
Deeplearning.ai吳恩達筆記之神經網路和深度學習1
Introduction to Deep Learning
What is a neural neural network?
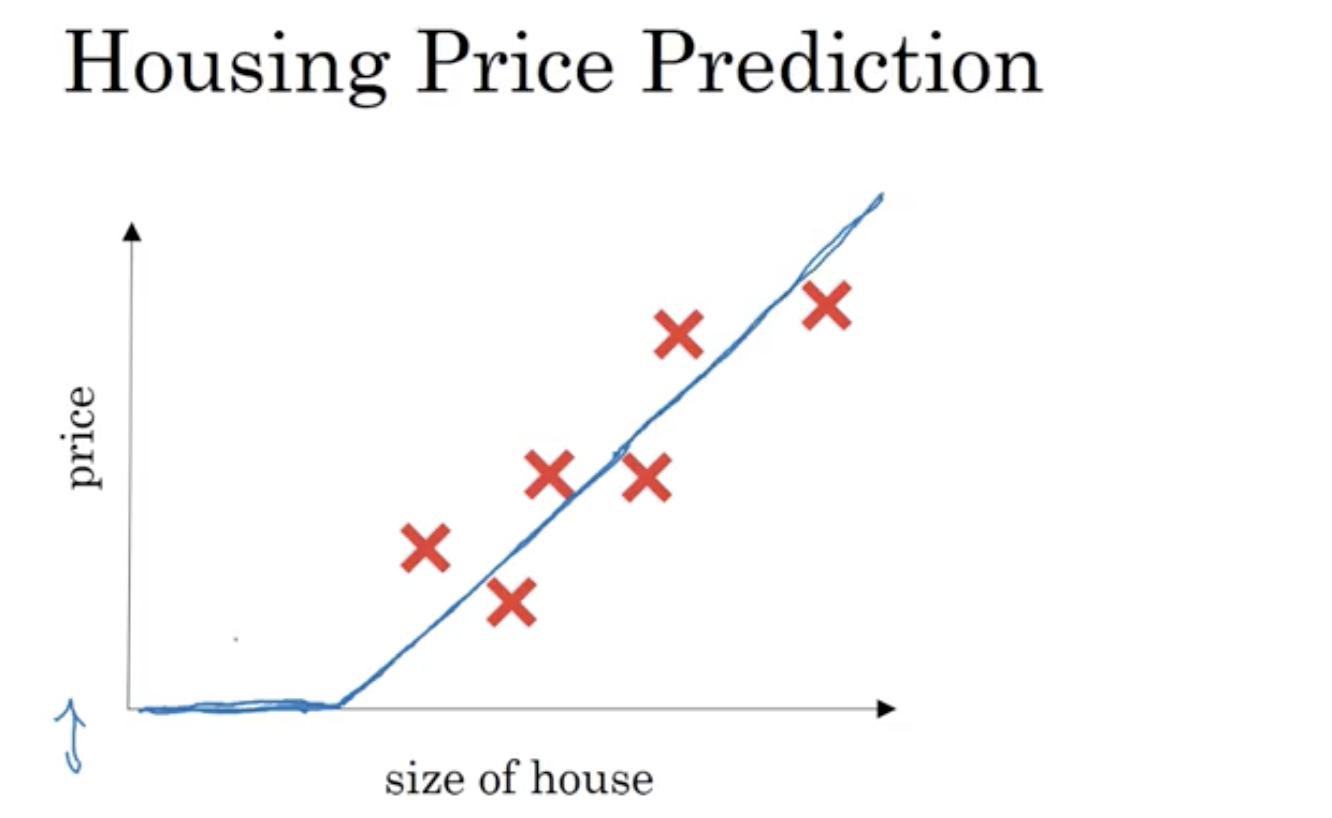
當對於房價進行預測時,因為我們知道房子價格是不可能會有負數的,因此我們讓面積小於某個值時,價格始終為零。
其實對於以上這麼一個預測的模型就可以看作是一個簡單的神經網路了。
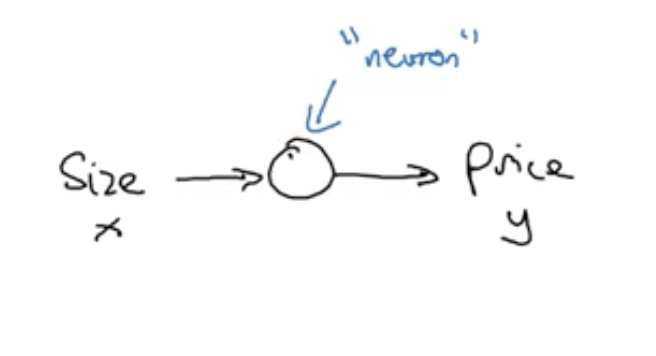
輸入x:房屋面積,輸出y是房屋價格,中間包含了一個神經元,該神經元其實就是實現了函式的功能。
值得一提的是,上圖神經元的預測函式(藍色折線)在神經網路應用中比較常見。我們把這個函式稱為ReLU函式,即線性整流函式(Rectified Linear Unit),形如下圖所示:
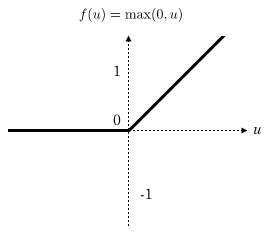
那麼上述所示是一個簡單的神經網路,那麼尋常的神經網路往往由許多神經元組成。
那麼我們嘗試使用更多的x來組建一個複雜一點的神經網路。
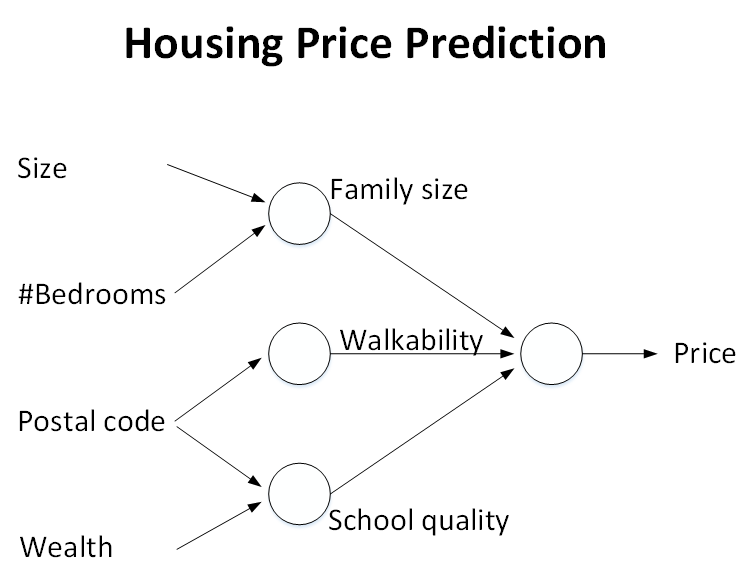
