
Hadoop全生態搭建日誌 四
阿新 • • 發佈:2018-12-21
Spark分散式叢集環境搭建
安裝spark
- 在MASTER節點上訪問Spark官網下載地址:
http://spark.apache.org/downloads.html - 解壓至指定資料夾,/usr/local/
配置環境變數
修改環境變數檔案
vim ~/.bashrc
新增
export SPARK_HOME=/usr/local/spark
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
生效修改
source ~/.bashrc
Spark配置
- 將slaves.template 檔案重新命名為slaves
修改內容,新增子節點名稱
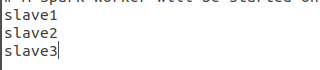
- 將spark-env.sh.template 檔案重新命名為spark-env.sh
修改內容,新增
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64 export HADOOP_HOME=/usr/local/hadoop export HADOOP_CONF=/usr/local/hadoop/etc/hadoop export SPARK_WORKER_MEMORY=2g export SPRK_WORKER_CORES=1 export SPARK_MASTER_IP=Master export SPARK_DIST_CLSSPATH=$(/usr/local/hadoop/etc/hadoop classpath) export SPARK_WORKER_INSTANCES=1
注: SPARK_MASTER_IP是繫結主節點ip地址,本文中的master就是主節點的地址,可在/etc/hosts 檔案中新增

完成配置 分發給子節點
在啟動好HADOOP集群后
cd /usr/local/spark
sbin/start-all.sh