
Deeplearning4j 實戰(4):Deep AutoEncoder進行Mnist壓縮的Spark實現
影象壓縮,在影象的檢索、影象傳輸等領域都有著廣泛的應用。事實上,影象的壓縮,我覺得也可以算是一種影象特徵的提取方法。如果從這個角度來看的話,那麼在理論上利用這些壓縮後的資料去做影象的分類,影象的檢索也是可以的。影象壓縮的演算法有很多種,這裡面只說基於神經網路結構進行的影象壓縮。但即使把範圍限定在神經網路這個領域,其實還是有很多網路結構進行選擇。比如:
1.傳統的DNN,也就是加深全連線結構網路的隱層的數量,以還原原始影象為輸出,以均方誤差作為整個網路的優化方向。
2.DBN,基於RBM的網路棧,構成的深度置信網路,每一層RBM對資料進行壓縮,以KL散度為損失函式,最後以MSE進行優化
3.VAE,變分自編碼器,也是非常流行的一種網路結構。後續也會寫一些自己測試的效果。
這裡主要講第二種,也就是基於深度置信網路對影象進行壓縮。這種模型是一種多層RBM的結構,可以參考的論文就是G.Hinton教授的paper:《Reducing the Dimensionality of Data with Neural Network》。這裡簡單說下RBM原理。RBM,中文叫做受限玻爾茲曼機。所謂的受限,指的是同一層的節點之間不存在邊將其相連。RBM自身分成Visible和Hidden兩層。它利用輸入資料本身,首先進行資料的壓縮或擴充套件,然後再以壓縮或擴充套件的資料為輸入,以重構原始輸入為目標進行反向權重的更新。因此是一種無監督的結構。如果我沒記錯,這種結構本身也是Hinton提出來的。將RBM進行多層的堆疊,就形成深度置信網路,用於編碼或壓縮的時候,被成為Deep Autoencoder。
下面就具體來說說基於開源庫Deeplearning4j的Deep Autoencoder的實現,以及在Spark上進行訓練的過程和結果。
1.建立Maven工程,加入Deeplearning4j的相關jar包依賴,具體如下
<properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <nd4j.version>0.7.1</nd4j.version> <dl4j.version>0.7.1</dl4j.version> <datavec.version>0.7.1</datavec.version> <scala.binary.version>2.10</scala.binary.version> </properties> <dependencies> <dependency> <groupId>org.nd4j</groupId> <artifactId>nd4j-native</artifactId> <version>${nd4j.version}</version> </dependency> <dependency> <groupId>org.deeplearning4j</groupId> <artifactId>dl4j-spark_2.11</artifactId> <version>${dl4j.version}</version> </dependency> <dependency> <groupId>org.datavec</groupId> <artifactId>datavec-spark_${scala.binary.version}</artifactId> <version>${datavec.version}</version> </dependency> <dependency> <groupId>org.deeplearning4j</groupId> <artifactId>deeplearning4j-core</artifactId> <version>${dl4j.version}</version> </dependency> <dependency> <groupId>org.nd4j</groupId> <artifactId>nd4j-kryo_${scala.binary.version}</artifactId> <version>${nd4j.version}</version> </dependency> </dependencies>
2.啟動Spark任務,傳入必要的引數,從HDFS上讀取Mnist資料集(事先已經將資料以DataSet的形式儲存在HDFS上,至於如何將Mnist資料集以DataSet的形式儲存在HDFS上,之前的部落格有說明,這裡就直接使用了)
if( args.length != 6 ){