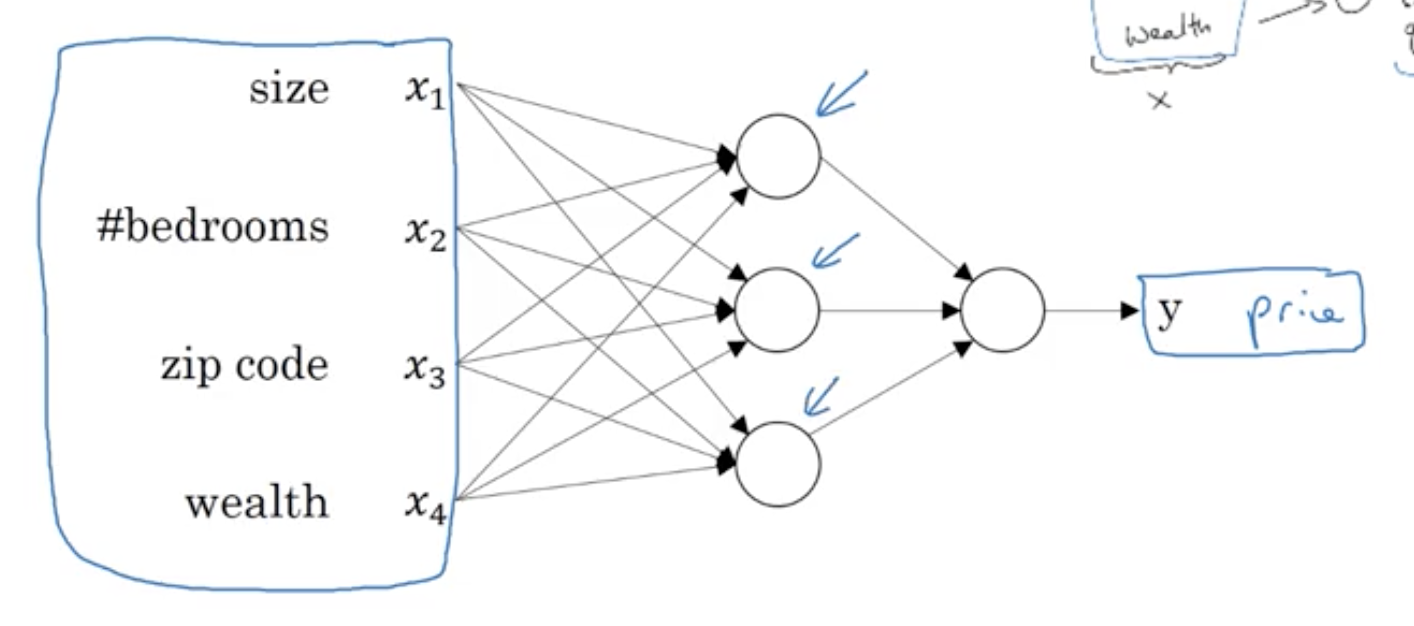
所以,在這個例子中,x是size,#bedrooms,zip code/postal code和wealth這四個輸入;y是房屋的預測價格。這個神經網路模型包含的神經元個數更多一些,相對之前的單個神經元的模型要更加複雜。那麼,在建立一個表現良好的神經網路模型之後,在給定輸入x時,就能得到比較好的輸出y,即房屋的預測價格。
實際上,上面這個例子真正的神經網路模型結構如下所示。它有四個輸入,分別是size,#bedrooms,zip code和wealth。在給定這四個輸入後,神經網路所做的就是輸出房屋的預測價格y。圖中,三個神經元所在的位置稱之為中間層或者隱藏層(x所在的稱之為輸入層,y所在的稱之為輸出層),每個神經元與所有的輸入x都有關聯(直線相連)。
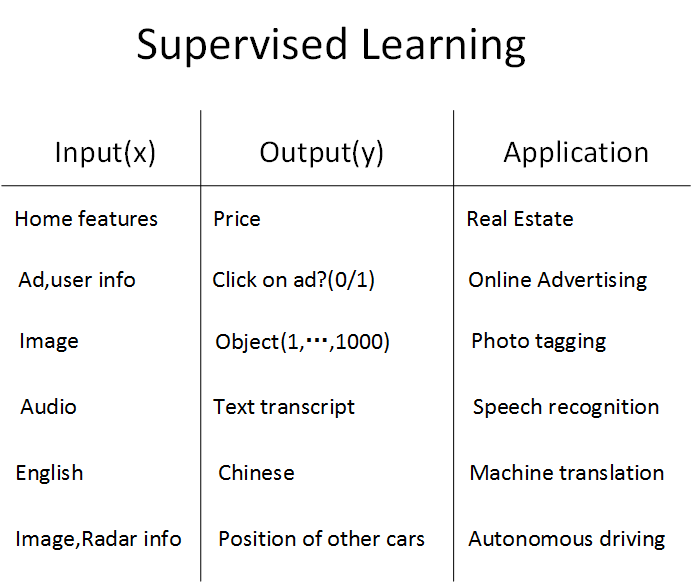
###Supervised Learning with Neural Networks
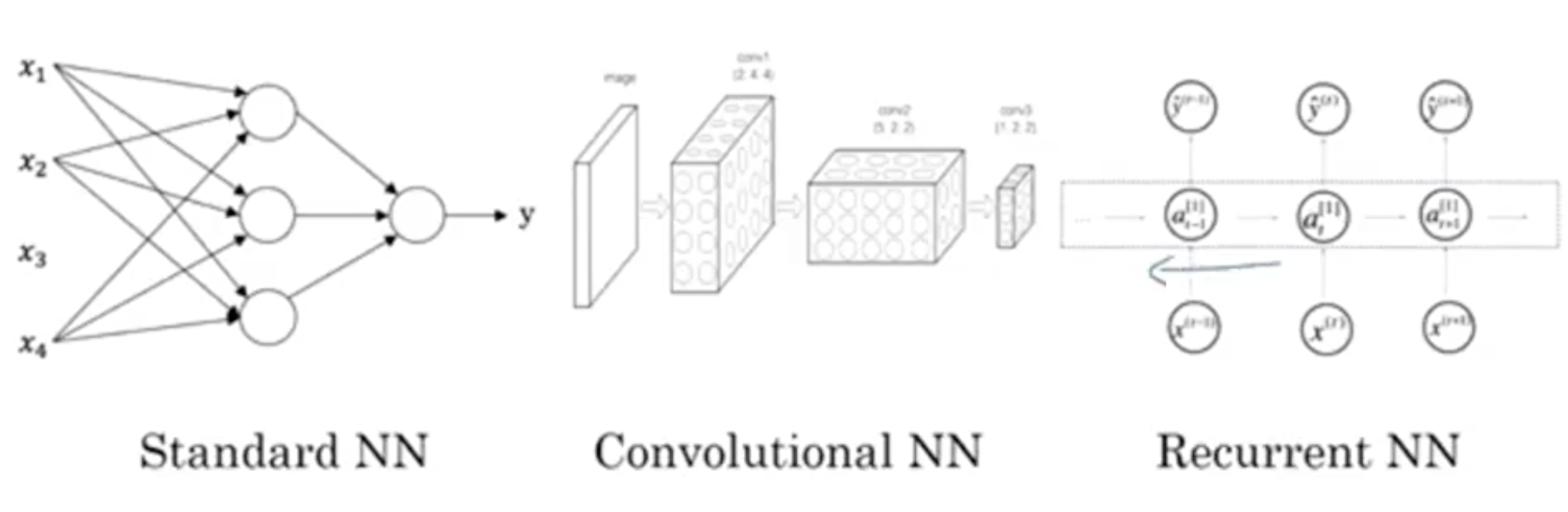
我們應該知道,根據不同的問題和應用場合,應該使用不同型別的神經網路模型。例如上面介紹的幾個例子中,對於一般的監督式學習(房價預測和線上廣告問題),我們只要使用標準的神經網路模型就可以了。