
Deeplearning4j 實戰 (12):Mnist替代資料集Fashion Mnist在CNN上的實驗及結果
Mnist資料集的分類問題一直被認為是深度學習的Hello World。利用2層卷積網路,經過若干輪的訓練後,在相應測試集上的準確率可以達到95%以上。經過調參後,甚至可以達到99%以上。其實,即使不用用卷積層提取特徵,而是用傳統的全連線網路也同樣可以達到非常高的準確率。在Mnist資料集的官網上(http://yann.lecun.com/exdb/mnist/),除了基於神經網路的分類器,利用傳統的分類方法,如:KNN,SVM,也都可以獲得非常好的結果。下面就是部分模型分類效果的截圖:

從以上結果分析可以發現,無論是淺層模型還是深度學習,在Mnist上的分類問題上都可以達到很高的精度,因此從某種角度也可以說,Mnist資料集複雜度不夠,或者說Mnist分類問題並不是一個具有代表性的機器視覺問題。就這個問題,《Deep Learning》一書的作者Ian Goodfellow和著名開源專案Keras的作者Francois Chollet都有自己的評述,詳情可轉到下面兩個連結:
1.Ian Goodfellow Commnet On Mnist DataSet
雖然Mnist可能並不是最合適入門深度學習的資料集,但是鑑於長期以來開發人員的使用習慣,想要找到完全替代Mnist的開源資料集確實有點困難,但這個難題最近有了一個比較好的解答,就是類似Mnist的一個服裝影象資料集--Fashion Mnist。
和Mnist資料集一樣,Fashion Mnist也是28*28的灰度圖。內容涵蓋了鞋、包、衣服、褲子。它的檔名稱和資料格式和Mnist一模一樣。換句話說,你完全不需要改動你之前在Mnist上的建模邏輯,只需要把相應的檔案替換掉,就可以對Fashion Mnist進行訓練和評估。不過唯一不同的是,Fashion Mnist的分類準確率遠沒有Mnist那麼高。目前在Fashion Mnist的github主頁上,最好的結果也僅僅是在95%左右。當然,如果你自己的網路有了好的結果,可以在主頁上提個issue,也作為是對這個資料集的一個貢獻。
下面主要介紹3個方面的內容:
1.Fashion Mnist基於CNN的建模分類與評估
2.與Mnist的比較
3.簡單的服裝分類應用
首先介紹第一部分的主要內容。對於Fashion Mnist資料集採用卷積神經網路進行分類建模,具體的網路結構是:2Conv+2FC。建模工具是Deeplearning4j。詳細的超引數配置見如下程式碼片段:
簡單解釋下部分超引數:public static MultiLayerNetwork getModel(){ MultiLayerConfiguration.Builder builder = new NeuralNetConfiguration.Builder() .seed(12345) .iterations(1) //.regularization(true).l2(0.005) .learningRate(0.01) .learningRateScoreBasedDecayRate(0.5) .weightInit(WeightInit.XAVIER) .optimizationAlgo(OptimizationAlgorithm.STOCHASTIC_GRADIENT_DESCENT) .updater(Updater.ADAM) .list() .layer(0, new ConvolutionLayer.Builder(5, 5) .nIn(1) .stride(1, 1) .nOut(32) .activation(Activation.LEAKYRELU) .build()) .layer(1, new SubsamplingLayer.Builder(SubsamplingLayer.PoolingType.MAX) .kernelSize(2,2) .stride(2,2) .build()) .layer(2, new ConvolutionLayer.Builder(5, 5) .stride(1, 1) .nOut(64) .activation(Activation.LEAKYRELU) .build()) .layer(3, new SubsamplingLayer.Builder(SubsamplingLayer.PoolingType.MAX) .kernelSize(2,2) .stride(2,2) .build()) .layer(4, new DenseLayer.Builder().activation(Activation.LEAKYRELU) .nOut(500).build()) .layer(5, new OutputLayer.Builder(LossFunctions.LossFunction.NEGATIVELOGLIKELIHOOD) .nOut(10) .activation(Activation.SOFTMAX) .build()) .backprop(true).pretrain(false) .setInputType(InputType.convolutionalFlat(28, 28, 1)); MultiLayerConfiguration conf = builder.build(); MultiLayerNetwork model = new MultiLayerNetwork(conf); return model; }
激勵函式部分主要用的是LeakeyRelu。
學習率用了Decay的策略。Decay的幅度是50%。
正則化項是可選的(經測試,正則化項在如上配置中,影響不大)
網路結構:2 Conv-with-MaxPooling + 2FC。卷積層中每層的featureMap的數量如上述所示。
