
乾貨滿滿的深度強化學習綜述(中文)
乾貨滿滿的深度強化學習綜述(中文)
https://mp.weixin.qq.com/s/HQStW2AW3UIZR1R-hvJ8AQ
0.來源說明
引用:深度強化學習綜述
作者:劉全,翟建偉,章宗長,鍾珊,周 倩,章 鵬,徐 進
單位:蘇州大學電腦科學與技術學院 、軟體新技術與產業化協同創新中心
出處:計算機學報,2017年第40卷
整理&排版:九三山人
1.內容提要
九三智給大家推薦一篇蘇州大學劉全老師等人綜述的深度強化學習方向發展情況,雖然是在2017年發表,沒有覆蓋到DeepMind打星際,OpenAI打DOTA等方面最新的進展,但也把
深度強化學習是人工智慧領域的一個新的研究熱點. 它以一種通用的形式將深度學習的感知能力與強化學習的決策能力相結合,並能夠通過端對端的學習方式實現從原始輸入到輸出的直接控制。自提出以來, 在許多需要感知高維度原始輸入資料和決策控制的任務中,深度強化學習方法已經取得了實質性的突破.
該文首先闡述了 3 類主要的深度強化學習方法,包括基於值函式的深度強化學習、基於策略梯度的深度強化學習和基於搜尋與監督的深度強化學習;其次對深度強化學習領域的一些前沿研究方向進行了綜述,包括

2.強化學習的基本概念
強 化 學 習 (Reinforcement Learning, RL) 作為機器學習領域另一個研究熱點,已經廣泛應用於工業製造、模擬模擬、機器人控制、優化與排程、遊戲博弈等領域.RL的基本思想是通過最大化智慧體(agent) 從環境中獲得的累計獎賞值,以學習到完成目標的最優策略。因此 RL 方法更加側重於學習解決問題的策略,被認為是邁向通用人工智慧(Artificial General Intelligence, AGI)的重要途徑
3.深度強化學習的應用
在 DRL 發展的最初階段, DQN 演算法主要被應用於 Atari 2600 平臺中的各類 2D 視訊遊戲中. 隨後,研究人員分別從演算法和模型兩方面對 DQN 進行了改進,使得 agent 在 Atari 2600 遊戲中的平均得分提高了 300%,並在模型中加入記憶和推理模組,成功地將 DRL 應用場景拓寬到 3D 場景下的複雜任務中. AlphaGo 圍棋演算法結合深度神經網路和MCTS,成功地擊敗了圍棋世界冠軍. 此外, DRL在機器人控制、計算機視覺、自然語言處理和醫療等領域的應用也都取得了一定的成功。
深度強化學習在機器人控制領域的應用:在 2D 和 3D 的模擬環境中, 基於策略梯度的DRL 方法(TRPO、 GAE、 SVG、 A3C 等) 實現了對機器人的行為控制. 另外, 在現實場景下的機器人控制任務中,DRL也取得了若干研究成果。
深度強化學習在計算機視覺領域的應用:基於視覺感知的 DRL 模型可以在只輸入原始影象的情況下,輸出當前狀態下所有可能動作的預測回報. 因此可以將 DRL 模型應用到基於動作條件的視訊預測(action-conditional video prediction)任務中。
深度強化學習在自然語言處理領域的應用:利用 DRL 中的策略梯度方法訓練對話模型,最終使模型生成更具連貫性、互動性和持續響應的一系列對話。
深度強化學習在引數優化中的應用:通過某種DRL學習機制,根據具體問題自動確定相應的學習率,將極大地提升模型的訓練效率,暫時還處於初步階段,例如谷歌利用 DRL 演算法來優化資料中心伺服器群的引數設定,並節省了 40%的電力能源.
深度強化學習在博弈論領域的應用:DRL 的不斷髮展為求解博弈論問題開闢了一條新的道路. 深度卷積網路具有自動學習高維輸入資料抽象表達的功能, 可以有效解決複雜任務中領域知識表示和獲取的難題. 目前,利用 DRL 技術來發展博弈論已經取得了不錯的研究成果。
4.DRL基本原理
DRL 是一種端對端(end-to-end) 的感知與控制系統,具有很強的通用性. 其學習過程可以描述為:

(1) 在每個時刻 agent與環境互動得到一個高維度的觀察,並利用 DL 方法來感知觀察, 以得到抽象、具體的狀態特徵表示;
(2) 基於預期回報來評價各動作的價值函式,並通過某種策略將當前狀態對映為相應的動作.
(3)環境對此動作做出反應,並得到下一個觀察. 通過不斷迴圈以上過程,最終可以得到實現目標的最優策略.
5.主要方法
- 基於值函式的深度強化學習
深度 Q 網路:Mnih等人將卷積神經網路與傳統 RL中的Q 學習演算法相結合, 提出了深度 Q 網路(Deep Q-Network, DQN)模型. 該模型用於處理基於視覺感知的控制任務,是 DRL 領域的開創性工作。

DQN 模型結構的改進:對 DQN 模型的改進一般是通過向原有網路中新增新的功能模組來實現的. 例如,可以向 DQN模型中加入迴圈神經網路結構,使得模型擁有時間軸上的記憶能力,比如基於競爭架構的 DQN 和深度迴圈 Q 網路(Deep Recurrent Q-Network,DRQN) .
競爭網路結構的模型則將 CNN 提取的抽象特徵分流到兩個支路中,其中一路代表狀態值函式,另一路代 表 依 賴 狀 態 的 動 作 優 勢 函 數 (advantagefunction) . 通過該種競爭網路結構, agent 可以在策略評估過程中更快地識別出正確的行為。

