
強化學習介紹(RL)
一、簡介
機器學習有三大分支,監督學習、無監督學習和強化學習,強化學習是系統從環境學習以使得獎勵最大的機器學習。**人工智慧中稱之為強化學習,在控制論中被稱之為動態規劃,兩者在概念上是等價的。**也被翻譯為增強學習。
二、概念
- 不同於機器學習的其它兩個分支:
- 它不是無監督學習,因為有回報(Reward)訊號
- 反饋是延時的,而不是即時的
- 資料是與時間有關的序列
- 智慧體的動作與後續的資料有關
- 強化學習基於一種回報假設:
- 回報是標量反饋訊號
- 表明智慧體(Agent)在這步做得有多好
- 智慧體(Agent)的任務就是最大化累計回報
Reinforcement learning is learning what to do ----how to map situations to actions ---- so as to maximize a numerical reward signal.
強化學習關注的是智慧體如何在環境中採取一系列行為,從而獲得最大的累積回報。
- 連續決策(Sequential Decision Making):
- 目標:選擇一個Action儘量最大化將來的總回報
- Aciton可能有長期的影響
- 回報可能延時
- 犧牲即時回報去獲得更好的長期回報
金融投資就是一個這樣的過程。
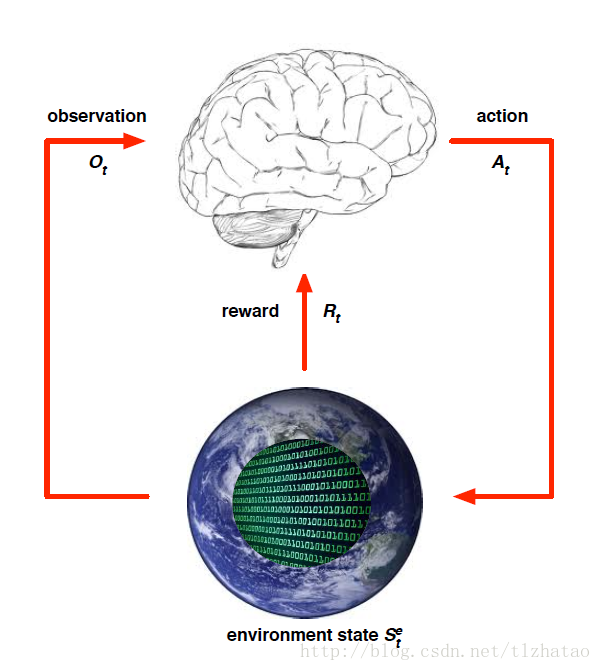
- 環境狀態(Environment State):
- Environment State是Environment私有的表達
- Environment利用這些資料尋找下個Observation或者Reward
- Environment State不總是對Agent可見的
- 即使Environment State是可見的,也有可能包含一些不相關的資訊
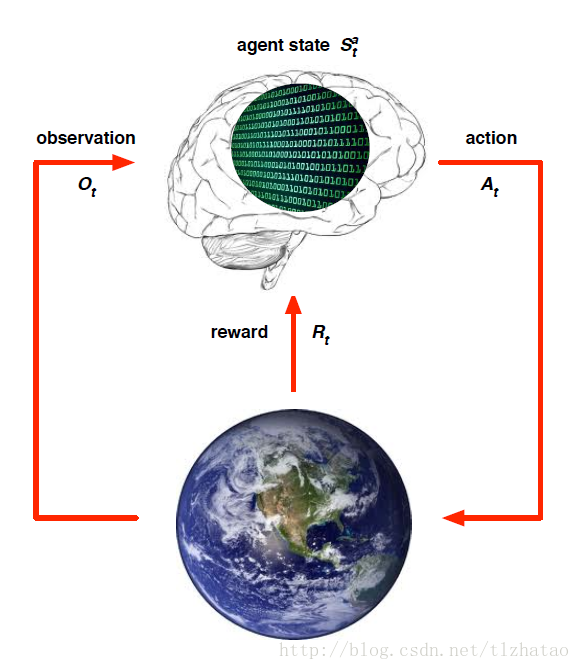
- 智慧體狀態(Agent State):
- Agent State是Agent的內在表達
- Agent用這些資訊尋找下個Action
- 這些資訊被用於強化學習演算法
- 資訊狀態(Information State):包含來自歷史記錄的所有有用的資訊,也稱之為Markov State
- 將來資訊獨立給定現在資訊的過去資訊
- 一旦狀態已知,歷史記錄就可以扔掉
- 這個狀態是將來的充要統計
- Environment State是Markov
- 歷史記錄也是Markov
- 完全可觀察的環境(Fully Observable Environments):Agent可以直接觀察到的Environment State
- Agent State = Environment State = Information State
- 這是一個Markov Decision Process
- 部分可觀察的環境(Partially Observable Environments)
- Agent不能直接觀察到Environment
- Agent State不等於Environment State
