
Deeplearning4j 實戰(8) : Keras為媒介匯入Tensorflow/Theano等其他深度學習庫的模型
在之前的幾篇部落格中,我直接通過Deeplearning4j進行建模、訓練以及評估預測。但在實際使用中,各個團隊未必都會將Deeplearning4j作為首選的開源庫。這樣一來,模型的複用就變得非常困難,無形中增加了重複勞動的成本。雖然我們可以自己開發一套不同庫之間模型轉換的工具,但是這需要對轉換雙方的庫的實現都要非常清楚,包括正確的解析模型檔案及引數,正確建模以及匯入引數等等,顯然這項工作出錯的可能性極大,而且現在主流的幾個深度學習庫的介面依然在變化,無疑使得這項工作更加繁瑣。
其實對於模型複用的問題,Deeplearning4j的團隊是給出瞭解決方案的,即通過Keras來讀取類似(Tensorflow、Theano)等開源庫的模型,而Deeplearning4j只需正確讀取Keras的模型檔案就可以了。換句話說,Keras作為Deeplearning4j讀取其他開源庫訓練出來的模型的橋樑和入口。在這裡,簡單介紹下Keras這個庫。Keras可以認為是對Tensorflow和Theano的抽象封裝,本身基於Python進行開發。它的明顯特點就是搭建網路更為快速和直觀,主流的神經網路結構在Keras被模組化,呼叫方便。後臺可以在Tensorflow和Theano之間切換,即把兩者作為Keras後臺張量計算的框架。目前Keras應該已經到了2.0的版本,介面相比於1.0也有了比較大的變化,和Tensorflow的結合也越發的緊密(連結:http://www.oschina.net/news/81072/google-tensorflow-chooses-keras)。Deeplearning4j支援對Keras 1.x.x版本模型的讀取。大致情況就先介紹到這裡,下面就Deeplearning4j讀取Keras的模型給出具體的例子。
這個例子是用MLP做Mnist資料集的分類,這裡為了相容兩個庫的資料讀取方式,將Mnist資料以圖片形式儲存而非二進位制檔案,其中訓練資料是42000,測試集是從中隨機挑出的1000張圖片。
首先我們需要安裝Keras的環境,簡單起見,我直接安裝了Anaconda Python2.7的版本,然後pip install keras==1.2.2安裝1.2.2版本的Keras。安裝好後,驗證一下即可:
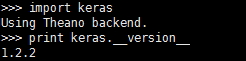
可以看到我們現在用的後臺是Theano。
Tensorflow的安裝也同樣用pip命令,這裡我安裝的是1.0.0版本的Tensorflow,驗證結果如圖所示:

驗證好環境後就可以開始利用Keras搭建多層感知機的網路,讀取資料並訓練。這一部分比較容易理解,我直接貼程式碼了:
#coding:utf-8 from __future__ import absolute_import from __future__ import print_function from keras.models import Sequential from keras.layers.core import Dense, Dropout, Activation, Flatten from keras.layers.convolutional import Convolution2D, MaxPooling2D, ZeroPadding2D from keras.optimizers import SGD from keras.utils import np_utils, generic_utils from six.moves import range from data import load_data,mlp_load_data,mlp_load_test_data import