System.err.println("Input Format:<inputPath> <numEpoch> <modelSavePah> <lr> <numIter> <numBatch>");
return;
}
SparkConf conf = new SparkConf()
.set("spark.kryo.registrator", "org.nd4j.Nd4jRegistrator")
.setAppName("Deep AutoEncoder (Java)");
JavaSparkContext jsc = new JavaSparkContext(conf);
final String inputPath = args[0];
final int numRows = 28;
final int numColumns = 28;
int seed = 123;
int batchSize = Integer.parseInt(args[5]);
int iterations = Integer.parseInt(args[4]);
final double lr = Double.parseDouble(args[3]);
//
JavaRDD<DataSet> javaRDDMnist = jsc.objectFile(inputPath);
JavaRDD<DataSet> javaRDDTrain = javaRDDMnist.map(new Function<DataSet, DataSet>() {
@Override
public DataSet call(DataSet next) throws Exception {
return new DataSet(next.getFeatureMatrix(),next.getFeatureMatrix());
}
});由於事先我們已經將Mnist資料集以DataSet的形式序列化儲存在HDFS上,因此我們一開始就直接反序列化讀取這些資料並儲存在RDD中就可以了。接下來,我們構建訓練資料集,由於Deep Autoencoder中,是以重構輸入圖片為目的的,所以feature和label其實都是原始圖片。此外,程式一開始的時候,就已經將學習率、迭代次數等等傳進來了。
3.設計Deep Autoencoder的網路結構,具體程式碼如下:
MultiLayerConfiguration netconf = new NeuralNetConfiguration.Builder()
.seed(seed)
.iterations(iterations)
.learningRate(lr)
.learningRateScoreBasedDecayRate(0.5)
.optimizationAlgo(OptimizationAlgorithm.LINE_GRADIENT_DESCENT)
.updater(Updater.ADAM).adamMeanDecay(0.9).adamVarDecay(0.999)
.list()
.layer(0, new RBM.Builder()
.nIn(numRows * numColumns)
.nOut(1000)
.lossFunction(LossFunctions.LossFunction.KL_DIVERGENCE)
.visibleUnit(VisibleUnit.IDENTITY)
.hiddenUnit(HiddenUnit.IDENTITY)
.activation("relu")
.build())
.layer(1, new RBM.Builder()
.nIn(1000)
.nOut(500)
.lossFunction(LossFunctions.LossFunction.KL_DIVERGENCE)
.visibleUnit(VisibleUnit.IDENTITY)
.hiddenUnit(HiddenUnit.IDENTITY)
.activation("relu")
.build())
.layer(2, new RBM.Builder()
.nIn(500)
.nOut(250)
.lossFunction(LossFunctions.LossFunction.KL_DIVERGENCE)
.visibleUnit(VisibleUnit.IDENTITY)
.hiddenUnit(HiddenUnit.IDENTITY)
.activation("relu")
.build())
//.layer(3, new RBM.Builder().nIn(250).nOut(100).lossFunction(LossFunctions.LossFunction.KL_DIVERGENCE).build())
