
基於opencv人臉檢測原理及實現
最近搞了幾天的人臉檢測,終於把大體框架和原理搞清楚了,現在寫出來供大家學習之用,如有不對之處,還請大家指正。也希望大家在學習opencv的過程中能將學習過程及重點記錄下來,以部落格的形式分析,畢竟opencv的教材還不太多,我們自己學習大部分要靠網上的資料。通過部落格分享的形式能使大家快速進步,同時也算是對自己學習的一個記錄和總結。只是一個倡議,大家自己決定,呵呵。
好了進入正題。
學習基於opencv的人臉檢測,首先要理清大概需要做哪些事情。這裡總共分兩步,第一步就是訓練分類器,第二步就是利用訓練好的分類器進行人臉檢測。
1、訓練分類器
訓練分類器我沒有學習,因為opencv的原始碼中(opencv安裝目錄\data\haarcascades)中已經有了很多訓練好的分類器供我們使用。但是有必要對分類器的訓練原理和過程做一些介紹,以便後面進一步的學習中能夠對這部分有一定了解。
目前人臉檢測分類器大都是基於haar特徵利用Adaboost學習演算法訓練的。
目標檢測方法最初由Paul Viola [Viola01]提出,並由Rainer Lienhart [Lienhart02]對這一方法進行了改善. 首先,利用樣本(大約幾百幅樣本圖片)的 harr 特徵進行分類器訓練,得到一個級聯的boosted分類器。訓練樣本分為正例樣本和反例樣本,其中正例樣本是指待檢目標樣本(例如人臉或汽車等),反例樣本指其它任意圖片,所有的樣本圖片都被歸一化為同樣的尺寸大小(例如,20x20)。
分類器訓練完以後,就可以應用於輸入影象中的感興趣區域(與訓練樣本相同的尺寸)的檢測。檢測到目標區域(汽車或人臉)分類器輸出為1,否則輸出為0。為了檢測整副影象,可以在影象中移動搜尋視窗,檢測每一個位置來確定可能的目標。 為了搜尋不同大小的目標物體,分類器被設計為可以進行尺寸改變,這樣比改變待檢影象的尺寸大小更為有效。所以,為了在影象中檢測未知大小的目標物體,掃描程式通常需要用不同比例大小的搜尋視窗對圖片進行幾次掃描。
分類器中的“級聯”是指最終的分類器是由幾個簡單分類器級聯組成。在影象檢測中,被檢視窗依次通過每一級分類器, 這樣在前面幾層的檢測中大部分的候選區域就被排除了,全部通過每一級分類器檢測的區域即為目標區域。 目前支援這種分類器的boosting技術有四種: Discrete Adaboost, Real Adaboost, Gentle Adaboost and Logitboost。"boosted" 即指級聯分類器的每一層都可以從中選取一個boosting演算法(權重投票),並利用基礎分類器的自我訓練得到。基礎分類器是至少有兩個葉結點的決策樹分類器。 Haar特徵是基礎分類器的輸入,主要描述如下。目前的演算法主要利用下面的Harr特徵。
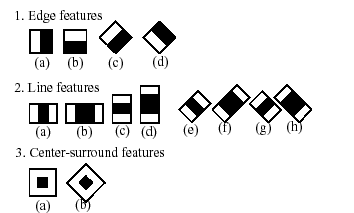
每個特定分類器所使用的特徵用形狀、感興趣區域中的位置以及比例係數(這裡的比例係數跟檢測時候採用的比例係數是不一樣的,儘管最後會取兩個係數的乘積值)來定義。例如在第二行特徵(2c)的情況下,響應計算為覆蓋全部特徵整個矩形框(包括兩個白色矩形框和一個黑色矩形框)象素的和減去黑色矩形框內象素和的三倍
。每個矩形框內的象素和都可以通過積分圖象很快的計算出來。
通過上述陳述,應該對整個訓練過程有個大概的瞭解,但是對於訓練的具體過程還是不太明晰,那麼可以繼續參考下面的文章:
http://apps.hi.baidu.com/share/detail/44451430
相信看過上面這篇文章以及前面的陳述後大家應該對分類器的訓練原理有了一個整體的瞭解,至於一些細節如果還不清晰應該不影響使用,畢竟那些細節可能需要數字影象處理的專業知識。
2、利用分類器進行檢測
前面也已經說過,opencv的原始碼中已經給我們提供了一些訓練好的分類器,例如人臉檢測分類器,人體檢測分類器等。那麼如果沒有什麼特定的需要,我們完全可以利用這些分類器直接進行人臉及人體檢測。
a、CvHaarClassifierCascade* cvLoadHaarClassifierCascade(const char* directory,cvSize orig_window_size);
directory
訓練好的分類器路徑
orig_window_size
級聯分類器訓練中採用的檢測目標的尺寸。這個資訊在分類器中沒有儲存,因此要單獨指出。
函式 cvLoadHaarClassifierCascade 用於從檔案中裝載訓練好的利用哈爾特徵的級聯分類器,或者從OpenCV中嵌入的分類器資料庫中匯入。分類器的訓練可以應用函式haartraining(詳細察看opencv/apps/haartraining) 這個數值是在訓練分類器時就確定好的,修改它並不能改變檢測的範圍或精度。
需要注意的是,這個函式已經過時了。現在的目標檢測分類器通常儲存在 XML 或 YAML 檔案中,而不是通過路徑匯入。從檔案中匯入分類器,可以使用函式 cvLoad 。b、CvSeq* cvHaarDetectObjects(const CvArr* image, CvHaarClassifierCascade* cascade,CvMemStorage* storage,double scale_factor=1.1,int min_neighbors=3,int flags=0,CvSize min_size=cvSize(0,0));
- image
- 被檢影象
- cascade
- harr 分類器級聯的內部標識形式
- storage
- 用來儲存檢測到的一序列候選目標矩形框的記憶體區域。
- scale_factor
- 在前後兩次相繼的掃描中,搜尋視窗的比例係數。例如1.1指將搜尋視窗依次擴大10%。
- min_neighbors
- 構成檢測目標的相鄰矩形的最小個數(預設-1)。如果組成檢測目標的小矩形的個數和小於min_neighbors-1 都會被排除。如果min_neighbors 為 0, 則函式不做任何操作就返回所有的被檢候選矩形框,這種設定值一般用在使用者自定義對檢測結果的組合程式上。
- flags
- 操作方式。當前唯一可以定義的操作方式是 CV_HAAR_DO_CANNY_PRUNING。如果被設定,函式利用Canny邊緣檢測器來排除一些邊緣很少或者很多的影象區域,因為這樣的區域一般不含被檢目標。人臉檢測中通過設定閾值使用了這種方法,並因此提高了檢測速度。