除了建模的部分,資料的ETL部分同樣很重要。在具體實現中,我直接利用Deeplearning4j自帶的一個解析Mnist資料集的元件:MnistManager。它的主要功能就是讀取解壓後的二進位制Mnist資料集以及相應的分類標籤。由於Fashion Mnist和原始Mnist資料集在資料格式上完全相同,所以可以直接使用Mnist的元件進行解析。在讀取的時候,我們可以根據要求設定batchSize,一個batch的資料和標籤會封裝在一個DataSet物件中。由這些DataSet構成的迭代器即可作為最終訓練或者測試的資料。下面具體看下以上邏輯的實現:
public static DataSet fetch(int batchSize , boolean binarize, MnistManager man, boolean save, boolean train) {
float[][] featureData = new float[batchSize][0];
float[][] labelData = new float[batchSize][0];
int actualExamples = 0;
for (int i = 0; i < batchSize && cursor < totalExamples; i++, cursor++) {
byte[] img = man.readImageUnsafe(order[cursor]);
int label = man.readLabel(order[cursor]);
float[] featureVec = new float[img.length];
featureData[actualExamples] = featureVec;
labelData[actualExamples] = new float[10];
labelData[actualExamples][label] = 1.0f;
for (int j = 0; j < img.length; j++) {
float v = ((int) img[j]) & 0xFF; //byte is loaded as signed -> convert to unsigned
if (binarize) {
if (v > 30.0f)
featureVec[j] = 1.0f;
else
featureVec[j] = 0.0f;
} else {
featureVec[j] = v / 255.0f;
}
}
if( save ){
Mat mat = new Mat(28, 28, CV_8SC1, new BytePointer(img));
if( train )
JavaCVUtil.imWrite(mat, "FashionMnist/trainData/" + label + "_" + cursor + ".jpg");
else
JavaCVUtil.imWrite(mat, "FashionMnist/testData/" + label + "_" + cursor + ".jpg");
}
actualExamples++;
}
if (actualExamples < batchSize) {
featureData = Arrays.copyOfRange(featureData, 0, actualExamples);
labelData = Arrays.copyOfRange(labelData, 0, actualExamples);
}
INDArray features = Nd4j.create(featureData);
INDArray labels = Nd4j.create(labelData);
return new DataSet(features, labels);
}
public static DataSetIterator getData(String dir, boolean train , int batchSize, boolean save) throws IOException{
String featureFileDir = dir;
String labelFileDir = dir;
cursor = 0;
if( train ){
featureFileDir += "train-images-idx3-ubyte";
labelFileDir += "train-labels-idx1-ubyte";
totalExamples = 60000;
order = new int[totalExamples];
}else{
featureFileDir += "t10k-images-idx3-ubyte";
labelFileDir += "t10k-labels-idx1-ubyte";
totalExamples = 10000;
order = new int[totalExamples];
}
for (int i = 0; i < order.length; i++)order[i] = i;
MathUtils.shuffleArray(order, 123456L); //shuffle order
MnistManager man = new MnistManager(featureFileDir, labelFileDir, train);
List<DataSet> res = new LinkedList<DataSet>();
while(cursor < totalExamples){
res.add(fetch(batchSize, false, man, save, train));
}
ExistingDataSetIterator iter = new ExistingDataSetIterator(res);
