
Hadoop HDFS搭建日誌
目錄
作業系統:Ubuntu16.04 Server
HDFS叢集搭建
閱讀:https://blog.csdn.net/boori/article/details/81021191
主要參考:https://www.cnblogs.com/caiyisen/p/7373512.html
VMware自帶的克隆,能克隆出三臺一模一樣的虛擬機器
當前環境:
Ubuntu16.04
java version "1.8.0_171"
先總的看一下所有的步驟:
一、配置hosts檔案
二、建立hadoop執行帳號
三、配置ssh免密碼連入
四、下載並解壓hadoop安裝包
五、配置 /etc/hadoop目錄下的幾個檔案及 /etc/profile
六、格式化namenode並啟動叢集
一、配置hosts檔案
現對虛擬機器主機名進行修改,來進行區分一個主節點和兩個從節點。
修改只讀檔案許可權:sudo chmod a+w test.c
接下來,分別檢視三臺虛擬機器的ip地址
inet addr
10.2.68.104
10.2.68.101
10.2.68.100
主機1改成了Hadoop1Server_master
將三臺虛擬機器的ip地址和主機名加在裡面,其它的不用動它。
三臺虛擬機器都要修改hosts檔案。簡單的說配置hosts後三臺虛擬機器就可以進行通訊了,可以互相ping一下試試,是可以ping通的。
sudo vim /etc/hosts
| 127.0.0.1 localhost 10.2.68.104 Hadoop1Server 10.2.68.101 Hadoop2Server 10.2.68.100 Hadoop3Server 10.2.68.99 Hadoop4Server 10.2.68.98 Hadoop5Server
# The following lines are desirable for IPv6 capable hosts ::1 localhost ip6-localhost ip6-loopback ff02::1 ip6-allnodes ff02::2 ip6-allrouters |
二、建立hadoop執行帳號
就是建立一個group組,然後在三臺虛擬機器上重新建立新的使用者,將這三個使用者都加入到這個group中。
以下操作三臺虛擬機器都要進行相同操作:
首先新增一個叫hadoop使用者組進來
sudo groupadd hadoop
cat /etc/group
新增名叫hduser的使用者,並新增到hadoop組中
sudo useradd -s /bin/bash -d /home/hduser -m hduser -g hadoop
賦予許可權
sudo adduser hduser sudo
更改其他使用者密碼,只要輸入passwd username
sudo passwd hduser
密碼:123456
切換到剛剛新建的使用者進行操作
su hduser
三、配置ssh免密碼連入
開始配置ssh之前,先確保三臺機器都裝了ssh。
輸入以下命令檢視安裝的ssh。
dpkg --list|grep ssh
機器顯示如下則正常:
ii openssh-client 1:7.2p2-4ubuntu2.6 amd64 secure shell (SSH) client, for secure access to remote machines
ii openssh-server 1:7.2p2-4ubuntu2.6 amd64 secure shell (SSH) server, for secure access from remote machines
ii openssh-sftp-server 1:7.2p2-4ubuntu2.6 amd64 secure shell (SSH) sftp server module, for SFTP access from remote machines
ii ssh-import-id 5.5-0ubuntu1 all securely retrieve an SSH public key and install it locally
(如果缺少了opensh-server,需要進行安裝:sudo apt-get install openssh-server)
安裝完畢之後開始配置ssh
接下來的這第三個步驟的操作請注意是在哪臺主機上進行,不是在三臺上同時進行。
(1)下面的操作在master機上操作
首先在master機上輸入以下命令,生成master機的一對公鑰和私鑰:
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
警告:公鑰私鑰已存在
/home/user/.ssh/id_rsa already exists.
Overwrite (y/n)? nn
以下命令進入認證目錄可以看到, id_rsa 和 id_rsa.pub這兩個檔案,就是我們剛剛生成的公鑰和私鑰。
Cd .ssh
Ls
然後,下面的命令將公鑰加入到已認證的key中:
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
再次進入生成目錄,可以看到多出authorized_keys這個檔案:
cd .ssh
ls
顯示:
authorized_keys id_rsa id_rsa.pub known_hosts
然後輸入ssh localhost 登入本機命令,第一次提示輸入密碼,輸入exit退出,再次輸入ssh localhost不用輸入密碼就可以登入本機成功,則本機ssh免密碼登入已經成功。
Exit退出登入
配置node1和node2節點的ssh免密碼登入,目的是讓master主機可以不用密碼登入到node1和node2主機。
(2)這一步分別在node1和node2主機上操作:
將master主機上的is_dsa.pub複製到node1主機上,命名為node1_dsa.pub。node2主機進行同樣的操作。
XShell與Windows互傳檔案:https://blog.csdn.net/u010710198/article/details/21187809
Linux:scp命令用於Linux之間複製檔案和目錄:http://www.runoob.com/linux/linux-comm-scp.html
scp [可選引數] file_source file_target
從遠端複製到本地,只要將從本地複製到遠端的命令的後2個引數調換順序即可,如下例項
scp [email protected]:/home/root/others/music /home/space/music/1.mp3
| 目前ssh Hadoop3Server顯示: Warning: the RSA host key for 'hadoop3server' differs from the key for the IP address '10.2.68.100' Offending key for IP in /home/user/.ssh/known_hosts:3 Matching host key in /home/user/.ssh/known_hosts:11 用root連: The authenticity of host 'hadoop3server (10.2.68.100)' can't be established. RSA key fingerprint is SHA256:7betrMgjuO3Owd03sMKOpovJt7xMXD7VIn3BQpWewKo. Warning: Permanently added 'hadoop3server,10.2.68.100' (RSA) to the list of known hosts Permission denied (publickey,gssapi-keyex,gssapi-with-mic,password). |
遠端主機:後無空格

