
分散式儲存HBASE原理學習
阿新 • • 發佈:2018-12-19
HBase定義 HBase 是一個高可靠、高效能、面向列、可伸縮的分散式儲存系統,利用Hbase技術可在廉價PC Server上搭建 大規模結構化儲存叢集。 HBase 是Google Bigtable 的開源實現,與Google Bigtable 利用GFS作為其檔案儲存系統類似, HBase 利用Hadoop HDFS 作為其檔案儲存系統;Google 執行MapReduce 來處理Bigtable中的海量資料, HBase 同樣利用Hadoop MapReduce來處理HBase中的海量資料;Google Bigtable 利用Chubby作為協同服務, HBase 利用Zookeeper作為對應。 HBase簡介

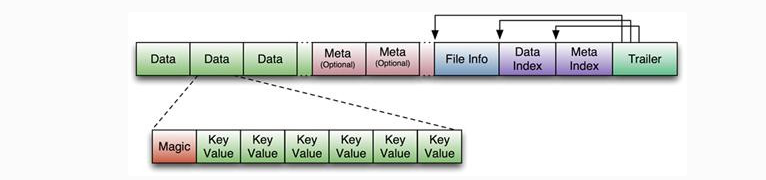 Data Block段用來儲存表中的資料,這部分可以被壓縮。 Meta Block段(可選的)用來儲存使用者自定義的kv段,可以被壓縮。 FileInfo段用來儲存HFile的元資訊,不能被壓縮,使用者也可以在這一部分新增自己的元資訊。 Data Block Index段(可選的)用來儲存Meta Blcok的索引。 Trailer這一段是定長的。儲存了每一段的偏移量,讀取一個HFile時,會首先讀取Trailer,Trailer儲存了每個段的起始位置(段的Magic Number用來做安全check),然後,DataBlock Index會被讀取到記憶體中,這樣,當檢索某個key時,不需要掃描整個HFile,而只需從記憶體中找到key所在的block,通過一次磁碟io將整個 block讀取到記憶體中,再找到需要的key。DataBlock Index採用LRU機制淘汰。 HFile的Data Block,Meta Block通常採用壓縮方式儲存,壓縮之後可以大大減少網路IO和磁碟IO,隨之而來的開銷當然是需要花費cpu進行壓縮和解壓縮。目標HFile的壓縮支援兩種方式:gzip、lzo。
HLog
其實HLog檔案就是一個普通的Hadoop Sequence File, Sequence File的value是key時HLogKey物件,其中記錄了寫入資料的歸屬資訊,除了table和region名字外,還同時包括sequence number和timestamp,timestamp是寫入時間,sequence number的起始值為0,或者是最近一次存入檔案系統中的sequence number。 Sequence File的value是HBase的KeyValue物件,即對應HFile中的KeyValue。
HLog(WAL log):WAL意為write ahead log,用來做災難恢復使用,HLog記錄資料的所有變更,一旦region server 宕機,就可以從log中進行恢復。
Data Block段用來儲存表中的資料,這部分可以被壓縮。 Meta Block段(可選的)用來儲存使用者自定義的kv段,可以被壓縮。 FileInfo段用來儲存HFile的元資訊,不能被壓縮,使用者也可以在這一部分新增自己的元資訊。 Data Block Index段(可選的)用來儲存Meta Blcok的索引。 Trailer這一段是定長的。儲存了每一段的偏移量,讀取一個HFile時,會首先讀取Trailer,Trailer儲存了每個段的起始位置(段的Magic Number用來做安全check),然後,DataBlock Index會被讀取到記憶體中,這樣,當檢索某個key時,不需要掃描整個HFile,而只需從記憶體中找到key所在的block,通過一次磁碟io將整個 block讀取到記憶體中,再找到需要的key。DataBlock Index採用LRU機制淘汰。 HFile的Data Block,Meta Block通常採用壓縮方式儲存,壓縮之後可以大大減少網路IO和磁碟IO,隨之而來的開銷當然是需要花費cpu進行壓縮和解壓縮。目標HFile的壓縮支援兩種方式:gzip、lzo。
HLog
其實HLog檔案就是一個普通的Hadoop Sequence File, Sequence File的value是key時HLogKey物件,其中記錄了寫入資料的歸屬資訊,除了table和region名字外,還同時包括sequence number和timestamp,timestamp是寫入時間,sequence number的起始值為0,或者是最近一次存入檔案系統中的sequence number。 Sequence File的value是HBase的KeyValue物件,即對應HFile中的KeyValue。
HLog(WAL log):WAL意為write ahead log,用來做災難恢復使用,HLog記錄資料的所有變更,一旦region server 宕機,就可以從log中進行恢復。