
spark-streaming 程式設計(二) word count單詞計數統計
就那官方的例子來說明,程式碼基本上有註釋
package com.lgh.sparkstreaming
import org.apache.spark.SparkConf
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* Created by Administrator on 2017/8/22.
*/
object NetworkWordCount {
def main(args: Array[String]) {
if 程式執行方法:
在linux主機192.168.53.100上執行 nc -lk 9999(有不明白的大家可以百度下nc的用法)然後開始輸入單詞。
在idea中傳入引數192.168.53.100 9999,開始執行。
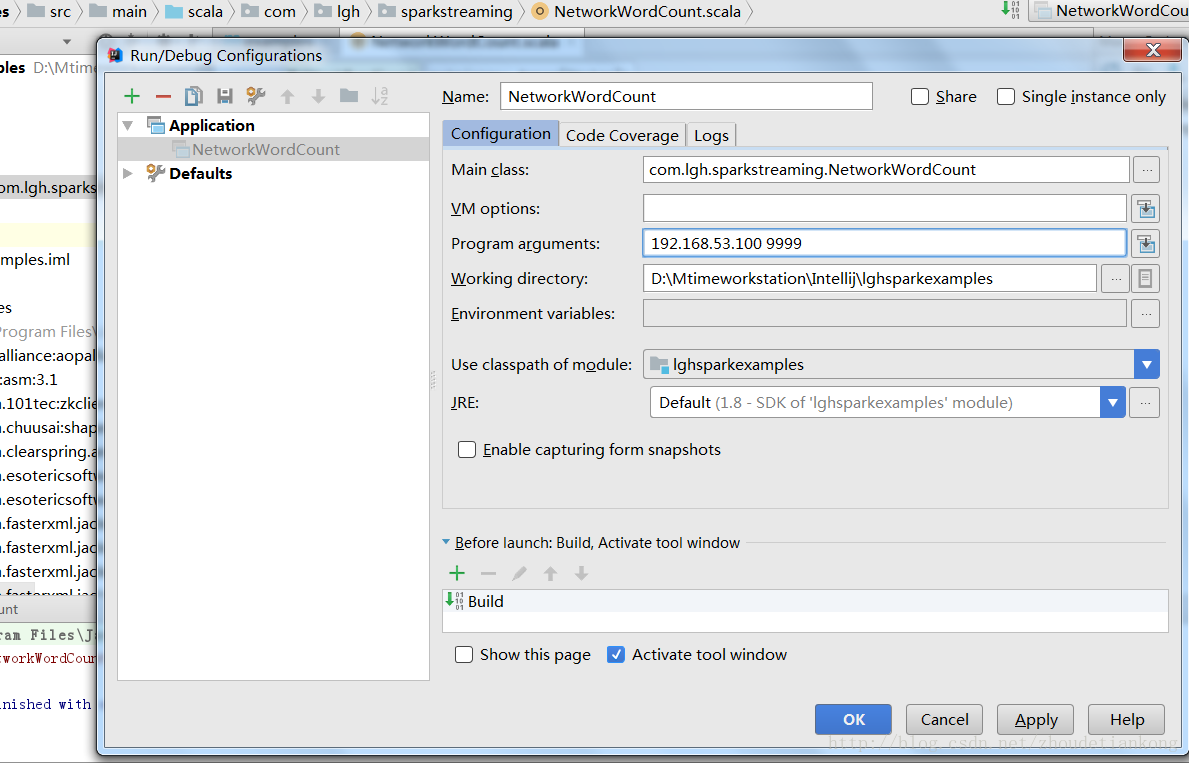
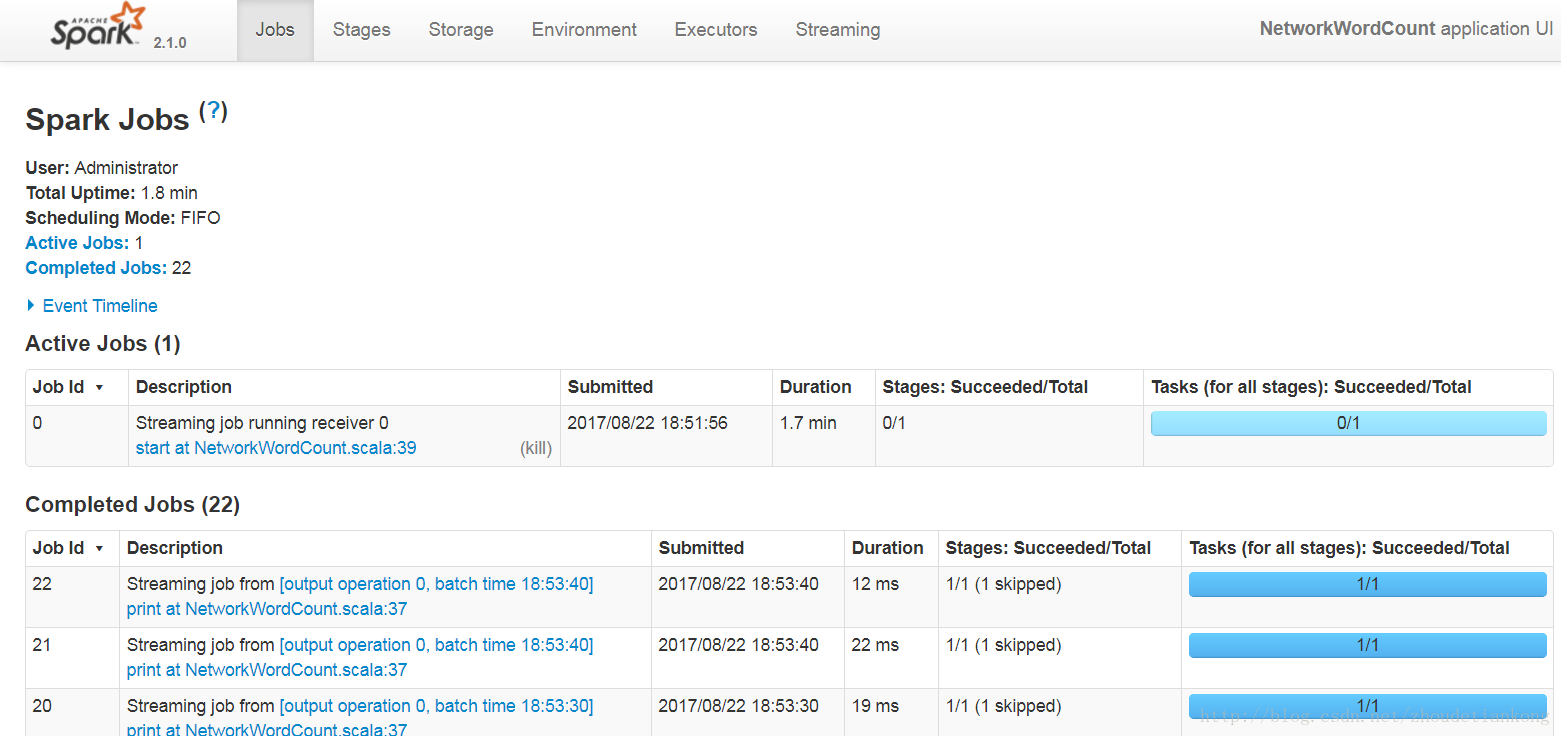
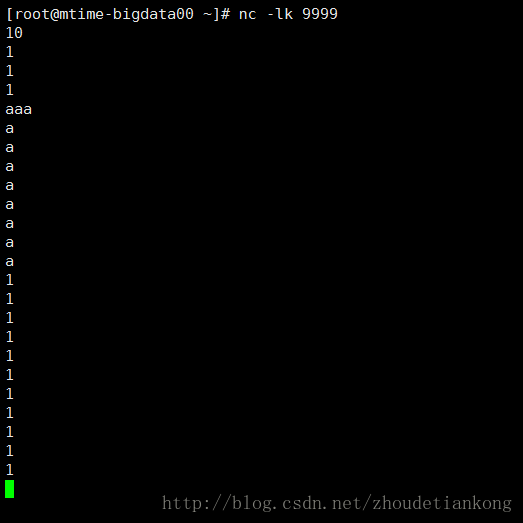

這個例子簡單來說呢,就是統計每10s內的單詞,然後計算這10s內的單詞個數並輸出。對於transformation以及output 的用法,可以自己查閱文件。
相關推薦
spark-streaming 程式設計(二) word count單詞計數統計
就那官方的例子來說明,程式碼基本上有註釋 package com.lgh.sparkstreaming import org.apache.spark.SparkConf import org.apache.spark.storage.StorageLe
【Spark核心原始碼】Word Count程式的簡單分析
目錄 啟動Spark Shell 日誌級別的設定 解析word count程式 第0步:設定日誌級別(“可選”) 第1步:讀取檔案 第2步:將每行的內容根據空格進行拆分成單詞 第3步:設定每一個單詞的計數為1 第4步:單詞根據Key進行計數值累加聚合 第5步:輸出
Spark Streaming(二十四)初識
定義 SparkStreaming是Spark核心API的擴充套件,類似與Apache Storm,但是它不是真正的是實時的,它是準實時的,也就是單位時間內做小批量的處理,它是可伸縮的、高可用的、容錯的
Scala +Spark+Hadoop+Zookeeper+IDEA實現WordCount單詞計數(簡單例項)
IDEA+Scala +Spark實現wordCount單詞計數 一、新建一個Scala的object單例物件,修改pom檔案 (1)下面文章可以幫助參考安裝 IDEA 和 新建一個Scala程式。 (2)pom檔案 <?xml
《Spark官方文件》Spark Streaming程式設計指南
spark-1.6.1 [原文地址] Spark Streaming程式設計指南 概覽 Spark Streaming是對核心Spark API的一個擴充套件,它能夠實現對實時資料流的流式處理,並具有很好的可擴充套件性、高吞吐量和容錯性。Spark Streaming支援從多種資料來源提取資