return iter;
}以上兩個靜態方法就是解析資料、讀取標籤、封裝資料並生成可迭代資料集的過程。其中,getData這個方法可以根據引數的不同,生成訓練或者測試資料集。在fetch這個方法裡,可以選擇是二值化還是正常歸一化。我這裡選擇的是正常歸一化。此外,為了方便看到Fashion Mnist的影象形式,可以選擇是否以圖片的形式生成這些圖片。如果生成圖片的話,則可以看到下面這些圖:
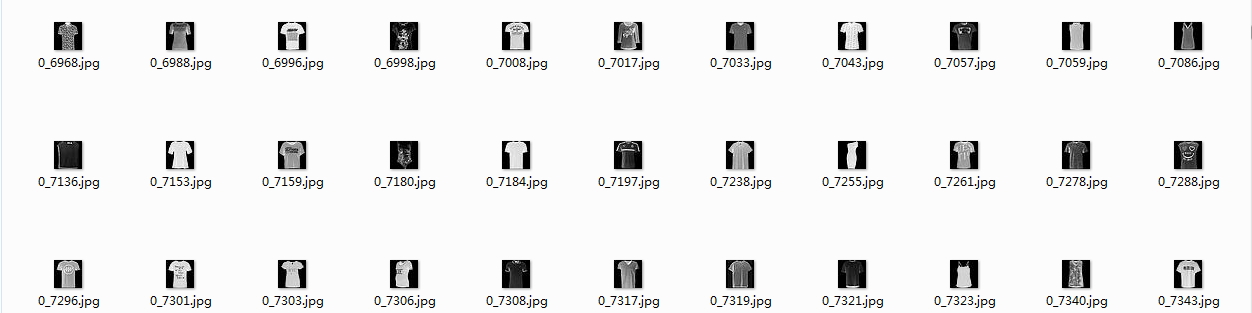

這些圖片我會上傳到CSDN上供大家下載。下載連線。
從截圖可以看出是衣服和褲子兩個品類。檔名中的第一個數字是這張圖片的分類標籤。這樣方便直接從圖片進行建模。訓練集共6W張圖片,測試集共1W張圖片。
到此的話,資料的ETL和建模的步驟都已經完成,下面就是對模型引數進行訓練。這裡我還是用的GPU來訓練模型。顯示卡是Telsa K80。單卡進行訓練。相應的CUDA版本是8.0。具體的訓練邏輯可見下面程式碼片段:
public static void main(String[] args)throws IOException {
DataTypeUtil.setDTypeForContext(DataBuffer.Type.DOUBLE);
final int numEpochs = Integer.parseInt(args[0]);
final int batchSize = Integer.parseInt(args[1]);
final String modelSavePath = args[2];
final String dataPath = args[3];
CudaEnvironment.getInstance().getConfiguration()
// 是否允許多卡
.allowMultiGPU(false)
.useDevice(7)
// 視訊記憶體大小
.setMaximumDeviceCache(11L * 1024L * 1024L * 1024L)
// 是否允許多卡直接資料的直接訪問
.allowCrossDeviceAccess(false);
DataSetIterator trainData = getData(dataPath+ "/", true, batchSize, false);
DataSetIterator testData = getData(dataPath+ "/" , false, batchSize, false);
MultiLayerNetwork model = getModel();
for( int i = 0; i < numEpochs; ++i ){
model.fit(trainData);
System.out.println("Epoch :" + i + " Finish");
System.out.println("Score: " + model.score());
Evaluation eval = model.evaluate(testData);
System.out.println(eval.stats());
System.out.println();
}
Evaluation eval = model.evaluate(testData);
System.out.println(eval.stats());
ModelSerializer.writeModel(model, modelSavePath, true);
}Epoch :0 Finish
Score: 0.4417036887606827
==========================Scores========================================
Accuracy: 0.7986
Precision: 0.8004
Recall: 0.7986
F1 Score: 0.7995
========================================================================Epoch :99 Finish
Score: 0.020469321075697797
==========================Scores========================================
Accuracy: 0.9072
Precision: 0.9088
Recall: 0.9072
F1 Score: 0.908
========================================================================到這裡,我就沒有再訓練下去了。那麼到此,第一部分的主要工作就完成了。最終經過100輪的訓練,loss值達到0.02,模型的準確率在90%。
接著介紹下第二部分,也就是和Mnist比較的內容。
Mnist的訓練過程和上面的一模一樣,唯一不同的是,資料集換成Mnist的就可以了。同樣經過100輪的訓練,我們來看下對比結果。
| Mnist DataSet | Fashion Mnist DataSet | |
| Epoch 1 | ==========================Scores==================================== Accuracy: 0.9545 Precision: 0.955 Recall: 0.954 F1 Score: 0.9545 ==================================================================== |