random,cPickle from keras.callbacks import EarlyStopping import numpy as np np.random.seed(1024) #載入資料 data, label = mlp_load_data() test_data, test_label = mlp_load_test_data() #label為0~9共10個類別,keras要求形式為binary class matrices,轉化一下,直接呼叫keras提供的這個函式 nb_class = 10 label = np_utils.to_categorical(label, nb_class) #定義多層感知機 def MLP(): model = Sequential() model.add(Dense(input_dim=784,output_dim=500, init='glorot_uniform')) model.add(Activation('relu')) #model.add(Dropout(0.5)) model.add(Dense(input_dim=500,output_dim=500,init='glorot_uniform')) model.add(Activation('relu')) model.add(Dropout(0.5)) model.add(Dense(input_dim=500,output_dim=10,init='glorot_uniform')) model.add(Activation('softmax')) return model ############# #開始訓練模型 ############## model = MLP() sgd = SGD(lr=0.0001, decay=1e-6, momentum=0.9, nesterov=True) model.compile(loss='categorical_crossentropy', optimizer=sgd) model.fit(data, label, batch_size=128,nb_epoch=10) classes = model.predict_classes(test_data) acc = np_utils.accuracy(classes, test_label) print('Test accuracy:', acc) ##儲存模型資訊和weight json_string = model.to_json() with open("model.json", "w") as json_file: json_file.write(json_string) model.save_weights('model_weights.h5')
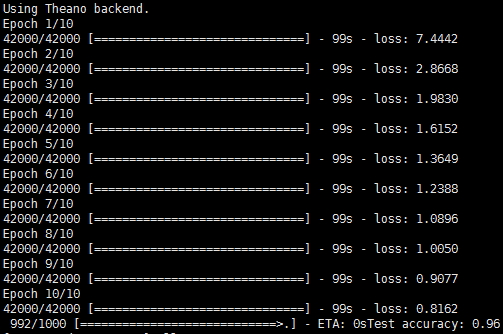
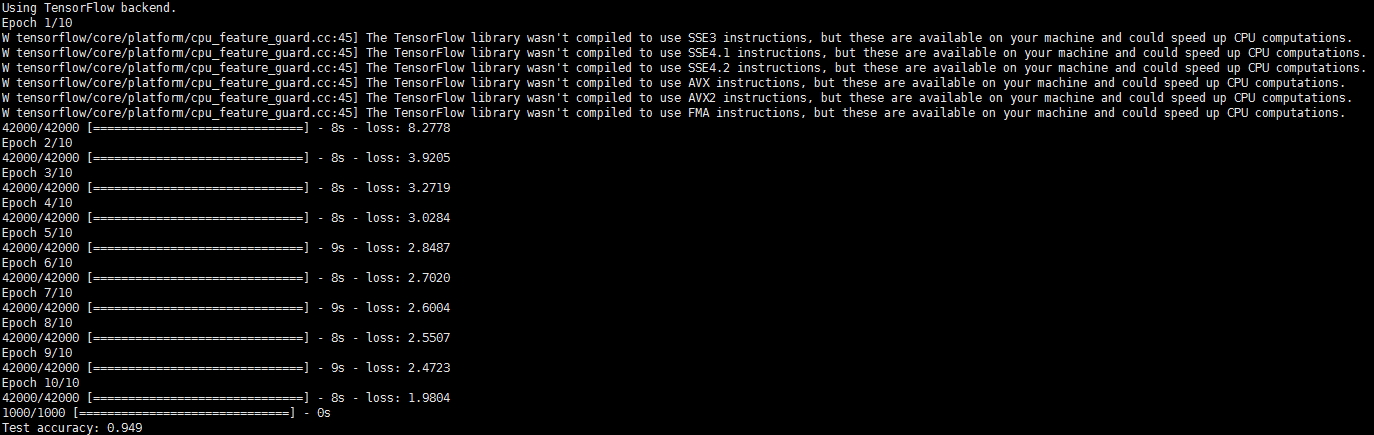
簡單解釋下這段程式碼。首先讀取目錄中的圖片資料,包括訓練資料和測試資料。然後定義三層的全連線網路結構,選擇優化演算法SGD以及損失函式,最後開始訓練模型。在模型訓練完成之後,評估模型的準確率並儲存儲存模型及引數。在這裡,我們重點是要將訓練好的模型儲存下來,以便之後被Deeplearning4j讀取並複用,因此模型的訓練過程以及超引數的設定並沒有經過精心的設計,跑通即可。下面兩張圖是分分別基於Theano和Tensorflow的訓練過程及評估結果:
Theano作為後端的訓練過程以及預測:
Tensorflow作為後端的訓練過程以及預測結果:
到此,基於不同後臺的模型已經被訓練並儲存了下來。而要通過Deeplearning4j對模型進行復用則只需要利用已有的介面讀取模型及引數檔案即可。具體邏輯如下:
System.out.println("Load data....");