Spark Streaming(二十七)DStream的轉換、輸出、快取持久化、檢查點
定義 所謂DStream的轉換其實就是對間隔時間內DStream資料流的RDD進行轉換操作並返回去一個新的DStream。 DStream轉換 其實DStream轉換語法跟RDD的轉換語法非常類似,但DStream有它自己的一些特殊的語法,如updateStat
Spark2.1.0文件:Spark Streaming 程式設計指南(上)
本文翻譯自spark官方文件,僅翻譯了Scala API部分,目前版本為2.1.0,如有疏漏錯誤之處請多多指教。 原文地址:http://spark.apache.org/docs/latest/streaming-programming-guide.html 因文件篇幅較
spark-streaming 程式設計(三)連線kafka消費資料
spark-streaming支援kafka消費,有以下方式: 我實驗的版本是kafka0.10,試驗的是spark-streaming-kafka-0.8的接入方式。另外,spark-streaming-kafka-0.10的分支並沒有研究。 spar
Android範例程式設計二:查單詞
這一系列文章的目的是以單個需求為嚮導,十分鐘左右能完成的Android範例程式設計。 生活中避免不了要查單詞,自己寫一個也是很簡單的事情。效果如下: 本篇主要涉及了Android中的多執行緒以及一個開源庫JSOUP的使用。首先建立專案 在專案的在專案模組的build.gr
Spark Streaming程式設計指南(三)
DStreams轉換(Transformation) 和RDD類似,轉換中允許輸入DStream中的資料被修改。DStream支援很多Spark RDD上的轉換。常用的轉換如下。 轉換 含義 map(func) 將源DS
#########好####### pyspark-Spark Streaming程式設計指南
參考: 1、http://spark.apache.org/docs/latest/streaming-programming-guide.html 2、https://github.com/apache/spark/tree/v2.2.0 Spark Streami
Spark Streaming 程式設計入門指南
Spark Streaming 是核心Spark API的擴充套件,可實現實時資料流的可伸縮,高吞吐量,容錯流處理。可以從許多資料來源(例如Kafka,Flume,Kinesis或TCP sockets)中提取資料,並且可以使用複雜的演算法處理資料,這些演算法用高階函式表示,如map、reduce、join和
使用Spark Streaming SQL基於時間視窗進行資料統計
2.時間窗語法說明 Spark Streaming SQL支援兩類視窗操作:滾動視窗(TUMBLING)和滑動視窗(HOPPING)。 2.1滾動視窗 滾動視窗(TUMBLING)根據每條資料的時間欄位將資料分配到一個指定大小的視窗中進行操作,視窗以視窗大小為步長進行滑動,視窗之間不會出現重疊。