==========================Scores=================================== Accuracy: 0.7986 Precision: 0.8004 Recall: 0.7986 F1 Score: 0.7995 =================================================================== |
| Epoch 100 | ==========================Scores==================================== Accuracy: 0.9922 Precision: 0.9921 Recall: 0.9921 F1 Score: 0.9921 ==================================================================== |
==========================Scores===================================== Accuracy: 0.9072 Precision: 0.9088 Recall: 0.9072 F1 Score: 0.908 ===================================================================== |
Mnist資料集很容易就達到了95%的準確率,甚至最後達到了99.22%。然而Fashion Mnist最終也只有徘徊在90%上下。由此可見,Fashion Mnist資料集的分類問題更為複雜。2層卷積神經網路的效果可能也就是在90%左右了(PS:這個講述並沒有什麼理論依據,但從github主頁看到他人用Keras搭建類似結構的網路來訓練Fashion Mnist,也是在90%上下,所以作此推測,僅僅是實驗結果)。
最後一個部分介紹下基於剛才訓練的模型如何搭建一個Web應用。
服裝的分類場景在各大電商企業中有很多應用。雖然不一定需要準確區分運動鞋和休閒鞋,但是區分衣服、褲子、包、鞋還是很有必要的。這個場景在影象檢索等應用方面有著類似文字檢索中Query分析的作用,最終可以減少索引的查詢量。這裡就直接利用這樣的一個開源資料集搭建一個Web服務,用於識別圖片中物品的所屬品類。涉及到的工具有Spring、Tomcat,JSP,還有之前提到的Deeplearning4j和Nd4j。
我在本地的Eclipse中配置了Tomcat的外掛、服務的埠號、上下文的根路徑等。在POM檔案中引入了Spring和Deeplearning4j的相關依賴。最後前端頁面上做了個簡單的上傳圖片的按鈕,最後的模型分類結果會和圖片一起在頁面上做展示。由於這裡面涉及了關於J2EE開發的諸多細節,和主要介紹的內容有些偏離,所以這裡僅僅介紹主要的思路。在後面的文章中,如果有機會的話會詳細介紹Deeplearning4j訓練的模型上線部署的一些方式,當然也包括一些採坑的地方。下面就給出一些示例結果:
 |
 |
 |
 |
這裡有個地方需要注意:Fashion Mnist是28*28的灰度圖。在做這個實際應用場景的時候,我同樣對這些彩色圖片做了灰度化以及resize的處理。換句話說,和訓練資料保持一致對預測結果也同樣重要。
最後對上面的內容做下小結。Fashion Mnist作為Mnist的替代資料集,無論在資料格式還是檔名稱上都和原始的Mnist保持了高度一致,從而方便研發人員遷移之前的工作。但是,Fashion Mnist的分類比Mnist更有挑戰性,至少從目前github主頁上最優結果以及我自己的實驗來看,很難達到和Mnist一樣的準確性。原因的話,像外套、襯衫;靴子、運動鞋;難免存在外形極其相似的情況。因此,誤判的情況會比較多。不過,從另一個角度說,這也說明相比Mnist,Fashion Mnist資料集的分類問題更為複雜。此外,Fashion Mnist也可以作為諸多電商企業商品圖片分類的一個demo級別的測試資料集。通過做服裝商品分類這樣一個應用,可以對深度學習在產品級別應用的問題上有感性的認識,更重要的可能是發現深度神經網路的侷限性,並非是萬能的。這可能也是Fashion Mnist相比於原始Mnist資料集的價值所在,讓大家對深度學習有理性的認識(原始Mnist很容易達到98%-99%的準確率,容易誤導大家覺得深度學習就是這樣準確,其實資料集本身也有非常大的關係,不能僅僅依靠模型)。
--------------以下更新自2018/3/21
在Deeplearning4j的QQ群裡還有這篇文章的留言區有同學希望我補充下Web部分的程式碼,特此在這裡做些補充。
首先,Web容器我用的是Tomcat-Eclipse的外掛,在pom裡的配置如下:
<build>
<finalName>dl-webapp</finalName>
<plugins>
<plugin>
<groupId>org.apache.tomcat.maven</groupId>
<artifactId>tomcat7-maven-plugin</artifactId>
<version>2.2</version>
<configuration>
<port>8080</port>
<path>/maven-web-demo</path>
<uriEncoding>UTF-8</uriEncoding>
<finalName>maven-web-demo</finalName>
<server>tomcat7</server>
</configuration>
<executions>
<!-- 打包成功後即開始執行web容器 -->
<execution>
<phase>package</phase>
<goals>
<goal>run</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>其次,整個Web工程的編譯目錄結構如下(工程名:DL):