[email protected]:~$ scp [email protected]:~/.ssh/id_rsa.pub ~/.ssh/Hadoop3Server_rsa.pub
| 顯示: id_rsa.pub 100% 400 0.4KB/s 00:00 |
將從master得到的金鑰加入到認證,node2主機進行同樣的操作。
把id_rsa.pub追加到授權的key裡面去。

cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
cat ~/.ssh/Hadoop3Server_rsa.pub >> ~/.ssh/authorized_keys
然後開始驗證是不是已經可以進行ssh免密碼登入。
(3)在master機上進行驗證
同樣第一次需要密碼,之後exit退出,再ssh node1就不需要密碼登入成功,說明ssh免密碼登入配置成功!
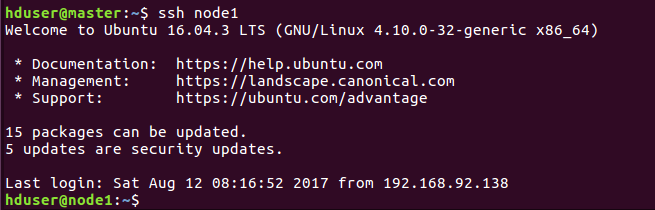
如果失敗了,可能是前面的認證沒有認證好,可以將.ssh目錄下的金鑰都刪了重新生成和配置一遍。或者檢查下hosts檔案ip地址寫的對不對。
此處免密登入為ssh Hadoop2Server等
更新known_hosts updated
報錯:
| RSA host key for hadoop3server has changed and you have requested strict checking. Host key verification failed. |
解決:ssh-keygen -R hadoop3server
https://blog.csdn.net/github_38236333/article/details/78335903
之後顯示
| The authenticity of host 'hadoop3server (10.2.68.100)' can't be established. ECDSA key fingerprint is SHA256:lEys3rUjbFGXlkOctNUiJdNTi/TRb/9O6YMxqU5PcIo. Are you sure you want to continue connecting (yes/no)? yes 成功登入 |
四、下載並解壓hadoop安裝包
版本:Hadoop2.6.0 (下載地址:http://mirrors.hust.edu.cn/apache/hadoop/common/)