Spark Streaming和Flink的Word Count對比
準備: nccat for windows/linux 都可以 通過 TCP 套接字連線,從流資料中建立了一個 Spark DStream/ Flink DataSream, 然後進行處理, 時間視窗大小為10s 因為 示例需要, 所以 需要下載一個netcat, 來構造
Spark Streaming從Kafka中獲取數據,並進行實時單詞統計,統計URL出現的次數
scrip 發送消息 rip mark 3.2 umt 過程 bject ttr 1、創建Maven項目 創建的過程參考:http://blog.csdn.net/tototuzuoquan/article/details/74571374 2、啟動Kafka A:安裝ka
【慕課網實戰】Spark Streaming實時流處理項目實戰筆記二十之銘文升級版
.get frame 結果 取數據 lena echarts object 原理 四種 銘文一級: Spring Boot整合Echarts動態獲取HBase的數據1) 動態的傳遞進去當天的時間 a) 在代碼中寫死 b) 讓你查詢昨天的、前天的咋辦? 在頁面中放一個時間插
【慕課網實戰】Spark Streaming實時流處理項目實戰筆記二十一之銘文升級版
win7 小時 其他 har safari 北京 web 連接 rim 銘文一級: DataV功能說明1)點擊量分省排名/運營商訪問占比 Spark SQL項目實戰課程: 通過IP就能解析到省份、城市、運營商 2)瀏覽器訪問占比/操作系統占比 Hadoop項目:userAg
spark配置和word-count
pack lib tuple www. sch creat java clust name Spark ------------ 快如閃電集群計算引擎。 應用於大規模數據處理快速通用引擎。 內存計算。 [Speed] 計
Kafka:ZK+Kafka+Spark Streaming集群環境搭建(二)VMW安裝四臺CentOS,並實現本機與它們能交互,虛擬機內部實現可以上網。
centos 失敗 sco pan html top n 而且 div href Centos7出現異常:Failed to start LSB: Bring up/down networking. 按照《Kafka:ZK+Kafka+Spark Streaming集群環
Kafka:ZK+Kafka+Spark Streaming集群環境搭建(二十三)Structured Streaming遇到問題:Set(TopicName-0) are gone. Some data may have been missed
ack loss set div top 過程 pan check use 事情經過:之前該topic(M_A)已經存在,而且正常消費了一段時間,後來刪除了topic(M_A),重新創建了topic(M-B),程序使用新創建的topic(M-B)進行實時統計操作,執行過程中