而對於影象識別處理問題,我們則要使用卷積神經網路(Convolution Neural Network),即CNN。而對於處理類似語音這樣的序列訊號時,則要使用迴圈神經網路(Recurrent Neural Network),即RNN。還有其它的例如自動駕駛這樣的複雜問題則需要更加複雜的混合神經網路模型。
對應的NN模型如下:
另外,資料型別一般分為兩種:Structured Data和Unstructured Data。
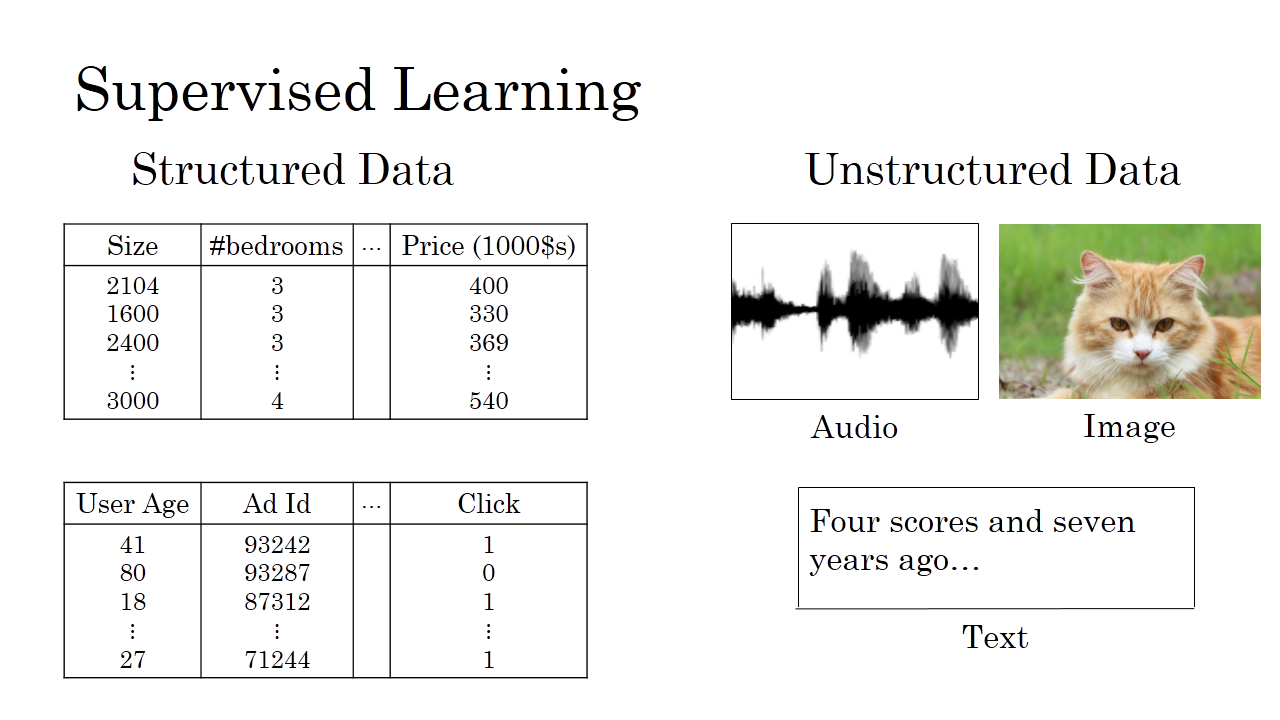
簡單地說,Structured Data通常指的是有實際意義的資料。例如房價預測中的size,#bedrooms,price等;例如線上廣告中的User Age,Ad ID等。這些資料都具有實際的物理意義,比較容易理解。而Unstructured Data通常指的是比較抽象的資料,例如Audio,Image或者Text。以前,計算機對於Unstructured Data比較難以處理,而人類對Unstructured Data卻能夠處理的比較好,例如我們第一眼很容易就識別出一張圖片裡是否有貓,但對於計算機來說並不那麼簡單。現在,值得慶幸的是,由於深度學習和神經網路的發展,計算機在處理Unstructured Data方面效果越來越好,甚至在某些方面優於人類。