
十七週翻譯
文章來自《P
原作者:Dmitri Korotkevitch
SQL Server統計資訊簡介
SQL Server統計資訊是包含有關索引鍵中資料分佈的資訊的系統物件值,有時是常規列值。 可以在任何支援的資料型別上建立統計資訊比較操作,例如>,<,=等。讓我們從清單2-15中建立的dbo.Books表中檢查IDX_BOOKS_ISBN索引統計資訊在前一章中。 您可以使用DBCC SHOW_STATISTICS('dbo.Books',IDX_BOOKS_ISBN)來完成此操作命令。 結果如圖3-1所示。
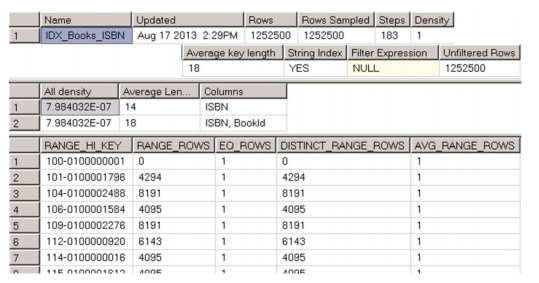
圖3-1 DBCC SHOW_STATISTICS輸出
如您所見,DBCC SHOW_STATISTICS命令返回三個結果集。第一個包含有關統計資訊的常規元資料資訊,例如名稱,更新日期,索引中的行數在更新統計資料時,等等。第一個結果集中的Steps列表示直方圖中的步數/值的數量(稍後將詳細介紹)。 Query不使用“密度”值優化器顯示僅用於向後相容目的。
第二個結果集稱為密度向量,包含有關組合密度的資訊來自統計(索引)的關鍵值。它是基於1 /不同值的數量計算的公式,它表示平均每個鍵值組合有多少行。
即便如此IDX_Books_ISBN索引只有一個鍵列定義了ISBN,它還包括一個聚簇索引鍵作為一部分索引行。我們的表有1,252,500個唯一的ISBN值,ISBN列的密度為1.0 /1,252,500 = 7.984032E-07。 (ISBN,BookId)列的所有組合也是唯一的並且具有密度相同。 最後的結果集稱為直方圖。直方圖中的每個記錄,稱為直方圖步驟,包括統計資訊(索引)最左列中的示例鍵值和有關的資訊資料分佈在從前一個到當前RANGE_HI_KEY值的值範圍內。我們來看看 直方圖列更深入。
RANGE_HI_KEY列儲存金鑰的樣本值。 這個值是直方圖步驟定義的範圍的上限鍵值。 例如,從直方圖中記錄(步驟)#3,RANGE_HI_KEY ='104-0100002488'圖3-1儲存了ISBN>'101-0100001796'的間隔資訊到ISBN <='104-0100002488'。RANGE_ROWS列估計間隔內的行數。例如,記錄(步驟)#3定義的間隔有8,191行。EQ_ROWS表示有多少行的鍵值等於RANGE_HI_KEY上限值。 在我們的例子中,只有一行ISBN ='104-0100002488'。
DISTINCT_RANGE_ROWS表示金鑰的不同值在這段時間內。 在我們的例子中,鍵的所有值都是唯一的,所以DISTINCT_RANGE_ROWS = RANGE_ROWS。
AVG_RANGE_ROWS表示每個不同鍵的平均行數區間中的值。 在我們的例子中,鍵的所有值都是唯一的,所以AVG_RANGE_ROWS = 1。
讓我們在索引中插入一組重複的ISBN值,程式碼如清單3-1所示。
清單3-1 將重複的ISBN值插入索引中
;with Prefix(Prefix) as ( select Num from (values(104),(104),(104),(104),(104)) Num(Num) ) ,Postfix(Postfix) as ( select 100000001 union all select Postfix + 1 from Postfix where Postfix < 100002500 ) insert into dbo.Books(ISBN, Title) select convert(char(3), Prefix) + '-0' + convert(char(9),Postfix) ,'Title for ISBN' + convert(char(3), Prefix) + '-0' + convert(char(9),Postfix) from Prefix cross join Postfix option (maxrecursion 0); -- Updating the statistics update statistics dbo.Books IDX_Books_ISBN with fullscan;