//.layer(4, new RBM.Builder().nIn(100).nOut(30).lossFunction(LossFunctions.LossFunction.KL_DIVERGENCE).build()) //encoding stops
//.layer(5, new RBM.Builder().nIn(30).nOut(100).lossFunction(LossFunctions.LossFunction.KL_DIVERGENCE).build()) //decoding starts
//.layer(6, new RBM.Builder().nIn(100).nOut(250).lossFunction(LossFunctions.LossFunction.KL_DIVERGENCE).build())
.layer(3, new RBM.Builder()
.nIn(250)
.nOut(500)
.lossFunction(LossFunctions.LossFunction.KL_DIVERGENCE)
.visibleUnit(VisibleUnit.IDENTITY)
.hiddenUnit(HiddenUnit.IDENTITY)
.activation("relu")
.build())
.layer(4, new RBM.Builder()
.nIn(500)
.nOut(1000)
.visibleUnit(VisibleUnit.IDENTITY)
.hiddenUnit(HiddenUnit.IDENTITY)
.activation("relu")
.lossFunction(LossFunctions.LossFunction.KL_DIVERGENCE).build())
.layer(5, new OutputLayer.Builder(LossFunctions.LossFunction.MSE).activation("relu").nIn(1000).nOut(numRows*numColumns).build())
.pretrain(true).backprop(true)
.build();這裡需要說明下幾點。第一,和Hinton老先生論文裡的結構不太一樣的是,我並沒有把影象壓縮到30維這麼小。但是這肯定是可以進行嘗試的。第二,Visible和Hidden的轉換函式用的是Identity,而不是和論文中的Gussian和Binary。第三,學習率是可變的。在Spark叢集上訓練,初始的學習率可以設定得大一些,比如0.1,然後,在程式碼中有個機制,就是當損失函式不再下降或者下降不再明白的時候,減半學習率,也就是減小步長,試圖使模型收斂得更好。第四,更新機制用的是ADAM。當然,以上這些基本都是超引數的範疇,大家可以有自己的理解和調優過程。
4.訓練網路並在訓練過程中進行效果的檢視
ParameterAveragingTrainingMaster trainMaster = new ParameterAveragingTrainingMaster.Builder(batchSize)
.workerPrefetchNumBatches(0)
.saveUpdater(true)
.averagingFrequency(5)
.batchSizePerWorker(batchSize)
.build();
MultiLayerNetwork net = new MultiLayerNetwork(netconf);
//net.setListeners(new ScoreIterationListener(1));
net.init();
SparkDl4jMultiLayer sparkNetwork = new SparkDl4jMultiLayer(jsc, net, trainMaster);
sparkNetwork.setListeners(Collections.<IterationListener>singletonList(new ScoreIterationListener(1)));
int numEpoch = Integer.parseInt(args[1]);
for( int i = 0; i < numEpoch; ++i ){
sparkNetwork.fit(javaRDDTrain);
System.out.println("----- Epoch " + i + " complete -----");