- min_size
- 檢測視窗的最小尺寸。預設的情況下被設為分類器訓練時採用的樣本尺寸(人臉檢測中預設大小是~20×20)。
函式 cvHaarDetectObjects 使用針對某目標物體訓練的級聯分類器在影象中找到包含目標物體的矩形區域,並且將這些區域作為一序列的矩形框返回。函式以不同比例大小的掃描視窗對影象進行幾次搜尋(察看cvSetImagesForHaarClassifierCascade)。 每次都要對影象中的這些重疊區域利用cvRunHaarClassifierCascade進行檢測。 有時候也會利用某些繼承(heuristics)技術以減少分析的候選區域,例如利用
Canny 裁減 (prunning)方法。 函式在處理和收集到候選的方框(全部通過級聯分類器各層的區域)之後,接著對這些區域進行組合並且返回一系列各個足夠大的組合中的平均矩形。調節程式中的預設引數(scale_factor=1.1, min_neighbors=3, flags=0)用於對目標進行更精確同時也是耗時較長的進一步檢測。為了能對視訊影象進行更快的實時檢測,引數設定通常是:scale_factor=1.2, min_neighbors=2, flags=CV_HAAR_DO_CANNY_PRUNING,
min_size=<minimum possible face size> (例如, 對於視訊會議的影象區域)。
c、void cvReleaseHaarClassifierCascade(CvHaarClassifierCascade** cascade);
#include "cv.h"
#include "highgui.h"
#include <stdio.h>
void displaydetection(IplImage* pInpImg,CvSeq* pFaceRectSeq,char* FileName);
int main(int argc,char** argv)
{
IplImage* pInpImg=0;
CvHaarClassifierCascade* pCascade=0; //指向後面從檔案中獲取的分類器
CvMemStorage* pStorage=0; //儲存檢測到的人臉資料
CvSeq* pFaceRectSeq; //用來接收檢測函式返回的一系列的包含人臉的矩形區域
if (argc<2)
{
printf("missing name of image file!\n");
return -1;
}
//初始化
pInpImg=cvLoadImage(argv[1],1);
pStorage=cvCreateMemStorage(0); //建立預設大先64k的動態記憶體區域
pCascade=(CvHaarClassifierCascade*)cvLoad("haarcascade_frontalface_alt.xml"); //載入分類器
if (!pInpImg||!pStorage||!pCascade)
{
printf("initialization failed:%s\n",(!pInpImg)?"can't load image file":(!pCascade)?"can't load haar-cascade---make sure path is correct":"unable to allocate memory for data storage",argv[1]);
return -1;
}
//人臉檢測
pFaceRectSeq=cvHaarDetectObjects(pInpImg,pCascade,pStorage,
1.2,2,CV_HAAR_DO_CANNY_PRUNING,cvSize(40,40));
//將檢測到的人臉以矩形框標出。
displaydetection(pInpImg,pFaceRectSeq,argv[1]);
cvReleaseImage(&pInpImg);
cvReleaseHaarClassifierCascade(&pCascade);
cvReleaseMemStorage(&pStorage);
return 0;
}
void displaydetection(IplImage* pInpImg,CvSeq* pFaceRectSeq,char* FileName)
{
int i;
cvNamedWindow("haar window",1);
printf("the number of face is %d",pFaceRectSeq->total);
for (i=0;i<(pFaceRectSeq?pFaceRectSeq->total:0);i++)
{
CvRect* r=(CvRect*)cvGetSeqElem(pFaceRectSeq,i);
CvPoint pt1={r->x,r->y};
CvPoint pt2={r->x+r->width,r->y+r->height};
// cvSetImageROI(pInpImg,*r);
// IplImage* dst=cvCreateImage(cvSize(92,112),pInpImg->depth,pInpImg->nChannels);
// cvResize(pInpImg,dst,CV_INTER_LINEAR);
// cvSaveImage("lian.jpg",dst);
cvRectangle(pInpImg,pt1,pt2,CV_RGB(0,255,0),3,4,0);
}
cvShowImage("haar window",pInpImg);
// cvResetImageROI(pInpImg);
cvWaitKey(0);
cvDestroyWindow("haar window");
}cascade
雙指標型別指標指向要釋放的cascade. 指標由函式宣告。
函式 cvReleaseHaarClassifierCascade 釋放cascade的動態記憶體,其中cascade的動態記憶體或者是手工建立,或者通過函式 cvLoadHaarClassifierCascade 或 cvLoad分配。三個主要函式介紹完之後,就可以看程式了,畢竟通過程式學函式和用法是最快的(個人覺得)。 通過上面的程式可以實現在一張圖片中檢測出人臉,並用矩形框標出。到此就完成了人臉檢測。下一篇文章將對人臉識別進行介紹。