
基於帕累托最優的多目標SNP選擇
#引用
##LaTex
@article{GUMUS201323, title = “Multi objective SNP selection using pareto optimality”, journal = “Computational Biology and Chemistry”, volume = “43”, pages = “23 - 28”, year = “2013”, issn = “1476-9271”, doi = “https://doi.org/10.1016/j.compbiolchem.2012.12.006”, url = “http://www.sciencedirect.com/science/article/pii/S1476927112001156
##Normal
Ergun Gumus, Zeliha Gormez, Olcay Kursun,
Multi objective SNP selection using pareto optimality,
Computational Biology and Chemistry,
Volume 43,
2013,
Pages 23-28,
ISSN 1476-9271,
#摘要
Biomarker discovery 生物標誌物發現
SNP — single nucleotide polymorphism 單核苷酸多型性
傳統單目標 — 最大化分類準確度
1 高分類準確度 2 種族群體遺傳多樣性與地理距離的相關性
#主要內容
資料集: Human Genome Diversity Project (HGDP) SNP 資料集 1064個個體 52個族群 原始資料: 1043個個體 每個個體 — 660,918 SNPs(163來自線粒體DNA,排除)— 用660,755 每個SNP — 2個等位基因 — 編碼表示為:
目標一:
高分類準確度 — mutual information MI 互資訊
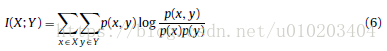
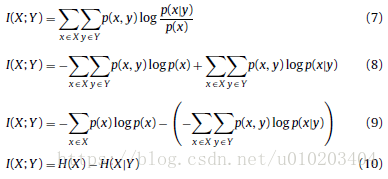
— 隨機變數的熵
目標二:
基因組地理相關性 — principal components analysis PCA
由於維度較高 — 對PCA使用了“維度戲法”

— 維協方差矩陣 — 為中心資料矩陣,

— 特徵向量 兩邊同乘

— 協方差矩陣的第個特徵向量 兩邊同乘

可得:
