
NLP課程:nlp基礎word processing
阿新 • • 發佈:2018-12-23
以下是我的學習筆記,以及總結,如有錯誤之處請不吝賜教。
自然語言處理髮展:
在網上看了很多文章都沒有屢清楚LDA、n-gram、one-hot、word embeding、word2vec等等的關係,直到看到這篇文章:參考1
要分清楚兩個概念:語言模型和詞的表示
- 語言模型:分為文法語言和統計語言,我們現在常說的語言模型就是統計語言,就是把語言(詞的序列)看作一個隨機事件,並賦予相應的概率來描述其屬於某種語言集合的可能性。給定一個詞彙集合 V,對於一個由 V 中的詞構成的序列 S = 〈w1, · · · , wT 〉 ∈ Vn,統計語言模型賦予這個序列一個概率 P(S),來衡量 S 符合自然語言的語法和語義規則的置信度。
常見的統計語言模型有N-gram Model,最常見的是 unigram model、bigram model、trigram model 等等。形式化講,統計語言模型的作用是為一個長度為 m 的字串確定一個概率分佈 P(w1; w2; :::; wm),表示其存在的可能性,其中 w1 到 wm 依次表示這段文字中的各個詞。一般在實際求解過程中,通常採用下式計算其概率值: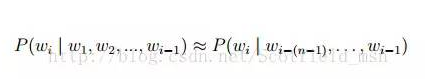
- 詞的表示:(參考)分為離散表示和分佈表示:
①離散表示主要有:one-hot、Bag of Words、TF-IDF
②分佈表示又分為:基於矩陣的分佈表示(主要有Glove模型、共現矩陣、SVD分解等等)和基於神經網路的分佈表示(主要有word2vec、NNLM、RNNLM、C&W等等)
NLTK語料庫:

文字處理流程:

- Tokenize就是分詞:
有不合語法的分詞需要用到正則表示式:


- 詞形歸一化:
①Stemming 詞⼲提取:⼀般來說,就是把不影響詞性的inflection的⼩尾巴砍掉 :
②Lemmatization 詞形歸⼀:把各種型別的詞的變形,都歸為⼀個形式: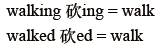
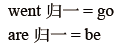
③一寫nltk實現stemming 的例子:
④Pos Tag:有時詞性不同重名會有小問題

- Stopwords:去停用詞

- 總結:文字預處理流水線:
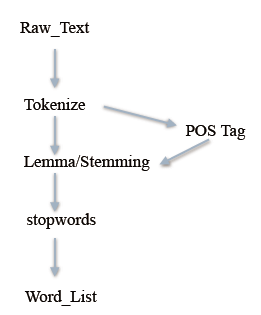
接下來我們就可以進行對清洗過的詞進行各種特徵工程的處理了。
To be continue.....