可以看出quartz的關鍵API:
- Scheduler - 進行作業排程的主要介面.
- Job - 作業介面,編寫自己的作業需要實現,如例子中的HelloJob
- JobDetail - 作業的詳細資訊,除了包含作業本身,還包含一些額外的資料。
- Trigger - 作業計劃的元件-作業何時執行,執行次數,頻率等。
- JobBuilder - 建造者模式建立 JobDetail例項.
- TriggerBuilder - 建造者模式建立 Trigger 例項.
- QuartzSchedulerThread 繼承Thread 主要的執行任務執行緒
從上面的幾個介面,可以看到quartz設計非常精妙,將作業和觸發器分開設計,同時排程器完成對作業的排程。 整個執行過程可以概括如下:
- 從StdSchedulerFactory獲取scheduler
- 建立JobDetail
- 建立Trigger
- scheduler.scheduleJob()將任務和觸發器繫結起來
所以quartz的核心元素可以表示為如下圖:
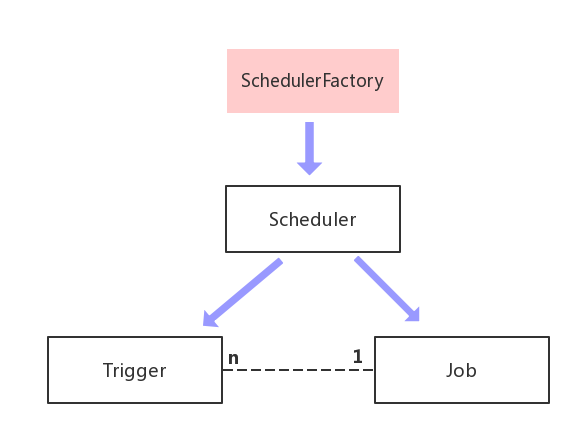 圖2. quartz內部核心模組關係圖
圖2. quartz內部核心模組關係圖
quartz不是以定時器的方式去執行任務的,而是通過執行緒池去完成。配置檔案quartz.properties配置了執行緒池相關的引數。在quartz中,有兩類執行緒,Scheduler排程執行緒和任務執行執行緒,其中任務執行執行緒通常使用一個執行緒池維護一組執行緒。
2.2 freemarker前端渲染模板簡介
freemarker是一個java模板引擎。是一種基於模板和要改變的資料,並用來生成輸出文字(HTML網頁,電子郵件,配置檔案,原始碼等)的通用工具。類似於JSP,volecity。這裡不細說,有這個概念就好了。
2.3 java基本功修煉
xxl job的原始碼閱讀,需要一定的java工程功底。特別要熟悉下spring boot, mybatis框架。
二. xxl-job-admin的原始碼分析
xxl-job-admin是專案的核心,稱為排程中心,也是一個典型的web專案架構。通常對於一個web程式來說,我們分析時,主要是關注兩件事情:第一,這個程式在初始化(也就是程式啟動的時候)幹了哪些事情;第二,程式的Restful介面分析,這個是Web專案最大的主線。下面的分析我們也主要是從這兩點分別展開。
1. 排程中心初始化
JVM執行一個java程式時,會經歷編譯,載入,分配記憶體和執行等過程。spring boot採用了的bean方式初始化了一些物件,這些物件包括了資料庫連線池,前端介面渲染的引擎,配置檔案讀取,quartz排程引擎,攔截器等等,這些物件一旦初始化,就會從JVM的方法區裡實例化到堆記憶體裡面去,可以供程序後續的呼叫。這裡有個和我們業務直接相關的bean初始化,程式碼如下:
<!--classpath:applicationcontext-xxl-job-admin-xml-->
<bean id="xxlJobDynamicScheduler" class="com.xxl.job.admin.core.schedule.XxlJobDynamicScheduler" init-method="init" destory-method="destory">
<property name="scheduler" ref="quartzScheduler" />
<property name="accessToken" value="${xxl.job.accessToken" />
</bean>
這個XxlJobDynamicScheduler類在初始化化時,執行了init方法。我們來重點分析下這個init方法幹了哪些事情。
public void init() throws Exception {
// 1. 排程中心註冊守護執行緒,就是一直守護著執行器的註冊,維持著和執行器之間的心跳
JobRegistryMonitor.getInstance.start();
// 2. 任務失敗處理的守護執行緒
JobFailMonitorHelper.getInstance().start();