總的來說,神經網路與深度學習無論對Structured Data還是Unstructured Data都能處理得越來越好,並逐漸創造出巨大的實用價值。我們在之後的學習和實際應用中也將會碰到許多Structured Data和Unstructured Data。
Why is Deep Learning taking off?
深度學習為什麼這麼強大?下面我們用一張圖來說明。如下圖所示,橫座標x表示資料量(Amount of data),縱座標y表示機器學習模型的效能表(Performance)。
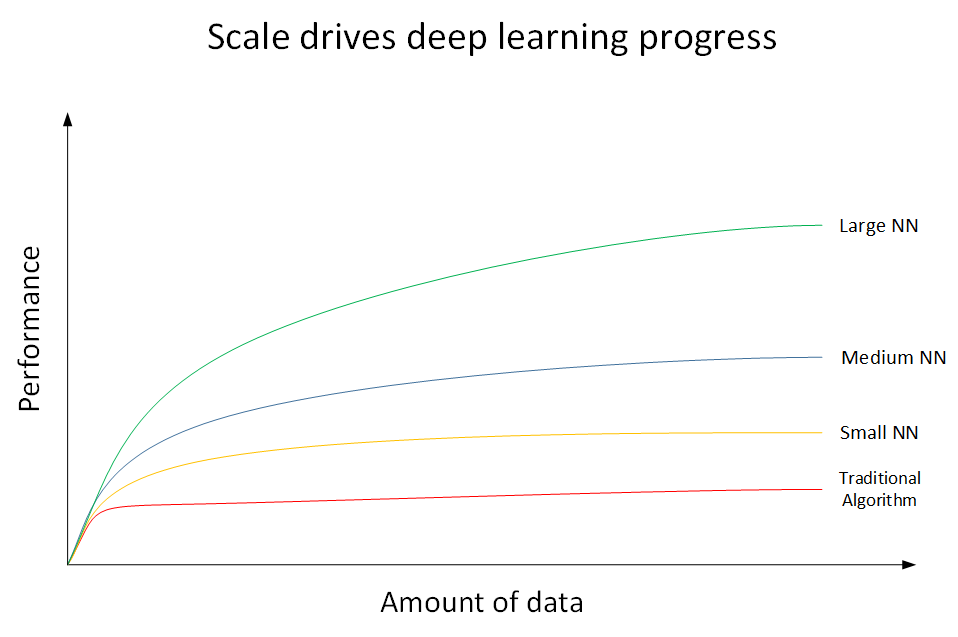
上圖共有4條曲線。其中,最底下的那條紅色曲線代表了傳統機器學習演算法的表現,例如是SVM,logistic regression,decision tree等。當資料量比較小的時候,傳統學習模型的表現是比較好的。但是當資料量很大的時候,其表現很一般,效能基本趨於水平。紅色曲線上面的那條黃色曲線代表了規模較小的神經網路模型(Small NN)。它在資料量較大時候的效能優於傳統的機器學習演算法。黃色曲線上面的藍色曲線代表了規模中等的神經網路模型(Media NN),它在在資料量更大的時候的表現比Small NN更好。