現在,如果你再次執行DBCC SHOW_STATISTICS('dbo.Books',IDX_BOOKS_ISBN)命令,你將
看到如圖3-2所示的結果。
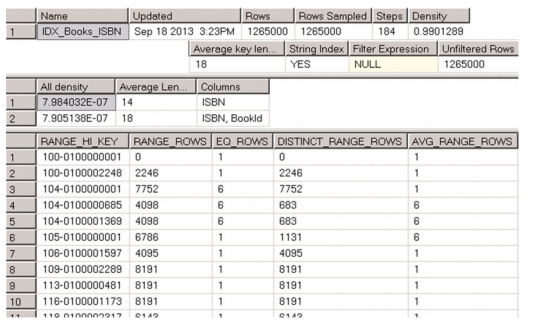
圖3-2 DBCC SHOW_STATISTICS輸出
帶有字首104的ISBN值現在有重複,這會影響直方圖。還值得一提的是,第二結果集中的密度資訊也發生了變化。具有重複值的ISBN s的密度高於(ISBN,BookId)列的組合,這仍然是唯一的。
讓我們執行SELECT BookId,Title FROM dbo.Books WHERE ISBN LIKE'114%'語句並檢查執行計劃,如圖3-3所示。
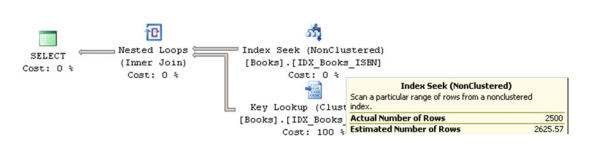
圖3-3 執行計劃查詢
大多數執行計劃操作員都有兩個重要的屬性。實際行數指示運算子執行過程中處理了多少行。估計行數指示在查詢優化階段為該運算子估計的SQLServer行數。在我們的例子中,SQLServer估計有2625行ISBNs從114開始。如果您檢視圖3-2所示的直方圖,您將看到步驟10儲存ISBN區間的資料分佈資訊,這些資訊包括所選的值。即使使用線性近似,也可以估計要接近SQL Server所確定的行數。關於統計有兩件非常重要的事情要記住。
直方圖僅儲存最左側統計(索引)列的資料分佈資訊。統計學中有關於鍵值的多列密度的資訊,但就是這樣。直方圖中的所有其他資訊僅涉及最左邊的統計列的資料分佈。
SQL Server最多保留直方圖中的200個步驟,而不管表的大小以及表是否被分割槽。每個直方圖步驟所覆蓋的間隔隨著表的增長而增加。這導致對於大型表的統計資訊不那麼準確。
在複合索引的情況下,當索引中的所有列都用作所有查詢中的謂詞時,將具有較低密度/較高唯一值百分比的列定義為索引的最左側列是有益的。這將允許SQL Server更好地利用統計資料中的資料分佈資訊。但是,您應該考慮謂詞的SARGability(可搜尋性)。例如,如果所有查詢都在where子句中使用[email protected]和[email protected]謂詞,那麼最好將LastName作為索引中最左邊的列。然而,對於
[email protected]和LastName<>@LastName,其中LastName不可SARGable。
列級統計
除了索引級統計之外,還可以建立單獨的列級統計資訊。此外,在某些情況下,SQL Server會自動建立這樣的統計資料。讓我們看一個示例,建立一個表,並用清單3-2所示的資料填充它。
統計和執行計劃
SQL Server預設自動建立和更新統計資訊。 資料庫有兩個選項控制此類行為的級別:
1.“自動建立統計資訊”控制優化程式是否建立列級別自動統計。 此選項不會影響索引級別的統計資訊永遠創造。 預設情況下啟用“自動建立統計資料庫”選項。
2.啟用“自動更新統計資料庫”選項後,SQL Server將進行檢查如果每次編譯或執行查詢和更新時統計資訊都已過時如果需要的話。 “自動更新統計資料庫”選項也已啟用預設。
提示 您可以使用STATISTICS_控制索引級別上統計資訊的自動更新行為NORECOMPUTE索引選項。 預設情況下,此選項設定為OFF,這意味著統計資訊是自動的更新。 在索引或表級別更改自動更新行為的另一種方法是使用sp_autostats系統儲存過程。
SQL Server根據影響統計資訊列的INSERT,UPDATE,DELETE和MERGE語句執行的更改次數確定統計資訊是否已過時。SQL Server計算統計資訊列的更改次數,而不是更改的行數。 例如,如果您將同一行更改100次,則將其計為100次更改而不是1次更改。
有三種不同的方案,稱為統計資訊更新閾值,有時也稱為統計資訊重新編譯閾值,其中SQL Server將統計資訊標記為過時。
當表為空時,SQL Server在向表中新增資料時會過時。
當表的行少於500行時,SQL Server會在統計列每500次更改後過期統計資訊。
在SQL Server 2016和SQL Server 2016之前,資料庫相容級別<130:當一個表有500行或更多行時,SQL Server會在每500+(表中總行數的20%)更改統計資訊後過期統計資訊列。