// 3. 初始化本地排程中心服務
NetComServerFactory.putService(AdminBiz.class, XxlJobDynamicScheduler.adminBiz);
NetComServerFactory.setAcessToken(accessToken);
// 4.國際化
initI18n();
Assert.notNull(scheduler, "quartz scheduler is null");
logger.info(">>>>>>> init xxl-job admin success");
}
- JobRegistryMonitor.getInstance.start()是開啟了一個單獨的執行緒,這個執行緒每30s去輪訓一下資料庫。如果某個執行器的註冊訊號(也叫作心跳)在近90s內沒有寫入資料庫表XXL_JOB_QRTZ_TRIGGER_REGISTRY,那麼排程中心就認為這個執行器已經死掉。然後會更新資料庫表XXL_JOB_QRTZ_TRIGGER_GROUP表,使每個執行器組,只保留活著的執行器。這裡的執行器組是根據排程中心來區分的。每個執行器組(這個有可能是一臺,也有可能是一個叢集)都有一個唯一的appName,執行器向排程中心註冊時就是通過這個appName標誌來區分是屬於哪個執行器組的。
- JobFailMonitorHelper.getInstance().start()是一個失敗任務處理的守護執行緒。這個執行緒是每隔10秒執行一下邏輯。資料庫表XXL_JOB_QRTZ_TRIGGER_LOG裡存著每個任務每次的執行記錄,這裡面記錄著任務的執行狀態。如果某條日誌記錄的處理狀態碼為500,那麼這條執行記錄是以失敗告終的。那麼失敗守護執行緒就會根據這個任務的executorFailRetryCount(失敗重試次數)是否大於零(這個引數是前端新增任務時配置的),如果大於零,會去嘗試再執行下這個任務。並且相應地在資料庫裡把該條執行日誌裡的executorFailRetryCount值減1。最後發出失敗告警。
- 初始化本地的排程中心的服務Map,以及accessToken值。排程中心例項用HaspMap物件存了起來。
- 國際化。支援中文和英文展示。
所以總的來說,這裡主要是初始化了兩個守護執行緒。一個是維持和執行器之間心跳的執行緒,一個是任務執行失敗重試的執行緒。
2. Web MVC邏輯分析
Controller層是我們理解後臺邏輯的入口,com.xxl.job.admin.controller包裡面中共包含了六大模組:許可權登入模組,排程中心和執行器通訊的RPC模組,GLUE任務編輯模組,執行器管理模組,任務操作模組和任務日誌管理模組。從使用者正常的互動角度分析,這些模組是有先後順序的。使用者首先是通過賬戶密碼登入系統,然後檢視排程中心裡有沒有已經自動註冊上的執行器,如果沒有,那麼需要手動新增執行器。後續就可以建立任務了。任務建立時,GLUE型別的任務可以線上編輯任務邏輯程式碼的。任務確認建立好了之後,可以手動即席執行,還可以配置cron表示式進行週期排程執行。最後通過日誌介面,檢視每個任務的執行邏輯。所以本節也會根據這個先後順序來介紹每個模組的具體邏輯。
2.1. 許可權登入模組
程式的配置檔案裡配置了初始化的username為admin,password為123456。spring boot的xml配置檔案裡配置了兩個攔截器。具體如下:
<mvc:interceptors>
<mvc:interceptor>
<mvc:mapping path="/**" />
<bean class="com.xxl.job.admin.controller.interceptor.PermissionInterceptor" />
</mvc:interceptor>
<mvc:interceptor>
<mvc:mapping path="/**" />
<bean class="com.xxl.job.admin.controller.interceptor.CookieInteceptor" />
</mvc:interceptor>
</mvc:interceptors>
所以我們有必要先看這兩個攔截器做了哪些事情。因為程式碼較多,所以這裡只展現核心的邏輯出來。