- 這是一個Partially Observable Markov Decision Process
- Agent必須建立自己的State表達自己
- 強化學習智慧體的主要元件(Major Components of an RL Agent):
- Policy:Agent的習慣函式
- Value Function:每個State或者Action的好壞
- Model:Agent的環境表達
- 策略(Policy):
- Policy是Agent的習慣表達
- State到Action的對映
- 確定策略
- 隨機策略
- 值函式(Value Function):
- Value Function是將來回報的預測
- 用於評估State的好壞
- 因此,可以用於動作間的選擇
- 模型(Model):
- Model預測下一步Environment做什麼
- 預測下個狀態
- 預測下個回報
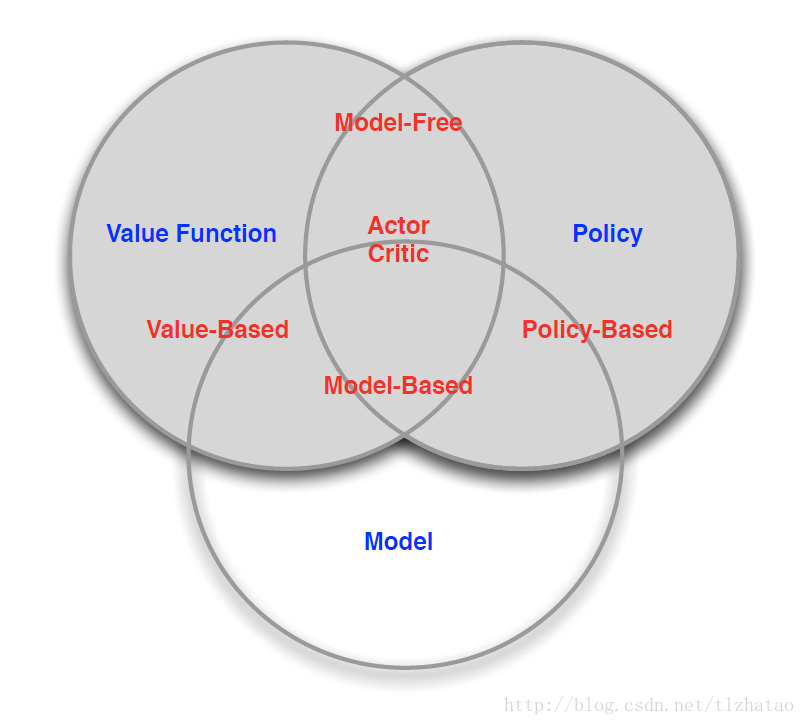
三、Agent的分類:
- Value Based:
- Value Function
- Policy Based:
- Policy
- Actor Critic:
- Policy
- Value Function
- Model Free:
- Policy或Value Function
- Model Based:
- Policy或Value Function
- Model
四、過程:
通過強化學習,一個智慧體(Agent)應該知道在什麼狀態(State)下應該採取什麼行為(Action),這個狀態從以獲取最大的回報(Reward)。強化學習是從環境狀態到動作的對映的學習,我們把這個對映稱之為策略(Policy)。
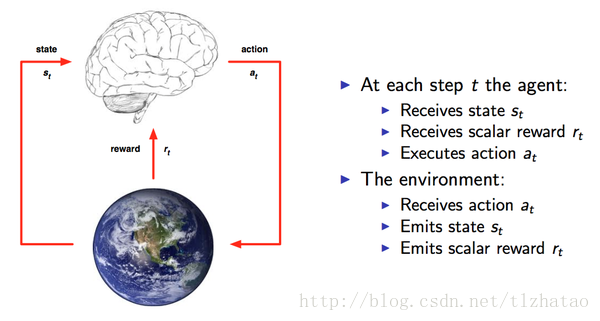
從David Silver的圖可以看出Agent和Environment之間的關係 ,每個時間點Agent都會根據上一刻的State,從可以選擇的動作集合中選擇一個動作a_t執行,這個動作集合可以是連續的,比如機器人的控制,也可以是離散的比如遊戲中的幾個按鍵,動作集合的數量將直接影響整個任務的求解難度,執行a_t後得到一個Reward。環境收到動作a_t,放出State和Reward。
Agent都是根據當前的State來確定下一步的動作。因此,狀態State和動作Action存在對映關係,也就是一個State可以對應一個Action,或者對應不同動作的概率(概率最高的就是最值得執行的動作)。狀態與動作的關係其實就是輸入與輸出的關係,而State到Action的過程就稱之為一個Policy。我們需要找到這樣一個Policy使得Reward最大。
五、例子
- 直升機特技飛行
- 機器人行走
- 戰勝棋類世界冠軍
- 玩遊戲比人類還要好

上圖是一個吃豆子游戲,迷宮的每一格就是一種State,Agent在每個State下,應該選擇上下左右這些Action,吃豆子會得到正的Reward,被吃掉則反之。而在每個State下會選擇哪一個Action則是Policy。