在SQL Server 2016中,資料庫相容級別為130:大型表上的統計資訊更新閾值將變為動態,並取決於表的大小。 表具有的行越多,閾值越低。在具有數百萬甚至數十億行的大型表上,統計資訊更新閾值可能只是表中總行數的一小部分。SQL Server 2008R2 SP1及更高版本中的跟蹤標誌T2371也可以啟用此行為。
表3-1總結了不同版本的SQL Server中的統計資訊更新閾值行為
表3-1. 統計資訊更新閾值和SQL Server版本
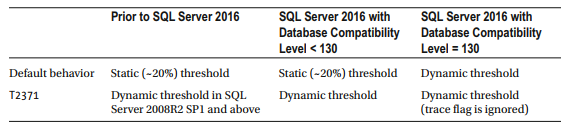
這導致我們得出一個非常重要的結論。 使用靜態統計資訊更新閾值,觸發統計資訊更新所需的統計資訊列的更改次數與表大小成比例。表越大,統計資訊自動更新的次數就越少。 例如,對於包含10億行的表,您需要對統計資訊列執行大約2億次更改,以使統計資訊過期。建議儘可能使用動態更新閾值。
讓我們來看看這種行為如何影響我們的系統和執行計劃。 此時,表dbo.Books有1,265,000行。 讓我們在表中新增250,000行,字首為999,如清單3-5所示。在此示例中,我使用的是未啟用T2371的SQL Server 2012。如果在啟用動態統計資訊更新閾值的情況下執行它,則可以看到不同的結果。 此外,SQL Server 2014中引入的新基數估計器也可以改變行為。 我們將在本章後面討論它。
清單3-5. 將行新增到dbo.Books
;with Postfix(Postfix) as ( select 100000001 union all select Postfix + 1 from Postfix where Postfix < 100250000 ) insert into dbo.Books(ISBN, Title) select '999-0' + convert(char(9),Postfix) ,'Title for ISBN 999-0' + convert(char(9),Postfix) from Postfix option (maxrecursion 0);
現在,讓我們執行SELECT * FROM dbo.Books WHERE ISBN LIKE'999%'查詢,選擇具有這種字首的所有行。
如果檢查查詢的執行計劃(如圖3-7所示),您將看到非聚集索引查詢和鍵查詢操作,即使它們在您需要從表中選擇近20%的行的情況下效率低下。
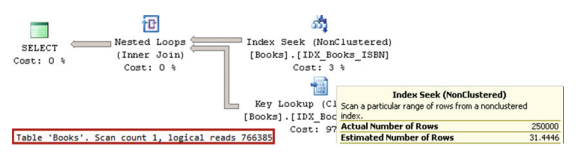
圖3-7 查詢的執行計劃選擇具有999字首的行
您還將在圖3-7中注意到,Index Seek運算子的估計行數和實際行數之間存在巨大差異。 SQL Server估計表中只有31.4行,字首為999,儘管有250,000行具有這樣的字首。結果,產生了非常低效的計劃。
讓我們通過執行DBCC SHOW_STATISTICS('dbo.Books',IDX_BOOKS_ISBN)命令來檢視IDX_BOOKS_ISBN統計資訊。 輸出如圖3-8所示。正如您所看到的,即使我們在表中插入了250,000行,統計資訊也未更新,並且直方圖中沒有字首999的資料。第一個結果集中的行數對應於上次統計資訊更新期間表中的行數。 它不包括剛剛插入的250,000行。
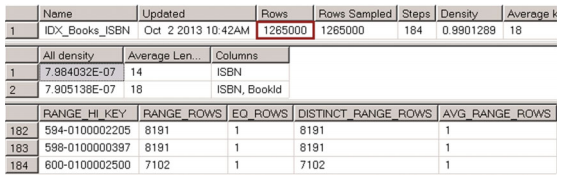
圖3-8. IDX_BOOKS_ISBN統計資料
現在讓我們使用UPDATE STATISTICS dbo.Books IDX_Books_ISBN WITH FULLSCAN命令更新統計資訊,然後再次執行SELECT * FROM dbo.Books WHERE ISBN LIKE'990%'查詢。查詢的執行計劃如圖3-9所示。估計的行數現在是正確的,並且SQL Server最終得到了一個更有效的執行計劃,該計劃使用聚集索引掃描,I / O讀取比以前少了大約17倍。

圖3-9. 統計資訊更新後查詢選擇具有999字首的行的執行計劃
如您所見,不正確的基數估計可能導致執行計劃效率極低。 過時的統計資料可能是不正確基數估計的最常見原因之一。您可以通過檢查執行計劃中的估計和實際行數來查明其中一些情況。 這兩個值之間的巨大差異通常表明統計資料不正確。更新統計資訊可以解決此問題並生成更高效的執行計劃。