public class PermissionInterceptor extends HandlerInterceptorAdapter{
// 1. 靜態程式碼塊
static {
String username = XxlJobAdminConfig.getAdminConfig().getLoginUsername();
String password = XxlJobAdminConfig.getAdminConfig().getLoginPassword();
String tokenTmp = DigestUtils.md5Hex(username + "_" + password);
tokenTmp = new BigInteger(1, tokenTmp.getBytes()).toString(16);
}
// 2. 攔截方法,登入方法
public static boolean login(HttpServletResponse response, String username, String password, boolean ifRemember){
// 程式碼略
// 整體邏輯為:
// 1. 驗證登入時的使用者名稱和密碼生成的MD5加密生成的token是否與記憶體中tokenTmp是否相等,如果不等,就直接返回false。
// 2. 如果相等,把token值以Cookie的方式存入response,當前端瀏覽器收到這個響應時,會把cookie值自動存入瀏覽器會話窗口裡。
}
// 3.登出,登出賬戶的方法
public static void logout(HttpServletRequest request, HttpServletResponse response){
// 將token值從response裡刪除
}
// 4. 判斷客戶端是否處於登入狀態
public static boolean ifLogin(HttpServletRequest request) {
// 判斷依據是:
// 判斷請求體request的Cookie裡面token值是否和記憶體裡的tokenTmp相等。如果瀏覽器存著cookie值,那麼每次請求,瀏覽器都會自動把cookie帶上的。
// 如果相等,那麼處於登入狀態;如果不等,那麼處於非登入狀態。
}
// 5. 服務端收到客戶端請求時的攔截方法,預設任何請求都會先經過這層攔截器
@Override
public boolean preHandler(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception{
// 邏輯說明
// 通過ifLogin如果客戶端不是處於登入狀態,那麼需要重定向到登入頁。
}
}
public class CookieInterceptor extends HandlerInterceptorAdapter {
// 這是服務端響應客戶端請求時執行的攔截,任何請求的響應之後,都會執行這個攔截器。
@Override
public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, ModelAndView modelAndView) throws Exception {
// 執行的整體邏輯,把cookies全部以cookieMap物件存入modelAndView中。
}
}
以上是兩個攔截器的總體邏輯,這裡讀者如果有疑問,最好是先去熟悉下攔截器的原理。 下面正式開始Controller的邏輯分析。
2.1.1. 訪問首頁路由的方法執行體
訪問首頁程式碼的執行體:
@RequestMapping("/")
public String index(Model model){
// 1. 請求model資料
Map<String,Object> dashboardMap = xxlJobService.dashboardInfo();
model.addAllAttributes(dashboard);
// 2. 返回index.ftl模板
return "index";
}
因為預設所以的請求都會先經過攔截器來判斷瀏覽器會話層是否處於登入狀態,所以這個路由的執行體在執行這部分邏輯之前,是要先經過攔截器的preHandler方法的。如果preHandler返回true,才再執行index函式執行體裡面的邏輯。這也是spring框架比較隱晦的地方。後續的路由分析將不再強調這個,因為是一樣的思想。 dashboardMap是Model的資料。這段邏輯是去統計資料庫裡的執行報表資訊,包括任務數量,排程次數,執行器數量等三部分。然後將這些資料存入dashboardMap。返回前端的介面模板是index.ftl。freemarker模板引擎會結合model資料和views模板,最後把介面完整地呈現給前端瀏覽器。 首頁的渲染,出了上述邏輯,還有日期分佈折線圖和成功比例餅型圖的繪製。這兩個圖的繪製所需資料是請求的另一個介面。這個介面的請求,是前端的ajax請求發出的。路由邏輯如下:
@RequestMapping("/chartInfo)
@ResponseBody
public ReturnT<Map<String,Object>> chartInfo(Date startDate, Date endDate){
ReturnT<Map<String, Object>> chartInfo = xxlJobService.chartInfo(startDate, endDate);
return chartInfo;
}
這段執行體的主要邏輯是根據開始時間startDate和結束時間endDate去資料庫裡面撈出這段時間內的統計資訊。預設是請求近一個月的資料資訊。這裡的統計資料是從XXL_JOB_QRTZ_TRIGGER_LOG表裡面獲得的。最後返回給前端的是json資料格式chartInfo。這裡有必要強調下方法體的註解@ResponseBody的作用,如果有這個註解,那麼返回給前端的必須是json資料格式。
2.1.2. 訪問登入頁的方法執行體
使用者登入頁的controller層程式碼如下:
@RequestMapping("/toLogin")
@PermessionLimit(limit=false)
public String toLogin(Model model, HttpServletRequest request){
if(PermissionInteceptor.ifLogin(request)){
return "redirect:/"
}
return "login";
}
這段程式碼是先判斷客戶端是否為登入狀態,如果是,那麼直接重定向首頁,無需使用者再進行登入。如果不是處於登入狀態,那麼久給前端返回login.ftl模板。也就是進入了登入頁。
2.1.3. 登入事件的方法執行體
登入事件執行體邏輯如下:
@RequestMapping(value="login", method=RequestMethod.POST)
@ResponseBody
@PermessionLimit(limit=false)
public ReturnT<string> loginDo(HttpServletRequest request, HttpServletResponse response, String userName, String password, String ifRemember){
// 1. 先驗證是否處於登入狀態,如果是,直接返回success
// 2. 校驗使用者名稱和密碼的合法性,不能為空值
// 3. 判斷是否要記住密碼
// 4. 執行登入邏輯(這個邏輯很簡單,就是判斷使用者輸入的使用者名稱和密碼的md5加密值和後臺的tmpToken是否相等。)如果相等,那麼就把token值存入響應體,最後會把cookie存到瀏覽器。
// 5. 判斷是否登入成功
}
因為這部分的程式碼相對而言有點長,所以程式碼沒有羅列了。只寫出了程式碼的執行邏輯。這樣讀者對著程式碼去讀,就會覺得思路很清晰的。注意這個登入請求時post請求,註解裡有標註。
2.1.4. 登出事件的方法執行體
程式碼如下:
@RequestMapping(value="logout", method=RequestMethod.POST)
@ResponseBody
@PermssionLimit(limit=false)