輸入是:
- State = Observation,例如迷宮的每一格是一個State
- Actions = 在每個狀態下,有什麼行動
- Reward = 進入每個狀態時,能帶來正面或負面的回報
輸出就是:
- Policy = 在每個狀態下,會選擇哪個行動
再詳細一點就是:
- State = 迷宮中Agent的位置,可以用一對座標表示,例如(1,3)
- Action = 在迷宮中每一格,你可以行走的方向,例如:{上,下,左,右}
- Reward = 當前的狀態 (current state) 之下,迷宮中的一格可能有食物 (+1) ,也可能有怪獸 (-100)
- Policy = 一個由狀態 → 行動的函式,即: 函式對給定的每一個狀態,都會給出一個行動
六、預測與控制
- Prediction:評估未來
- 給定Policy
- Control:優化未來
- 找到最好的Policy
七、一些問題
-
強化學習像一個嘗試-錯誤的學習
-
Agent發現一個最好的Policy
-
來自環境的經驗
-
在這條路上不要丟掉太多的Reward
-
探索尋找更多關於Environment的資訊
-
運用那些可以最大化Reward的資訊
-
探索和利用通常一樣重要
相關推薦
強化學習介紹(RL)
一、簡介 機器學習有三大分支,監督學習、無監督學習和強化學習,強化學習是系統從環境學習以使得獎勵最大的機器學習。**人工智慧中稱之為強化學習,在控制論中被稱之為動態規劃,兩者在概念上是等價的。**也被翻譯為增強學習。 二、概念 不同於機器學習的其它兩個分支:
強化學習介紹(Introduction to RL)
一、簡介 機器學習有三大分支,監督學習、無監督學習和強化學習,強化學習是系統從環境學習以使得獎勵最大的機器學習。人工智慧中稱之為強化學習,在控制論中被稱之為動態規劃,兩者在概念上是等價的。也被翻譯為增強學習。 二、概念 1.不同於機器學習的其它兩個分支: 它不是無
機器學習介紹(introduction)-讀書筆記-
就是 .net 一條直線 但我 $2 標簽 沒標簽 處理 概率 一,什麽是機器學習 第一個機器學習的定義來自於 Arthur Samuel。他定義機器學習為,在進行特定編程的情況下,給予計算機學習能力的領域。Samuel 的定義可以回溯到 50 年代,他編寫了
SLS機器學習介紹(02):時序聚類建模
文章系列連結 SLS機器學習介紹(01):時序統計建模 SLS機器學習介紹(02):時序聚類建模 SLS機器學習介紹(03):時序異常檢測建模 SLS機器學習介紹(04):規則模式挖掘 前言 第一篇文章SLS機器學習介紹(01):時序統計建模上週更新完,一下子炸出了很多潛伏的業
深度學習介紹(下)【Coursera deeplearning.ai 神經網路與深度學習】
1. shallow NN 淺層神經網路 2. 為什麼需要activation function? 如下圖所示,如果不用啟用函式,那麼我們一直都在做線性運算,對於複雜問題沒有意義。linear 其實也算一類啟用函式,但是一般只用在機器學習的迴歸問題,例如預測房價等。 3.
SLS機器學習介紹(03):時序異常檢測建模
文章系列連結 SLS機器學習介紹(01):時序統計建模 SLS機器學習介紹(02):時序聚類建模 SLS機器學習介紹(03):時序異常檢測建模 SLS機器學習介紹(04):規則模式挖掘 SLS機器學習最佳實戰:時序異常檢測和報警 摘要與背景 雖然計算機軟硬體的快速發展已
SLS機器學習介紹(01):時序統計建模
文章系列連結 SLS機器學習介紹(01):時序統計建模 SLS機器學習介紹(02):時序聚類建模 SLS機器學習介紹(03):時序異常檢測建模 SLS機器學習介紹(04):規則模式挖掘 SLS機器學習最佳實戰:時序異常檢測和報警 背景 時序資料是業務監控中最多方法,雙十
Udacity強化學習系列(二)—— 馬爾科夫決策過程(Markov Decision Processes)
說到馬爾科夫Markov,大家可能都不陌生,陌生的[連結往裡走](https://baike.baidu.com/item/%E9%A9%AC%E5%B0%94%E5%8F%AF%E5%A4%AB%E8
乾貨滿滿的深度強化學習綜述(中文)
乾貨滿滿的深度強化學習綜述(中文) https://mp.weixin.qq.com/s/HQStW2AW3UIZR1R-hvJ8AQ 0.來源說明 引用:深度強化學習綜述 作者:劉全,翟建偉,章宗長,鍾珊,周
SLS機器學習介紹(05):時間序列預測
00系列文章目錄 0.1 演算法原理目錄 SLS機器學習介紹(01):時序統計建模 SLS機器學習介紹(02):時序聚類建模 SLS機器學習介紹(03):時序異常檢測建模 SLS機器學習介紹(04):規則模式挖掘 SLS機器學習介紹(05):時間序列預測 0.2 演算法最佳實踐
強化學習系列(一):強化學習簡介
一、強化學習是什麼? 首先,我們思考一下學習本身,當一個嬰兒在玩耍時可能會揮舞雙手,左看右看,沒有人來指導他的行為,但是他和外界直接通過了感官進行連線。感知給他傳遞了外界的各種資訊,包括知識等。學習的過程貫穿著我們人類的一生,當我們開車或者說話時,都觀察了環境
深度學習介紹(四)卷積操作
接下來介紹一下,CNNs是如何利用空間結構減少需要學習的引數數目的 如果我們有一張1000x1000畫素的影象,有1百萬個隱層神經元,那麼他們全連線的話(每個隱層神經元都與影象的每一個畫素點相連),這樣就有1000x1000x1000000=10^12個連線,
深度學習介紹(一)Yann LeCun
作為人工智慧的一種形式,深度學習能夠更好地模仿人類大腦。之前還有很多人工智慧研究人員還在公開對該領域嗤之以鼻,而僅僅過了幾年,從谷歌、微軟,到百度、Twitter,深度學習已經開始蔓延到整個商業科技世界了。 很多科技巨頭正在挖掘一種特殊的深度學習,他們稱之為卷
強化學習系列(六):時間差分演算法(Temporal-Difference Learning)
一、前言 在強化學習系列(五):蒙特卡羅方法(Monte Carlo)中,我們提到了求解環境模型未知MDP的方法——Monte Carlo,但該方法是每個episode 更新一次(episode-by-episode)。本章介紹一種單步更新的求解環境模型未知M
強化學習系列(五):蒙特卡羅方法(Monte Carlo)
一、前言 在強化學習系列(四):動態規劃中,我們介紹了採用DP (動態規劃)方法求解environment model 已知的MDP(馬爾科夫決策過程),那麼當environment model資訊不全的時候,我們會採用什麼樣的方法求解呢?蒙特卡洛方法(Mon
DQN(Deep Q-learning)入門教程(一)之強化學習介紹
## 什麼是強化學習? 強化學習(Reinforcement learning,簡稱RL)是和監督學習,非監督學習並列的第三種機器學習方法,如下圖示: 概率與數理統計
特征 數字特征 抽樣分布 第5章 最大 中心 3.4 獨立 知識 第1章 隨機事件與概率§1.1 隨機事件§1.2 隨機事件的概率§1.3 古典概型與幾何概型§1.4 條件概率§1.5 事件的獨立性 第2章 隨機變量的分布與數字特征§2.1 隨機變量及其分布§2.2 隨機變
bootstrap 學習筆記(1)---介紹bootstrap和柵格系統
優先 cal 圖片 應用 尺寸 文件中 lin png ice 學習前端許久,對於布置框架和響應瀏覽器用html 和javascript 寫的有點繁瑣,無意間看到這個框架,覺得挺好用的就開始學習了,但是這個框架上面有很多知識,不是所有的都要學的,故將學習筆記和覺得重點的
Nordic nRF52832 學習筆記(1) 介紹,入門,與準備工作
例程 盜版 path pdf 規範 準備 但是 依然 可能 近來,物聯網已成為大勢所趨,VR與AR正方興未艾,各種手環、遙控、智能家居也在粉墨登場。技術前沿的領航者們已經快馬加鞭,各種意誌與暗示也在上傳下達。物聯網,無線通訊,移動互聯,將成為新的目標與寵兒。最近開的電賽
RabbitMQ學習系列(一): 介紹
ref 原理 二維碼 host 屬性 訂閱 什麽 設計 發的 1. 介紹 RabbitMQ是一個由erlang開發的基於AMQP(Advanced Message Queue )協議的開源實現。用於在分布式系統中存儲轉發消息,在易用性、擴展性、高可用性等方面都非