MultiLayerNetwork trainnet = sparkNetwork.getNetwork();
System.out.println("Epoch " + i + " Score: " + sparkNetwork.getScore());
List<DataSet> listDS = javaRDDTrain.takeSample(false, 50);
for( DataSet ds : listDS ){
INDArray testFeature = ds.getFeatureMatrix();
INDArray testRes = trainnet.output(testFeature);
System.out.println("Euclidean Distance: " + testRes.distance2(testFeature));
}
DataSet first = listDS.get(0);
INDArray testFeature = first.getFeatureMatrix();
double[] doubleFeature = testFeature.data().asDouble();
INDArray testRes = trainnet.output(testFeature);
double[] doubleRes = testRes.data().asDouble();
for( int j = 0; j < doubleFeature.length && j < doubleRes.length; ++j ){
double f = doubleFeature[j];
double t = doubleRes[j];
System.out.print(f + ":" + t + " ");
}
System.out.println();
}5.Spark集訓訓練的過程和結果展示
Spark訓練過程中,stage的web ui:
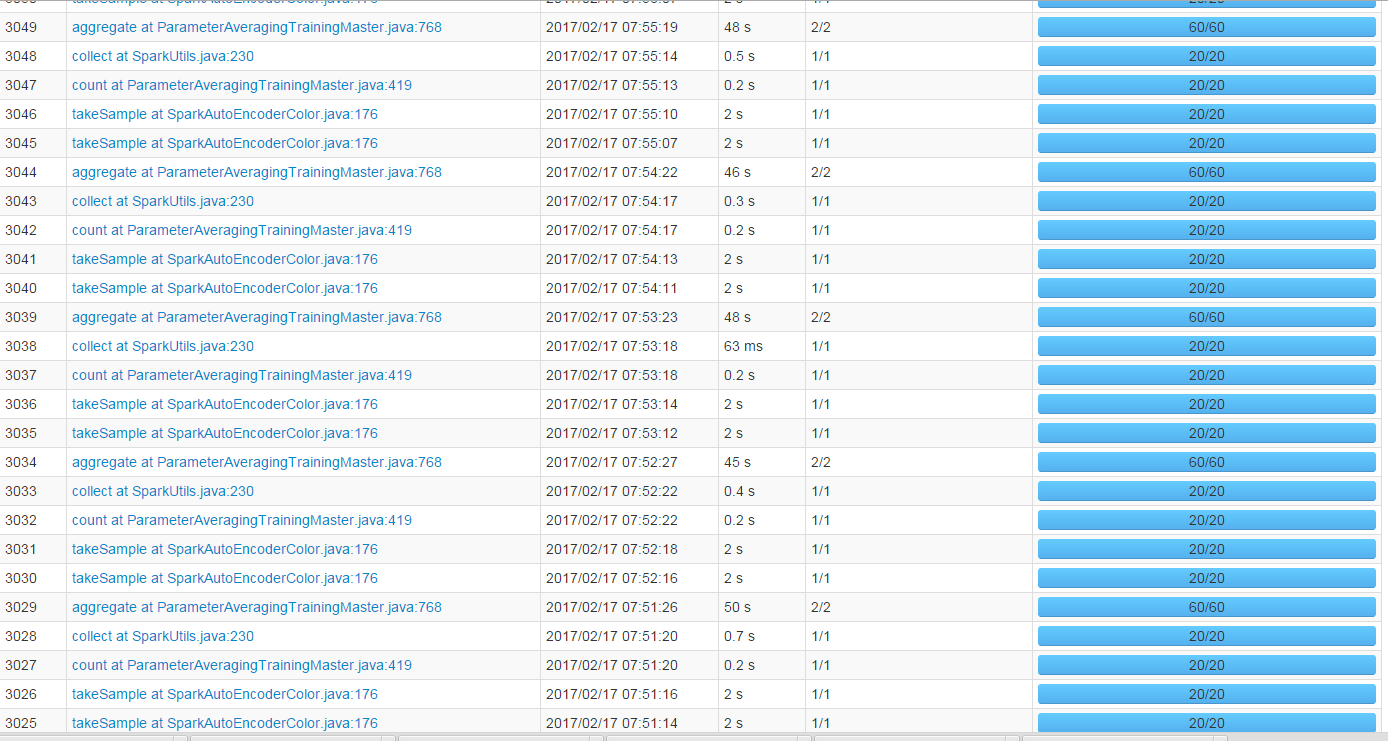
從圖中可以看出,aggregate是做引數更新時候進行的聚合操作,這個action在基於Spark的大規模機器學習演算法中也是很常用的。至於有takeSample的action,主要是之前所說的,在訓練的過程中會抽取一部分資料來看效果。下面的圖就是直觀的比較
訓練過程中,資料的直觀比對

這張圖是剛開始訓練的時候,歐式距離會比較大,當經過100~200輪的訓練後,歐式距離平均在1.0左右。也就是說,每個畫素點原始值和預測值的差值在0.035左右,應該說比較接近了。最後來看下視覺化介面展現的圖以及他們的距離計算
原始圖片和重構圖片對比以及他們之間的歐式距離
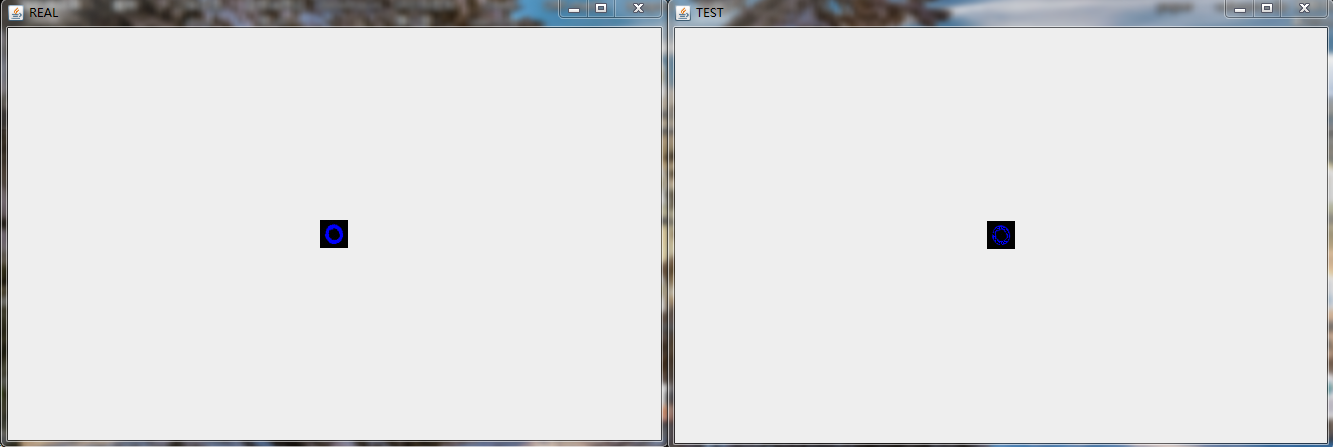

第一張圖左邊的原始圖,右邊是用訓練好的Deep Autoencoder預測的或者說重構的圖:圖有點小,不過仔細看,發現基本還是很像的,若干畫素點上明暗不太一樣。不過總體還算不錯。下面的圖,是兩者歐式距離的計算,差值在1.4左右。
最後做一些回顧:
用堆疊RBM構成DBN做影象壓縮,在理論上比單純增加全連階層的效果應該會好些,畢竟每一層RBM本身可以利用自身可以重構輸入資料的特點進行更為有效的壓縮。從實際的效果來看,應該也是還算看得過去。其實影象壓縮本身如果足夠高效,那麼對影象檢索的幫助也是很大。所以Hinton老先生的一篇論文就是利用Deep AutoEncoder對影象進行壓縮後再進行檢索,論文中把這個效果和用歐式距離還有PCA提取的圖片特徵進行了比較,論文中的結果是用Deep AutoEncoder的進行壓縮後在做檢索的效果最佳。不過,這裡還是得說明,在論文中RBM的Hidden的轉換函式是binary,因為作者希望壓縮出來的結果是0,1二進位制的。這樣,檢索圖片的時候,計算Hamming距離就可以了。而且這樣即使以後圖片的數量急劇增加,檢索的時間不會顯著增加,因為計算Hamming距離可以說計算機是非常快的,底層電路做異或運算就可以了。但是,我自己覺得,雖然壓縮成二進位制是個好方法,檢索時間也很短。但是二進位制的表現力是否有所欠缺呢?畢竟非0即1,和用浮點數表示的差別,表現力上面應該是差蠻多的。所以,具體是否可以在影象檢索系統依賴這樣的方式,還有待進一步實驗。另外就是,上面在構建多層RBM的時候,其實有很多超引數可以調整,包括可以增加RBM的層數,來做進一步的壓縮等等,就等有時間再慢慢研究了。還有,Spark提交的命令這裡沒有寫,不過在只之前的文章裡有提到,需要的同學可以參考。至於模型的儲存,都有相應的介面可以呼叫,這裡就不贅述了。。。