統計維護
正如我已經提到的,預設情況下SQL Server會自動更新統計資訊。對於小的表,這種行為通常是可以接受的;但是,對於數百萬或數十億行的大型表,您不應該依賴自動統計更新,除非您使用資料庫相容性級別為130或啟用跟蹤標誌T2371的SQL Server 2016。要通過20%的統計資料更新閾值觸發統計資料更新,所需要的更改數量將非常高,因此,更新不會被頻繁地觸發。
建議在這種情況下手動更新統計資訊。在選擇最佳統計維護策略時,必須分析表的大小、資料修改模式和系統可用性。例如,如果系統在業務時間之外沒有負載,您可以決定每晚更新關鍵表的統計資訊。不要忘記,統計資料和/或索引維護會給SQL Server增加額外的負載。您必須分析它如何影響同一伺服器和/或磁碟陣列上的其他資料庫。
在設計統計維護策略時要考慮的另一個重要因素是如何修改資料。對於鍵值不斷增加或減少的索引,您需要更頻繁地更新統計資訊,例如當索引中最左邊的列被定義為identity或使用序列物件填充時。如您所見,如果特定鍵值位於直方圖之外,SQL Server會大大低估行數。在SQL Server 2014到2016年間,這種行為可能有所不同,我們將在本章後面看到。
您可以使用update statistics命令更新統計資訊。當SQL Server更新統計資訊時,它讀取資料的一個示例,而不是掃描整個索引。您可以通過使用FULLSCAN選項來更改這種行為,該選項強制SQL Server讀取和分析來自索引的所有資料。正如您可能猜到的那樣,該選項提供了最準確的結果,儘管在大型表的情況下,它可能引入大量I/O活動。
注意,SQL Server在重新構建索引時更新統計資訊。我們將在第6章“索引碎片”中更詳細地討論索引維護。
可以使用sp_updatestats系統儲存過程更新資料庫中的所有統計資訊。建議您使用此儲存過程,並在將其升級到新版本的SQL Server後更新資料庫中的所有統計資訊。您應該與DBCC UPDATEUSAGE儲存過程一起執行它,該儲存過程將糾正目錄檢視中不正確的頁計數和行計數資訊。
系統dm_db_stats_properties DMV顯示自上次統計資料更新以來對統計資料列所做的修改的數量。程式碼利用了DMV,如清單3-9所示。
清單3 - 9 使用sys.dm_db_stats_properties
select s.stats_id as [Stat ID], sc.name + '.' + t.name as [Table], s.name as [Statistics] ,p.last_updated, p.rows, p.rows_sampled, p.modification_counter as [Mod Count] from sys.stats s join sys.tables t on s.object_id = t.object_id join sys.schemas sc on t.schema_id = sc.schema_id outer apply sys.dm_db_stats_properties(t.object_id,s.stats_id) p where sc.name = 'dbo' and t.name = 'Books';
查詢結果如圖3-11所示,表明自上次統計資訊更新以來,對統計資訊列進行了25萬次修改。您可以構建一個定期檢查sys的統計維護例程。使用大的modification_counter值重新構建統計資訊。

圖3-11.Sys.dm_db_stats_properties輸出
另一個與統計資訊相關的資料庫選項是自動非同步更新統計資訊。預設情況下,當SQL Server檢測到統計資訊過時時,它會暫停查詢執行,同步更新和統計資訊,並在統計資訊更新完成後生成新的執行計劃。通過非同步統計資訊更新,SQL Server使用舊的執行計劃執行查詢,該執行計劃基於過時的statist,同時在後臺非同步更新統計資訊。建議您保持同步統計資訊更新,除非系統有非常短的查詢超時,在這種情況下,同步統計資訊更新可以超時查詢。
最後,在建立新索引時,SQL Server不會自動刪除列級統計資訊。您應該手動刪除冗餘的列級統計資料物件。