public ReturnT<String> logout(HttpServletRequest request, HttpServletResponse response){
if(PermissionInterceptor.ifLogin(request)){
PermissionInterceptor.logout(request, response);
}
return ReturnT.SUCCESS;
}
先判斷客戶端是否處於登入狀態,如果是,那麼就執行PermissionInterceptor.logout函式體。這個函式的邏輯是將response響應體的Cookie刪掉了。從而會更新客戶端(瀏覽器)裡的cookie為空值。從未就是客戶端不符合登入狀態。
2.1.5. helper介面請求的方法執行體
這個模組裡還內插了一個小的controller,如下:
@RequestMapping("/help")
public String help(){
return "help"
}
這個邏輯沒有做任何事情,就是返回靜態頁help.ftl。
到此排程中心的許可權登入邏輯分析完了,這也是一個基本的Web應用產品都要做的事情。這裡的思想甚至都可以行成模組。
2.2. 排程中心和執行器的RPC通訊模組
說起排程中心和執行器之間的RPC通訊模組,這裡有必要先提下執行器。後續章節會具體講解執行器的邏輯,但是這裡要先提下執行器和排程中心的簡單的互動邏輯。執行器自動註冊時,主要是向排程中心發起RPC請求, 所以這裡排程中心供一個rpc介面供執行器過來註冊。rpc框架需要解決的一個問題是: 像呼叫本地介面一樣呼叫遠端的介面。於是如何組裝資料報文,經過網路傳輸傳送至服務提供方,遮蔽遠端介面呼叫的細節,便是動態代理需要做的工作。
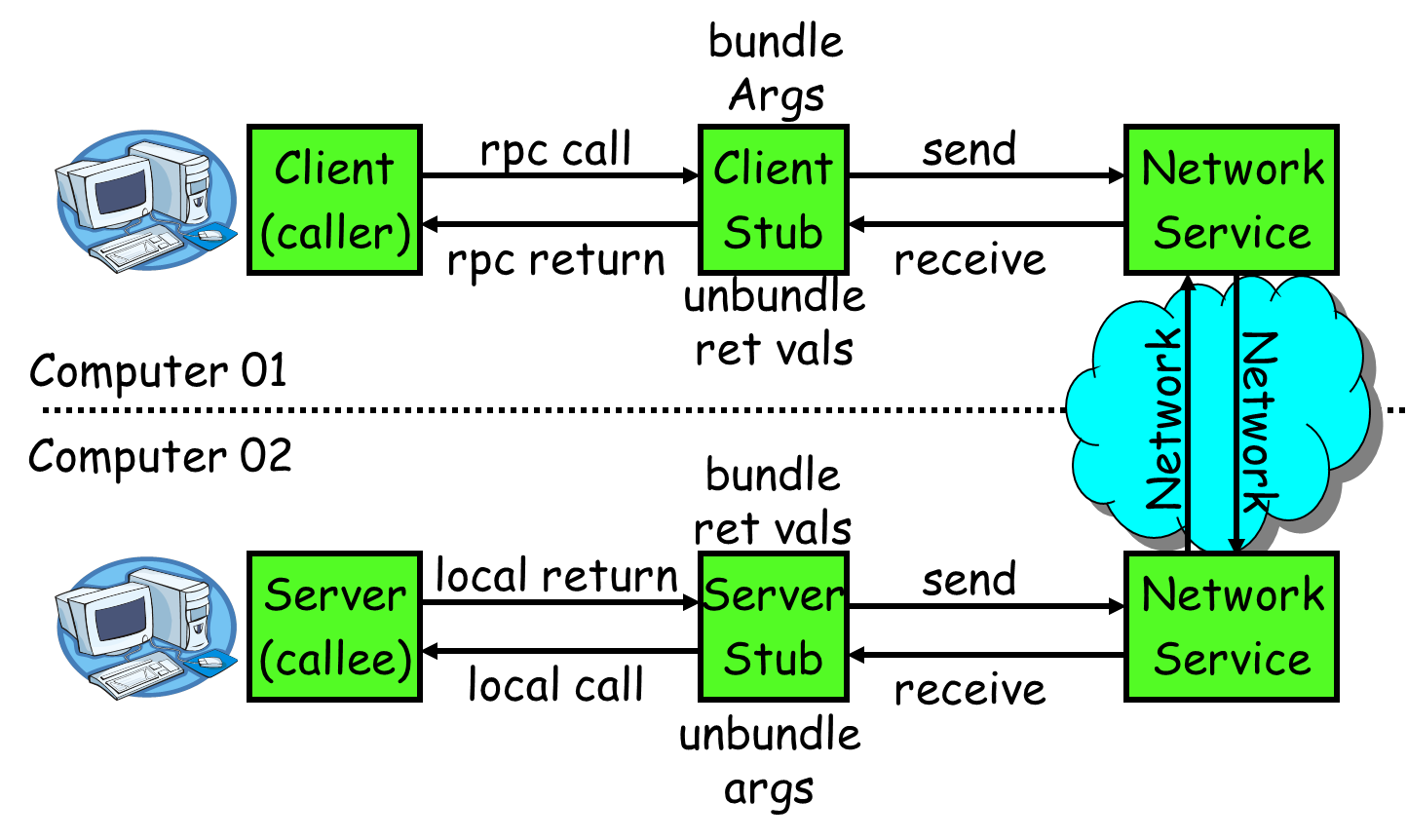
如上圖所示,假設Computer1在呼叫sayHi()方法,對於Computer1而言呼叫sayHi()方法就像呼叫本地方法一樣,呼叫 –>返回。但從後續呼叫可以看出Computer1呼叫的是Computer2中的sayHi()方法,RPC遮蔽了底層的實現細節,讓呼叫者無需關注網路通訊,資料傳輸等細節。 RPC的整體執行過程可以描述為: 1)服務消費方(client)呼叫以本地呼叫方式呼叫服務; 2)client stub接收到呼叫後負責將方法、引數等組裝成能夠進行網路傳輸的訊息體; 3)client stub找到服務地址,並將訊息傳送到服務端; 4)server stub收到訊息後進行解碼; 5)server stub根據解碼結果呼叫本地的服務; 6)本地服務執行並將結果返回給server stub; 7)server stub將返回結果打包成訊息併發送至消費方; 8)client stub接收到訊息,並進行解碼; 9)服務消費方得到最終結果 排程中心提供這個RPC介面的程式碼邏輯為:
private RpcResponse doInvoke(HttpServletRequest request) {
try {
// 反序列化請求體
byte[] requestBytes = HttpClientUtil.readBytes(request);
if (requestBytes == null || requestBytes.length==0) {
RpcResponse rpcResponse = new RpcResponse();
rpcResponse.setError("RpcRequest byte[] is null");
return rpcResponse;
}
RpcRequest rpcRequest = (RpcRequest) HessianSerializer.deserialize(requestBytes, RpcRequest.class);
// 觸發
RpcResponse rpcResponse = NetComServerFactory.invokeService(rpcRequest, null);
return rpcResponse;
} catch (Exception e) {
logger.error(e.getMessage(), e);