List<DataSet> testData = new ArrayList<DataSet>();
final ImageLoader imageLoader = new ImageLoader(28, 28, 1);
File dir = new File("mnist_small");
if( !dir.isDirectory() ){
System.err.println("Not A Directory");
return;
}
File[] pics = dir.listFiles();
System.out.println("Total Test Image: " + pics.length);
for( File pic : pics ){
INDArray features = imageLoader.asRowVector(pic);
String picName = pic.getName();
INDArray labels = Nd4j.zeros(10);
String label = picName.split("\\.")[0];
int intLabel = Integer.parseInt(label);
labels.putScalar(0, intLabel, 1.0);
DataSet test = new DataSet(features, labels);
testData.add(test);
}
//Load Model
MultiLayerNetwork model = KerasModelImport.importKerasSequentialModelAndWeights("keras_model/model.json", "keras_model/model_weights.h5");
Evaluation eval = new Evaluation(10);
for( DataSet ds : testData ){
INDArray output = model.output(ds.getFeatureMatrix(), false);
eval.eval(ds.getLabels(), output);
}
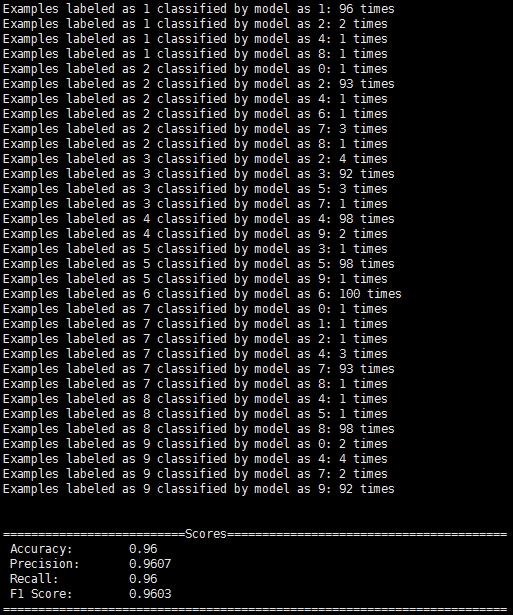
System.out.println(eval.stats());由於測試的資料集是以圖片的形式儲存的,所以先寫一段讀取圖片資料的邏輯,然後就是利用KerasModelImport中的static方法讀取之前已經儲存下來的模型然後再對測試資料集進行分類準確性評估。基於Theano和Tensorflow的模型被Deeplearning4j讀取後評估的效果如下:
首先是DL4j-Theano模型的評估:
接下來是DL4j-Tensorflow的模型評估:
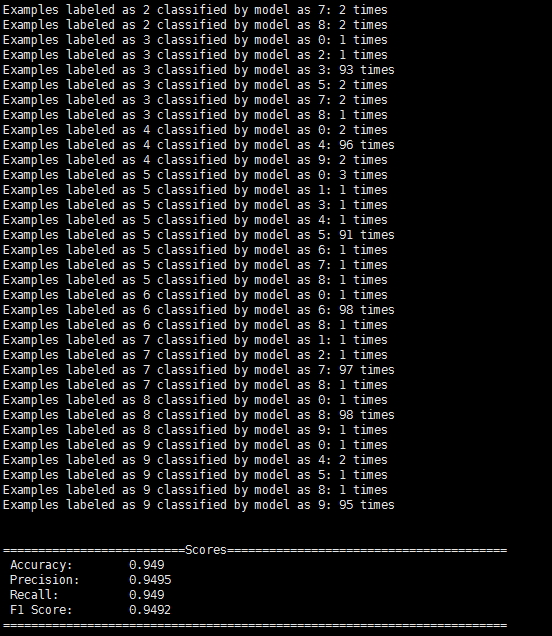
對比之前的圖片可以看到,Deeplearning4j讀取的模型的評估效果和用模型本身預測的準確性幾乎是完全一致的。這樣,我們就基本完成了利用Theano和Tensorflow作為後臺,以Keras作為橋樑對模型進行讀取和複用的工作了。
最後做下簡單的總結。本文主要是利用Deeplearning提供的匯入Keras模型的介面,對基於不同後臺訓練的Keras模型進行讀取和複用,並且給出了讀取前後模型的預測準確性評估。可以看出,複用的效果和直接使用模型預測的準確率幾乎是一致的。除了Tensorflow和Theano以外,其他的深度學習開源庫如Caffe,Torch等等都可以通過類似的方式將模型複用到Deeplearning4j中。不過這會依賴Keras對這些庫生成模型的解析工作。目前的Deeplearning4j只支援對Keras1.x.x的模型讀取,不過對2.x.x的支援也已經在開發中了。