Hausknecht 等人利用迴圈神經網路結構來記憶時間軸上連續的歷史狀態資訊,提出了 DRQN 模型。在部分狀態可觀察的情況下, DRQN 表現出比 DQN 更好的效能. 因此 DRQN 模型適用於普遍存在部分狀態可觀察問題的複雜任務.
- 基於策略梯度的深度強化學習
在求解 DRL 問題時,往往第一選擇是採取基於策略梯度的演算法. 原因是它能夠直接優化策略的期望總獎賞,並以端對端的方式直接在策略空間中搜索最優策略,省去了繁瑣的中間環節. 因此與 DQN 及其改進模型相比, 基於策略梯度的 DRL 方法適用範圍更廣,策略優化的效果也更好。
策略梯度方法是一種直接使用逼近器來近似表示和優化策略,最終得到最優策略的方法. 該方法優化的是策略的期望總獎賞。
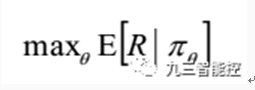
深度策略梯度方法的另一個研究方向是通過增加額外的人工監督來促進策略搜尋. 例如著名的 AlphaGo 圍棋機器人,先使用監督學習從人類專家的棋局中預測人類的走子行為, 再用策略梯度方法針對贏得圍棋比賽的真實目標進行精細的策略引數調整。然而在某些任務中是缺乏監督資料的,比如現實場景下的機器人控制, 可以通過引導式策略搜尋( guided policy search)方法來監督策略搜尋的過程. 在只接受原始輸入訊號的真實場景中,引導式策略搜尋實現了對機器人的操控。
Actor-Critic方法:在許多複雜的現實場景中,很難線上獲得大量訓練資料. 例如在真實場景下機器人的操控任務中,線上收集並利用大量訓練資料會產生十分昂貴的代價, 並且動作連續的特性使得線上抽取批量軌跡的方式無法達到令人滿意的覆蓋面. 以上問題會導致區域性最優解的出現. 針對此問題,可以將傳統 RL中的行動者評論家(Actor-Critic, AC) 框架拓展到深度策略梯度方法中.

非同步的優勢Actor-Critic演算法:Mnih 等人根據非同步強化學習(Asynchronous Reinforcement Learning, ARL) 的思想,提出了一種輕量級的 DRL 框架,該框架可以使用非同步的梯度下降法來優化網路控制器的引數,並可以結合多種 RL 演算法. 其中,非同步的優勢行動者評論家演算法(Asynchronous Advantage Actor-Critic, A3C) 在各類連續動作空間的控制任務上表現的最好。

- 基於搜尋與監督的深度強化學習
通過增加額外的人工監督來促進策略搜尋的過程,即為基於搜尋與監督的 DRL 的
核心思想. 蒙特卡洛樹搜尋(Monte Carlo Tree Search, MCTS)作為一種經典的啟發式策略搜尋方法,被廣泛用於遊戲博弈問題中的行動規劃. 因此在基於搜尋與監督的 DRL 方法中, 策略搜尋一般是通過 MCTS 來完成的。AlphaGo圍棋演算法將深度神經網路和 MCTS 相結合,並取得了卓越的成就。
結合深度神經網路和 MCTS:AlphaGo 的主要思想有兩點:
(1)使用 MCTS 來近似估計每個狀態的值函式;
(2)使用基於值函式的 CNN 來評估棋盤的當前佈局和走子.
AlphaGo 完整的學習系統主要由以下 4 個部分組成:
(1)策略網路(policy network) . 又分為監督學習的策略網路和 RL 的策略網路. 策略網路的作用是根據當前的局面來預測和取樣下一步走棋.
(2)滾輪策略(rollout policy) .目標也是預測下一步走子,但是預測的速度是策略網路的 1000倍.
(3)估值網路(value network) . 根據當前局面,估計雙方獲勝的概率.
(4) MCTS. 將策略網路、滾輪策略和估值網路融合進策略搜尋的過程中,以形成一個完整的系統
6.研究前沿
分層深度強化學習:利用分層強化學習(Hierarchical Reinforcement Learning,HRL)將最終目標分解為多個子任務來學習層次化的策略,並通過組合多個子任務的策略形成有效的全域性策略。
多工遷移深度強化學習:在傳統 DRL 方法中, 每個訓練完成後的 agent只能解決單一任務. 然而在一些複雜的現實場景中,需要 agent 能夠同時處理多個任務,此時多工學習和遷移學習就顯得異常重要.Wang 等人總結出 RL 中的遷移分為兩大類:行為上的遷移和知識上的遷移,這兩大類遷移也被廣泛應用於多工 DRL 演算法中。
多 agent 深度強化學習:在面對一些真實場景下的複雜決策問題時,單agent 系統的決策能力是遠遠不夠的.例如在擁有多玩家的 Atari 2600 遊戲中, 要求多個決策者之間存在相互合作或競爭的關係. 因此在特定的情形下,需要將 DRL 模型擴充套件為多個 agent 之間相互合作、通訊及競爭的多 agent 系統。
基於記憶與推理的深度強化學習:在解決一些高層次的 DRL 任務時, agent 不僅需要很強的感知能力,也需要具備一定的記憶與推理能力,才能學習到有效的決策. 因此賦予現有 DRL 模型主動記憶與推理的能力就顯得十分重要。
|引用文章:
劉全,翟建偉,章宗長,鍾珊,周倩,章鵬,徐進,深度強化學習綜述,2017, Vol.40,線上出版號 No.1
LIU Quan, ZHAI Jian-Wei, ZHANG Zong-Zhang, ZHONG Shan, ZHOU Qian, ZHANG Peng, XU Jin, A Survey on Deep Reinforcement
Learning, 2017,Vol.40,Online Publishing No.1