
爬蟲課程:爬蟲基礎及靜態網頁爬蟲
以下是我的學習筆記,以及總結,如有錯誤之處請不吝賜教
本文主要介紹一些爬蟲基礎知識。
HTTP協議:
http是一個請求<->響應模式的典型範例,即客戶端向伺服器傳送一個請求資訊系,伺服器來響應這個資訊。在老的http版本中,每個請求都將被建立一個新的客戶端->伺服器的連結,在這個連線上傳送請求,然後節後請求。這樣的模式有一個很大的有點就是,簡單,容易理解和程式設計實現;特也有一個缺點就是效率低,因此Keep-Alive被提出用來解決效率低的問題。keep-alive功能使客戶端的連結持續有效,當出現對伺服器的後繼請求時,keep-alive功能避免了建立或者重新建立連線。
http/1.1預設情況下所有連線都被保持,除非在請求頭或者響應頭中指明要關閉:connection:close。
主要包括:物理層(電器連線)、資料鏈路層(交換機、STP、幀中繼)、網路層(路由器、IP協議)、傳輸層(TCP、UDP協議)、會話層(建立通訊連線、撥號上網)、表示層(每次連線只處理一個請求)、應用層(HTTP、FTP),具體如下圖:

特點:①應用層的協議,②無連線:每次連線只處理一個請求,③無狀態:每次連線、傳輸都是獨立的。
HTTP HEADER:
- request:

- response:

HTTP請求方法:主要有get、head、post等等,具體如下表:

HTTP響應狀態碼:
- 2**:成功
- 3**:跳轉

- 4**:客戶端錯誤
錯誤處理:

- 500伺服器錯誤
錯誤處理:

HTML語言:
是超文字標記語言,簡單來說是可以認為一種規範或者協議,瀏覽器根據html的語言規範來解析。html中與爬蟲相關的規範有以下幾個:

DOM樹:是用來做網頁資料分析及提取,我們可以利用Tag、Class、ID來找某一類或某一種元素並提取內容:
Javascript語言:
是執行在前端的程式語言,最典型的是用在動態網頁的資料、內容載入及呈現上,Javascript做網路請求的時候最常用的技術稱為:AJAX(asynchoronous javascript and xml),專門用來非同步請求資料。具體如下圖示例:

網頁抓取原理:
根據抓取物件型別:①靜態網頁、②動態網頁、③web service進行抓取,分為深度優先策略和寬度優先策略兩種:


策略選擇:
- 網頁距離種子站點的距離
- 全球資訊網深度並沒有很深,一個網頁有很多路徑課到達
- 寬度優先有利於多爬蟲並行合作抓取
- 深度限制於寬度優先相結合
不重複策略:
記錄抓取歷史的方法:
- 將訪問過的url儲存到資料庫:效率太低
- 用hashset將訪問過的url儲存起來,只需要接近o(1)的代價就可以查到一個url是否被訪問過了:消耗記憶體
- MD5方法:url經過MD5戶SHA-1等單項雜湊後再儲存到HashSet或資料庫

- Bit-Map方法:建立一個bitset,將每個url經過一個雜湊函式對映到某一位,①評用site方法估網站的網頁數量,②選擇合適的hash演算法和空間閾值,降低碰撞機率,③選擇合適的儲存結構和演算法,具體如下圖:
 優勢:對村抽進行進一步壓縮,在MD5的基礎上,可以衝128位壓縮到1位,一般情況,如果用4bit或者8bit表示一個url,也能壓縮32或者16倍;缺陷:碰撞概率增加
優勢:對村抽進行進一步壓縮,在MD5的基礎上,可以衝128位壓縮到1位,一般情況,如果用4bit或者8bit表示一個url,也能壓縮32或者16倍;缺陷:碰撞概率增加 - Bloom Filter方法:使用了多個雜湊函式,而不是一個。建立一個m位bitset,先將所以有位初始化為0,然後選擇k個不同的雜湊函式。第i個雜湊函式對字串str的結果記為h(i,str),且h(i,str)的範圍是0到m-1。只能插入,不能刪除。具體結構如圖:

如何使用以上方法:
- 多數情況下不需要壓縮,尤其網頁數量少的情況
- 網頁數量大的情況下,使用Bloom Filter壓縮
- 重點是計算碰撞概率,並根據碰撞概率來確定儲存空間的閾值
- 分散式系統,將雜湊對映到多臺主機的記憶體
網站結構分析:
- 一般網站對爬蟲都有限制,例如開啟robots.txt網頁:

- 利用sitemap裡的的資訊:大多數網站都會存在明確的top-down的分類的目錄結構,我們可以利用sitemap來分析網站結構和估算目標網頁的規模:


- 對網站目錄結構進行分析:例如www.mafengwo.cn這個網站,所有旅遊遊記都位於www.mafengwo.cn/mdd下,按照城市進行了分類,每個城市的遊記都位於城市的首頁,如下圖:
遊記的分頁格式:
遊記的頁面:

XPath語言:
是一門在 XML 文件中查詢資訊的語言。XPath 可用來在 XML 文件中對元素和屬性進行遍歷。具體教程可以看:W3school
- 基本語法:
@屬性:在DOM樹,以路徑的方式查詢節點,通過@符號來選取屬性,如下圖所示:rel class href都是屬性,可以通過“//*[@class='external text']”來選取對應元素;=符號要求屬性完全匹配,可以用contain方法來部分匹配,例如:“//*[contain(@class,'external')]”可以匹配,而“//*[@class='external']”則不能。
運算子:and和or運算子:選擇p或者span或者h1標籤的元素:
選擇class為editor或者tag的元素:

正則表示式:
正則表示式是對字串操作的一種邏輯公式,就是用事先定義好的一些特性字元,及這些特定字元的組合,組成一個規則字串,這個規則字串用來表發對字串的一種過濾邏輯。一些常用規則:

在爬蟲的解析中,經常會將正則表示式與Dom選擇器結合使用。正則表示式適用於字串特徵比較明顯的情況,但是同樣的正則表示式可能在HTML原始碼中多次出現,而DOM選擇器可以通過class及id來精確找到DOM塊,從而縮小查詢範圍。以下是一些常用爬蟲正則規則:
- 獲取標籤下的文字:

- 查詢特定類別的連結,例如/wiki/不包含category目錄:

- 查詢商品外鏈,例如jd的商品外鏈為7位數字的a標籤節點:
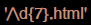
- 查詢淘寶的商品資訊,或者開始及結尾:

貪婪模式及非貪婪模式:?該字元緊跟任何一個其他限制符(*,+,?,{n},{n,},{n,m})後面時,匹配模式是非貪婪的。非貪婪模式儘可能少的匹配搜尋的字串,而預設的貪婪模式則儘可能多得匹配搜尋的字串,具體如下圖:
To be continue......