建議初學者選擇2.6.0或者2.7.0版本就可以了,而且如果後面要配置Eclipse開發環境的話,這兩個版本的外掛很容易找到,不用自己去編譯。
話不多說,將hadoop壓縮包,解壓到一個資料夾裡面,例子這裡解壓到了home資料夾,並修改資料夾名為hadoop2.6。所在的目錄就是/home/hduser/hadoop2.6
三臺主機都要解壓到相應位置
本地為Hadoop 2.7.6
五、配置 /etc/hadoop目錄下的幾個檔案及 /etc/profile
主要有這5個檔案需要修改:
~/etc/hadoop/hadoop-env.sh
~/etc/hadoop/core-site.xml
~/etc/hadoop/hdfs-site.xml
~/etc/hadoop/mapred-site.xml
~/etc/hadoop/slaves
/etc/profile
三臺機都要進行這些操作,可以先在一臺主機上修改,修改完了複製到其它主機就可以了。
首先是hadoop-env.sh ,新增java安裝的地址,儲存退出即可。
問題:~/etc/hadoop/hadoop-env.sh不存在,是新建檔案。
在home下檢視hadoop資料夾,找到自己的路徑
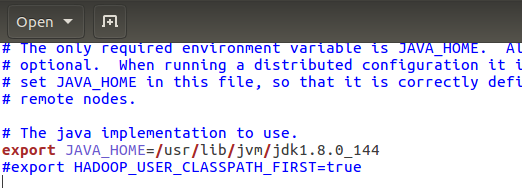
然後core-site.cml
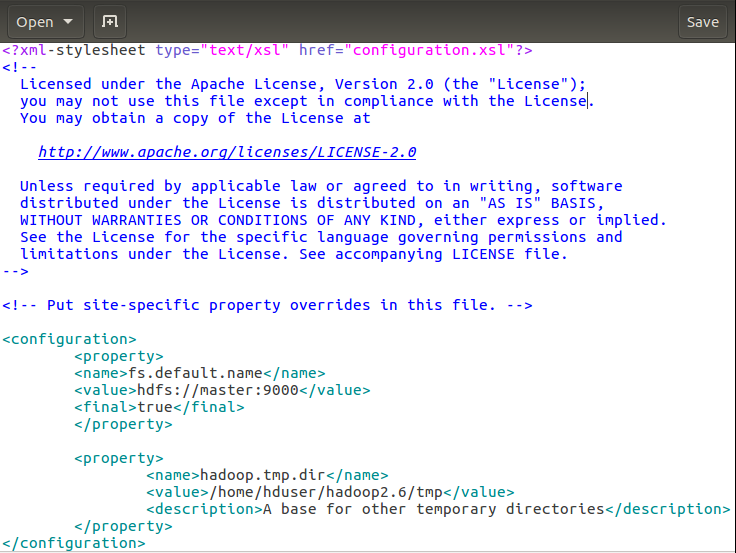
解釋下:第一個fs.default.name設定master機為namenode 第二個hadoop.tmp.dir配置Hadoop的一個臨時目錄,用來存放每次執行的作業jpb的資訊。
接下來hdfs-site.xml的修改:
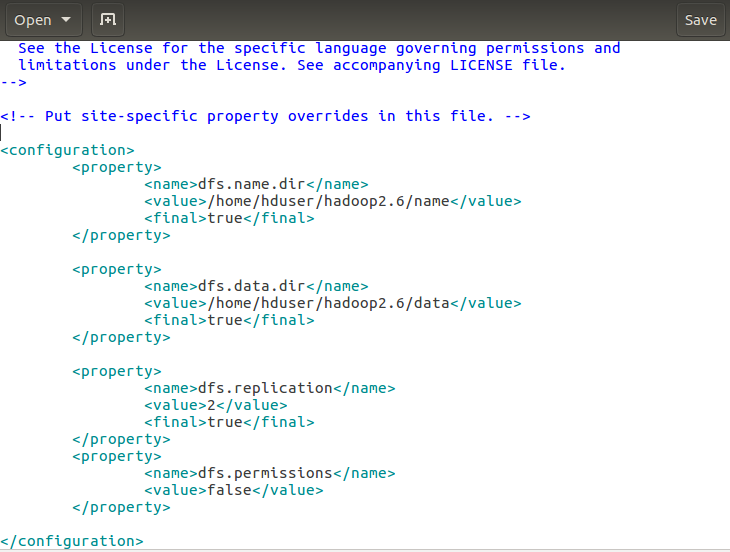
解釋下:dfs.name.dir是namenode儲存永久性的元資料的目錄列表。這個目錄會建立在master機上。dfs.data.dir是datanode存放資料塊的目錄列表,這個目錄在node1和node2機都會建立。 dfs.replication 設定檔案副本數,這裡兩個datanode,所以設定副本數為2。
接下來mapred-site.xml的修改:
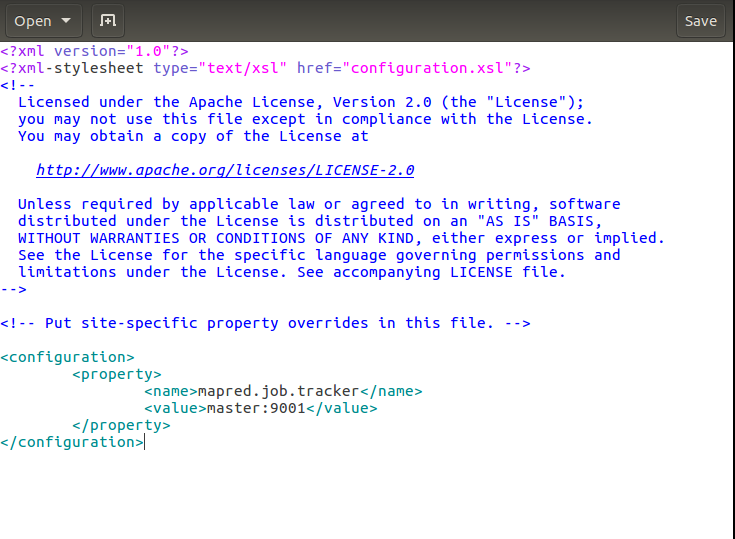
解釋下:這裡設定的是執行jobtracker的伺服器主機名和埠,也就是作業將在master主機的9001埠執行。
接下來修改slaves檔案
教程:~/etc/hadoop/slaves
本地:~/hadoop/etc/hadoop/slaves

