
hadoop version3 第二章 關於MapReduce
阿新 • • 發佈:2018-12-19
java mapreduce
尋找每一年全球的最高氣溫
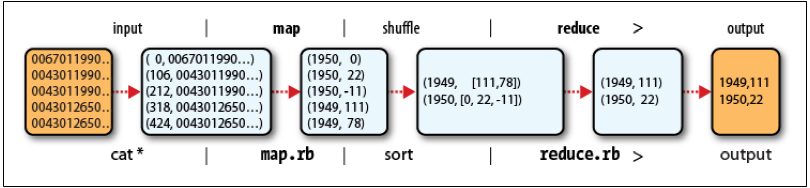
輸入值的key是檔案中的行偏移量,map函式不需要該資訊,所以將其忽略。value是一行文字資訊
- map的功能是從中找出每年的溫度,統計到一個對應的陣列中。
- reduce的功能是遍歷每年的列表,並從其中找到最高溫度。
Mapper類
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache. - Mapper類是一個泛型型別,形參有四個,分別指定map函式的輸入鍵(行偏移量,長整數),輸入值(一行文字),輸出鍵(年份),輸出值(氣溫,整數)
- map()方法:輸入一個鍵和一個值
- Context例項用於輸出內容的寫入,將年份資料按照Text物件進行讀寫,氣溫物件封裝在IntWritable型別中
Reducer類
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class MaxTemperatureReducer
extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
public void reduce(Text key, Iterable<IntWritable> values,
Context context)
throws IOException, InterruptedException {
int maxValue = Integer.MIN_VALUE;
for (IntWritable value : values) {
maxValue = Math.max(maxValue, value.get());
}
context.write(key, new IntWritable(maxValue));
}
}
- Reducer類也有四個函式指定輸入輸出型別
- reduce函式的輸入型別必須匹配map函式的輸出型別
第三部分程式碼負責執行MapReduce作業
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class MaxTemperature {
public static void main(String[] args) throws Exception {
if (args.length != 2) {
System.err.println("Usage: MaxTemperature <input path> <output path>");
System.exit(-1);
}
Job job = new Job();
job.setJarByClass(MaxTemperature.class);
job.setJobName("Max temperature");
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//指定map類和reduce類
job.setMapperClass(MaxTemperatureMapper.class);
job.setReducerClass(MaxTemperatureReducer.class);
//設定map函式和reduce函式的輸出型別,這兩個函式的輸出型別一般相同。如果不同就分別用setMapOutputKeyClass(),setMapOutputValueClass來設定map函式的輸出型別
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//輸入的型別通過InputFormat類控制,預設為文字輸入格式
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
- Job物件:用來指定作業執行規範。Job.setJarByClass(**.class),向叢集中傳遞一個類名,hadoop利用這個類來查詢包含它的jar檔案,從而把jar檔案上傳到叢集時,不用指定jar檔案的名稱
- FileInputFormat中的靜態方法addInputPath()定義入資料路徑,這個路徑可以是單個檔案、一個目錄(目錄下的所有檔案當做輸入)或者符合特定檔案模式的一系列檔案
- FileOutputFormat 中的靜態方法setOutputPath()用來指定輸出檔案的路徑(只能有一個路徑),在執行作業前該路徑應該是不存在的,否則會報錯。
測試執行
windows下測試未完成
問題:重新啟動後,hadoop命令無法識別,只能進入hadoop-2.9.1/bin中啟動;並且不知道如何恰當的編譯java檔案為jar包。。