
基於指紋的音樂檢索原理詳述
轉載自:https://blog.csdn.net/yutianzuijin/article/details/36929765
本部落格將詳細敘述基於指紋的音樂檢索的具體原理和實現。
1 搜尋引擎的工作原理
在介紹音樂檢索的原理之前,我們先介紹一下搜尋引擎的工作原理,這是因為音樂檢索的工作原理和搜尋引擎的工作原理非常類似。
我們使用搜索引擎的時候,通常是這個流程:輸入一些關鍵詞,提交給搜尋引擎,搜尋引擎通過後臺分析返回與關鍵詞最相關的網頁。這個過程非常快,往往只有幾毫秒。但是目前網際網路上存在的網頁總數有數百億之多,搜尋引擎是如何在這麼短的時間內找到使用者需要的網頁的呢?這確實很神奇。
最樸素的方法肯定是一個一個網頁進行相似度匹配,每一個檔案計算一個相似度,然後對相似度進行排序,返回最相似的網頁。但是這也是最笨的方法,這需要每次查詢都需要遍歷一般所有的網頁,複雜度非常高。搜尋引擎通過採用一種叫倒排索引的結構避免了樸素的匹配,在此之前我們先介紹一下樸素檢索的實現方法。
按照樸素方法,我們需要根據網頁檔案構造索引,如圖一所示。每一個網頁都會首先進行分詞,然後統計不同詞的詞頻或者其他特徵。有了這個索引結構,就可以設計最樸素的搜尋引擎。當用戶輸入的關鍵詞進入搜尋引擎之後,就會將關鍵詞進行特徵轉換,轉換成一個帶有權值的特徵向量,之後就可以和每一個網頁的特徵向量進行相似度匹配,例如餘弦相似性度量等,最後對匹配的結果排序即可。
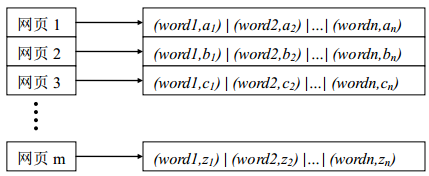
圖一 網頁的片語索引結構
倒排索引這個名詞聽著很玄乎,其實非常容易理解。樸素方法採用網頁的索引結構,構造單詞的統計資訊;倒排索引則相反,以單詞為索引結構,構造網頁的統計資訊,如圖二所示。

圖二 倒排索引示意圖
在倒排索引結構中,每一個單詞都對應一個倒排列表,倒排列表記載了出現過某個單詞的所有網頁的列表和單詞在該網頁中出現的位置資訊或者詞頻。例如,單詞1出現在網頁6和10中,詞頻分別是a1和a2。
搜尋引擎在獲得使用者輸入的關鍵詞之後,就查詢關鍵詞對應的倒排索引表,然後將多個關鍵詞的倒排索引表求交,獲得出現過所有關鍵詞的網頁,然後對這些網頁進行相似度計算。可以看出,通過採用倒排索引結構,使需要匹配的網頁數量急劇減少,因而大大加快了搜尋的速度。
上面是最簡單的搜尋引擎原理,如果大家想深入瞭解搜尋引擎,可以參看《這就是搜尋引擎》一書,該書詳細介紹了搜尋引擎的各個部分和檢索原理。下面開始介紹基於指紋的音樂檢索原理。
2 基於指紋的音樂檢索工作原理
基於指紋的音樂檢索工作原理和搜尋引擎非常相似,也是構造一個倒排索引結構,不過不是單詞的倒排索引,而是指紋的倒排索引。在基於指紋的音樂檢索 中,我們介紹了指紋的構造,在此不做過多介紹。指紋可以看做搜尋引擎檢索中的關鍵詞,但是與關鍵詞不同,每個指紋代表的資訊量較少,所以在音樂檢索中需要提取非常多的指紋完成單次檢索。例如,15s的片段往往需要提取幾萬個指紋才能查詢到正確的音樂。這就意味著搜尋引擎幾個關鍵詞的單次檢索在音樂檢索中變成了幾萬個指紋的單次檢索,檢索時間大大增加。
每個指紋都是一個整數,根據指紋的構造不同,可能需要24到30位不等,所以可以利用一個int型整數儲存每一個指紋。這樣所有指紋的空間就限定於一個int型整數所表示的範圍,也即0到4G。當音樂庫較小時,所有音樂產生的不同指紋數也較少,為了避免空間浪費,儲存所有的指紋可以採用散列表形式,如圖三所示。
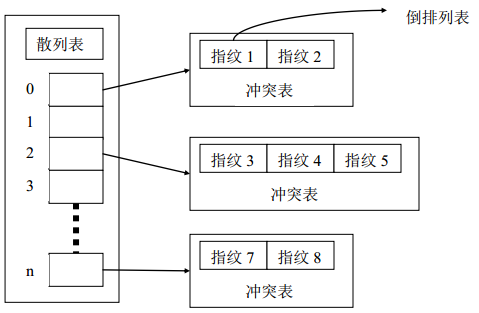
圖三 散列表形式的指紋檢索結構
當音樂庫非常大時,幾乎所有的指紋都可能會出現,這時採用散列表結構就沒有什麼優勢,可以直接分配一個大陣列來存放所有的指紋,然後每一個指紋都指向一個該指紋對應的倒排列表,如圖四所示。在圖四中假定每一個指紋的位數是24位,則需要分配一個長度是224的陣列,然後每一個指紋都指向一個倒排列表。倒排列表中儲存的是音樂id和該指紋在該首音樂中出現的位置。

圖四 基於指紋的倒排索引表
獲得圖四的倒排索引結構之後,檢索過程就比較容易了。但是過程卻和搜尋引擎不同,搜尋引擎需要對不同關鍵詞的倒排列表求交集,對交集內的網頁進行相似度計算。基於指紋的音樂檢索則需要一個間接的匹配過程,匹配過程如下:
- 將客戶端傳遞的音訊提取指紋,每個指紋伴隨有一個時間屬性;
- 對每一個提取的指紋都查詢倒排索引表,獲得該指紋對應的倒排列表;
- 將倒排列表中每一個音樂對應的時間和提取的指紋對應的時間進行相減,如果時間差大於零,則儲存該時間差到圖五所示的對應音樂中;
- 對每首歌中的時間差進行排序;
- 統計每首歌中時間差相同的個數,並返回個數最多的音樂。
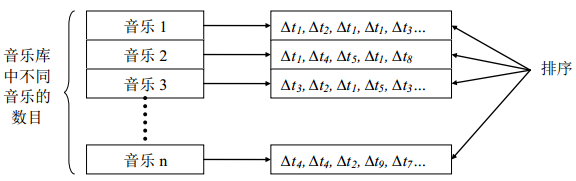
圖五 統計匹配的相似度
基於指紋的音樂檢索和搜尋引擎相比,複雜度大增,主要體現在兩個方面:首先,針對客戶端錄製的音訊,提取的指紋往往上萬,而這上萬個指紋都需要訪問倒排索引表,這意味著一次音樂檢索可以完成上萬次搜尋引擎的檢索;其次,由於單次檢索需要上萬次訪問倒排索引表,所以無法對音樂求交,因為求交的結果必然為零,我們只能將倒排列表中對應的音樂時間和提取指紋對應的時間相減,然後統計每一首音樂中不同時間差的個數,然後將個數作為匹配的結果。正是由於上面這兩個因素,所以單機上的曲庫做得不能太大,並且每一個指紋對應的倒排列表也要限制長度。