RpcResponse rpcResponse = new RpcResponse();
rpcResponse.setError("Server-error:" + e.getMessage());
return rpcResponse;
}
}
@RequestMapping(AdminBiz.MAPPING)
@PermessionLimit(limit=false)
public void api(HttpServletRequest request, HttpServletResponse response) throws IOException {
//觸發,動態代理執行邏輯
RpcResponse rpcResponse = doInvoke(requst);
//序列化
byte[] responseBytes = HessianSerializer.serialize(rpcResponse);
response.setContentType("text/html;charset=utf-8");
response.setStatus(HttpServletResponse.SC_OK);
OutputStream out = response.getOutputStream();
out.write(responseBytes);
out.flush();
}
這段程式碼主要執行邏輯在這一行:RpcResponse rpcResponse = doInvoke(request)。執行邏輯總結為如下流程:
- 反序列化請求體資料。
- 反射出伺服器裡的執行類方法和引數,並且執行服務端(排程中心)的方法。這裡要強調下在執行主體方法之前,程式先判斷了遠端rpc請求者的系統時間和當前排程中心的系統時間的差值,如果時間差超過3分鐘,那麼就響應錯誤,這個時候就需要先做時間同步操作。
- 對執行方法的結果進行序列化。返回給客戶端(執行器)。 這是服務端提供的rpc服務介面,然後具體客戶端那邊怎麼呼叫,後續在分析執行器模組時再重點分析下。
2.3. GLUE任務編輯模組
線上編輯任務程式碼主要針對GLUE型別的任務。如果是bean型別的任務是不提供編輯修改任務程式碼的。該模組主要提供的功能有回溯GLUE類任務的歷史版本,以及更新任務的指令碼內容等操作。
2.3.1 請求載入任務的GLUE 程式碼
該介面的controller程式碼如下:
@RequestMapping
public String index(Model model, int jobId){
// 1. 通過jobId獲取任務資訊。
XxlJobInfo = xxlJobInfoDao.loadById(jobId);
// 2. 通過jobId獲取GLUE歷史版本資訊。
List<XxlJobLogGlue> jobLogGlues = xxlJobLogGlueDao.findByJobId(jobId);
// 3. 驗證任務是否存在
if(jobInfo == null){
throw new RuntimeException(I18nUtil.getString("jobinfo_glue_jobid_invalid");
}
// 4. 驗證任務是否是GlueType,如果不是丟擲異常。
if(GlueTypeEnum.BEAN == GlueTypeEnum.match(jobInfo.getGlueType())){
throw new RuntimeException(I18nUtil.getString("jobinfo_glue_gluetype_unvalid"));
}
// 5. 將資料和模板返回
model.addAttribute("GlueTypeEnum", GlueTypeEnum.values());
model.addAttribute("jobInfo",jobInfo);
model.addAttribute("jobLogGlues",jobLogGlues);
return "jobcode/jobcode.index";
}
這個邏輯在程式碼註釋裡寫比較清晰了,這裡一次性返回了該任務的歷史所有GLUE版本,通過前端去操作可以編輯任務版本的指令碼內容 。
2.3.2 儲存編輯的GLUE內容
任務線上編輯好之