最上面的那條綠色曲線代表更大規模的神經網路(Large NN),即深度學習模型。從圖中可以看到,在資料量很大的時候,它的表現仍然是最好的,而且基本上保持了較快上升的趨勢。值得一提的是,近些年來,由於數字計算機的普及,人類進入了大資料時代,每時每分,網際網路上的資料是海量的、龐大的。如何對大資料建立穩健準確的學習模型變得尤為重要。傳統機器學習演算法在資料量較大的時候,效能一般,很難再有提升。然而,深度學習模型由於網路複雜,對大資料的處理和分析非常有效。所以,近些年來,在處理海量資料和建立複雜準確的學習模型方面,深度學習有著非常不錯的表現。然而,在資料量不大的時候,例如上圖中左邊區域,深度學習模型不一定優於傳統機器學習演算法,效能差異可能並不大。
所以說,現在深度學習如此強大的原因歸結為三個因素:
-
Data
-
Computation
-
Algorithms
其中,資料量的幾何級數增加,加上GPU出現、計算機運算能力的大大提升,使得深度學習能夠應用得更加廣泛。另外,演算法上的創新和改進讓深度學習的效能和速度也大大提升。舉個演算法改進的例子,之前神經網路神經元的啟用函式是Sigmoid函式,後來改成了ReLU函式。之所以這樣更改的原因是對於Sigmoid函式,在遠離零點的位置,函式曲線非常平緩,其梯度趨於0,所以造成神經網路模型學習速度變得很慢。然而,ReLU函式在x大於零的區域,其梯度始終為1,儘管在x小於零的區域梯度為0,但是在實際應用中採用ReLU函式確實要比Sigmoid函式快很多。
構建一個深度學習的流程是首先產生Idea,然後將Idea轉化為Code,最後進行Experiment。接著根據結果修改Idea,繼續這種Idea->Code->Experiment的迴圈,直到最終訓練得到表現不錯的深度學習網路模型。如果計算速度越快,每一步驟耗時越少,那麼上述迴圈越能高效進行。
Summary
本節課的內容比較簡單,主要對深度學習進行了簡要概述。首先,我們使用房價預測的例子來建立最簡單的單個神經元組成的神經網路模型。然後,我們將例子複雜化,建立標準的神經網路模型結構。接著,我們從監督式學習入手,介紹了不同的神經網路型別,包括Standard NN,CNN和RNN。不同的神經網路模型適合處理不同型別的問題。對資料集本身來說,分為Structured Data和Unstructured Data。近些年來,深度學習對Unstructured Data的處理能力大大提高,例如影象處理、語音識別和語言翻譯等。最後,我們用一張對比圖片解釋了深度學習現在飛速發展、功能強大的原因。歸納其原因包含三點:Data,Computation和Algorithms。