這裡將兩臺從主機的主機名node1和node2加進去就可以了。
| 原為: Hadoop3Server Hadoop4Server Hadoop5Server |
| 改為: Hadoop2Server Hadoop3Server |
最後修改profile檔案 ,如下進入profile:

將這幾個路徑新增到末尾:

修改完讓它生效:

檢查下是否可以看到hadoop版本資訊
顯示出了版本資訊,如果沒有顯示出來,回過去檢查 profile路徑是否填寫錯誤。
顯示版本資訊如下
[email protected]:~$ hadoop version
Hadoop 2.7.6
Subversion https://[email protected]/repos/asf/hadoop.git -r 085099c66cf28be31604560c376fa282e69282b8
Compiled by kshvachk on 2018-04-18T01:33Z
Compiled with protoc 2.5.0
From source with checksum 71e2695531cb3360ab74598755d036
This command was run using /home/user/hadoop/share/hadoop/common/hadoop-common-2.7.6.jar
六、格式化namenode並啟動叢集
接下來需要格式化namenode,注意只需要在 master主機上進行格式化。格式化命令如下:

看到successful表示格式化成功。
接下來啟動叢集:

啟動完畢,檢查下啟動情況: master主機看到四個開啟的程序,node1和node2看到三個開啟的程序表示啟動成功。


[email protected]:~$ start-all.sh
報錯:指令碼已經棄用
This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh
第二次嘗試
start-dfs.sh
報錯:剛剛已經啟動叢集還未停止、佔用程序
Hadoop 啟動/停止叢集和節點的命令
啟動/停止Hadoop叢集:start-all.sh stop-all.sh
[email protected]:~$ stop-all.sh
This script is Deprecated. Instead use stop-dfs.sh and stop-yarn.sh
修復:
https://blog.csdn.net/violet_echo_0908/article/details/53486317
此處如上警告提示為/home/user/.ssh/known_hosts
看不懂,且無法通過vim修改
Add correct host key in /home/user/.ssh/known_hosts
未嘗試重新複製公鑰:
~/.ssh/is_dsa.pub ~/.ssh/Hadoop3Server_dsa.pub
清除舊的公鑰資訊
ssh-keygen -R 10.2.68.104
顯示:
/home/user/.ssh/known_hosts updated.
Original contents retained as /home/user/.ssh/known_hosts.old
ssh免驗證登入
https://blog.csdn.net/qq_38570571/article/details/79268426
ssh-keygen -f "/home/user/.ssh/known_hosts" -R hadoop3server
| 成功啟動顯示 [email protected]:~$ start-dfs.sh Starting namenodes on [Hadoop1Server] Hadoop1Server: starting namenode, logging to /home/user/hadoop/logs/hadoop-user-namenode-Hadoop1Server.out Hadoop3Server: starting datanode, logging to /home/user/hadoop/logs/hadoop-user-datanode-Hadoop3Server.out Hadoop5Server: starting datanode, logging to /home/user/hadoop/logs/hadoop-user-datanode-Hadoop5Server.out Hadoop4Server: starting datanode, logging to /home/user/hadoop/logs/hadoop-user-datanode-Hadoop4Server.out Starting secondary namenodes [Hadoop2Server] Hadoop2Server: starting secondarynamenode, logging to /home/user/hadoop/logs/hadoop-user-secondarynamenode-Hadoop2Server.out |